Robotics URJC
Personal webpage for TFM Students.
View the Project on GitHub RoboticsLabURJC/2017-tfm-vanessa-fernandez
Week 21: Driving videos, Stacked network
Driving videos
Stacked network
I’ve used the predictions of the stacked (pilotnet with stacked frames) network (regression network) to driving a formula 1:
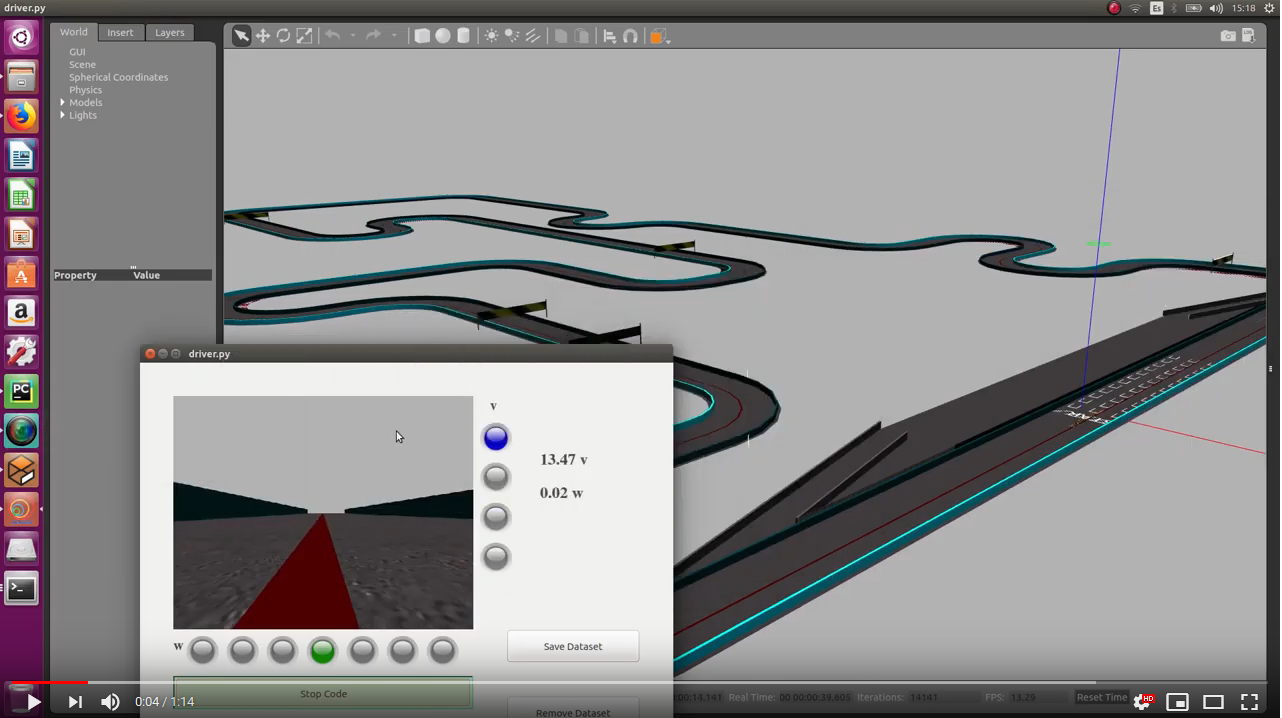
I’ve used the predictions of the stacked (pilotnet with stacked frames) network (regression network) for w and constant v to driving a formula 1:
Pilotnet network
I’ve used the predictions of the pilotnet network (regression network) to driving a formula 1 (test2):
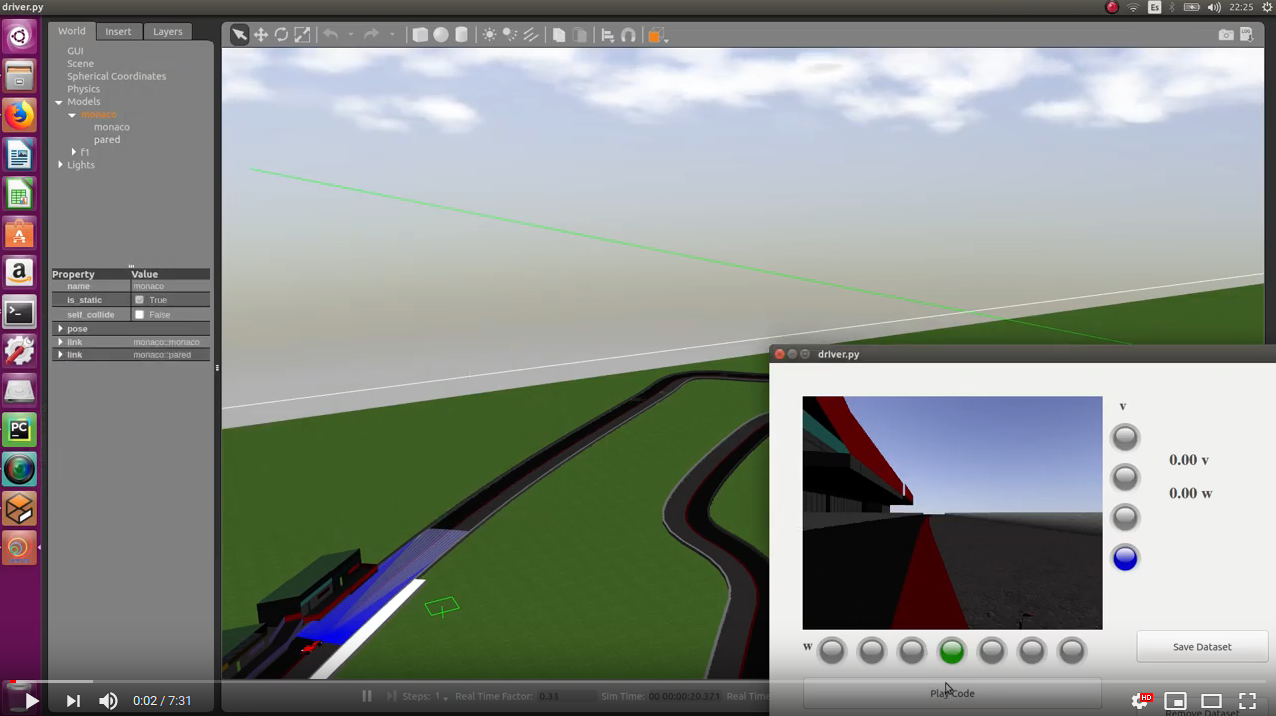
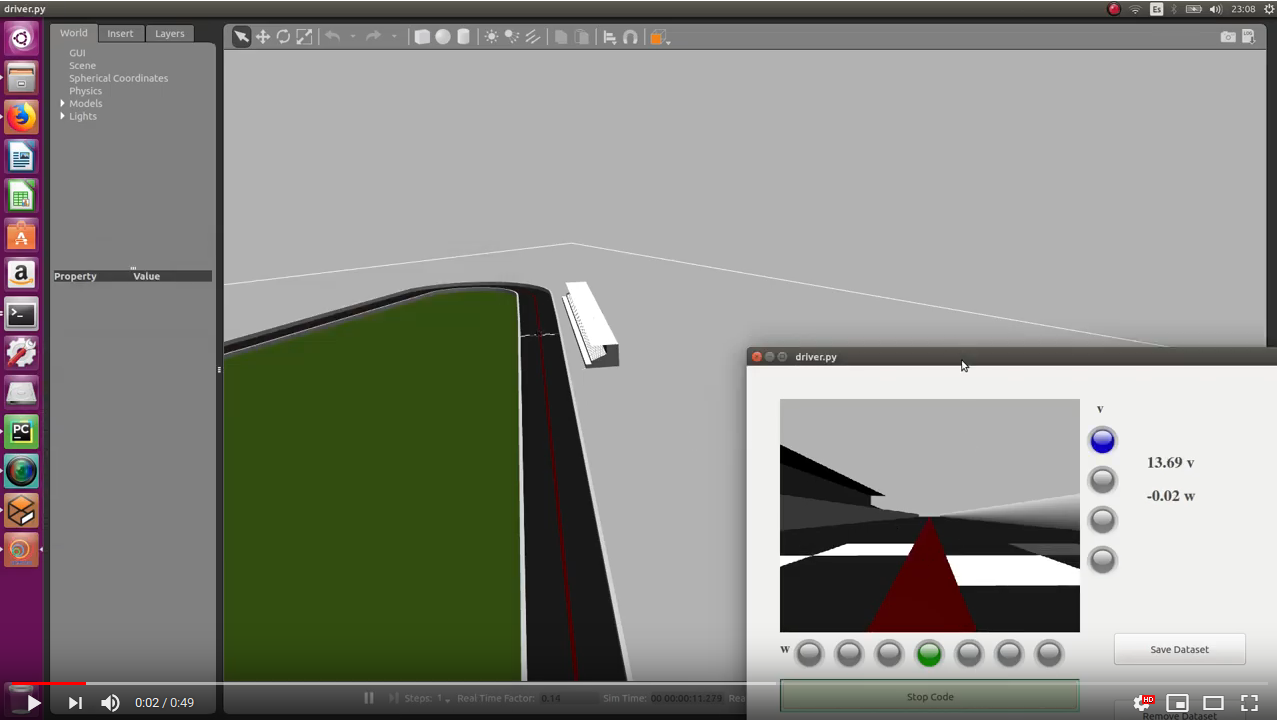
In the following video complete one lap (simulation time: 1 min 26s):
I’ve used the predictions of the pilotnet network (regression network) for w and constant v to driving a formula 1:
Biased classification network
I’ve used the predictions of the classification network according to w (7 classes) and constant v to driving a formula 1:
Stacked network
In this method (stacked frames), we concatenate multiple subsequent input images to create a stacked image. Then, we feed this stacked image to the network as a single input. We refer to this method as stacked. This means that for image it at time/frame t, images it−1, it−2, … will be concatenated. In our case, we have stacked 3 images separated by 2 frames. This means that for image it at time / frame t we concatenate the image t, t-3 and t-6.