Robotics URJC
Personal webpage for TFM Students.
View the Project on GitHub RoboticsLabURJC/2017-tfm-vanessa-fernandez
Week 5, 6: First steps with Follow Line
Reading some information about autonomous driving
These weeks, I’ve read the article “Self-Driving a Car in simulation through a CNN” and a tfg on which this article was based. This paper researches into Convolutional Neural Networks and its architecture, to develop a new CNN with the capacity to control lateral and longitudinal movements of a vehicle in an open-source driving simulator (Udacity’s Self-Driving Car Simulator) replicating the human driving behavior.
Training data is collected by driving the simulator car manually (using the Logitech Force Pro steering wheel), obtaining images from a front-facing camera and synchronizing steering angle and throttle values performed by the driver. The dataset is augmented by horizontal flipping, changing steering angles sign and taking information from left and right cameras from the car. The simulator provides a file (drive.py) in charge of establishing the communication between the vehicle and the neural network, so that the network receives the image captured by the camera and returns an acceleration value and a rotation angle.
The CNNs tested in this project are described, trained and tested using Keras. The CNNs tested are:
-
TinyPilotNet: developed as a reduction from NVIDIA PilotNet CNN used for self-driving a Car. TinyPilotNet network is composed by a 16x32x1 pixels image input (image has a single channel formed by saturation channel from HSV color space), followed by two convolutional layers, a dropout layer and a flatten layer. The output of this architecture is formed by two fully connected layers that leads into a couple of neurons, each one of them dedicated to predict steering and throttle values respectively.
-
DeeperLSTM-TinyPilotNet: formed by more layers and higher input resolution.
-
DeepestLSTM-TinyPilotNet: formed by three 3x3 kernel convolution layers, combined with maxpooling layers, followed by three 5x5 convolutional LSTM layers and two fully connected layers.
-
Long Short-Term Memory (LSTM) layers are included to TinyPilotNet architecture with the aim of improving the CNN driving performance and predict new values influenced by previous ones, and not just from the current input image. These layers are located at the end of the network, previous to the fully-connected layers. During the training, the dataset is used sequentially, not shuffled.
The training data is an essential part for a correct performance by the convolutional neuronal network. However, extracting an important amount of data is a great difficulty. The data augmentation allows you to modify or increase the training information of the network from a data bank previously obtained so that the CNN more easily understand what data to extract to obtain the expected results. The training data treatment effects carried out in the study are:
-
RGB image: The input image of the network is modified, which previously it was an image that took only the saturation of the HSV color space, by an image of 3 RGB color channels. To be implemented in a CNN, it is simply necessary to modify the first layer of the network.
-
Increase in resolution: it supposes a modification of the input layer’s dimension.
-
Image cropping: consists of extracting a specific area from the image in which considers that the information relevant to CNN is concentrated. The image that CNN will analyze it only contains information about the road, eliminating the landscape part of the frame.
-
Edge detector filter: consists of extracting the edges of the input image to highlight them on the original image. This is achieved by using a Canny filter.
In order to compare the performance of the CNN with other networks, a frame-to-frame comparison is made between CNN steering angle and throttle values and human values as ground truth. The metric mean square error (RMSE) is used, obtained with the difference between the CNN address and the accelerator predicted values and given humans. Driving data collected by a human driver is needed to compare the CNN given values for each frame with the values used by the human driver. This parameter does not evaluate the ability of the network to use previous steering and throttle values to predict the new ones, so the LSTM layer does not make effect and appears underrated in comparison with other CNNs that do not use these kind of layers.
To solve this problem, new quality parameters have been proposed to quantify the performance of the network driving the vehicle. These parameters are measured with the information extracted from the simulator when the network is being tested. To calculate these parameters, center points of the road -named as waypoints- are needed, separated 2 meters. These new metrics are:
-
Center of road deviation: One of these parameters is the shifting from the center of the road, or center of road deviation. The lower this parameter is, the better the performance will be, because the car will drive in the center of the road instead of driving in the limits. To calculate deviation, nearest waypoint is needed to calculate distance between vehicle and segment bounded by that waypoint and previous or next.
-
Heading angle: the lower this parameter, the better the performance will be, because lower heading angle means softer driving, knowing better the direction to follow.
To train the network, a data collection is carried out by manual driving in the simulator, traveling several laps in the circuit to obtain a large volume of information. This information will contain recordings of images of the dashboard collected by a central camera and two lateral ones located on both sides of the vehicle at 14 FPS, in addition to data of steering wheel angle, acceleration, brake and absolute speed linked to images. All CNNs have been trained using the left, center and right images of the vehicle by applying a 5° offset to the steering angle. In addition, the training dataset has been increased by performing a horizontal image flip (mirroring) to the images, also inverting the steering wheel angle value, but maintaining the acceleration value.
In order to determine the performance of the CNNs using the metrics previously established, different experiments are made. It experiments with different CNN for steering wheel control:
-
Steering wheel control with a CNN: The results of these modifications are analyzed on the control of the angle of rotation of the steering wheel, setting an acceleration of 5% that makes the vehicle circulate at its speed maximum on the circuit. The following networks are analyzed: TinyPilotNet (16x32 pixel input image), Higher resolution TinyPilotNet (20x40 pixel input image), HD-TinyPilotNet (64x128 pixel input image), RGB-TinyPilotNet (3-channel input image), LSTM-TinyPilotNet (LSTM layers are added at the exit to the network), DeeperLSTM-TinyPilotNet (combines the effects of the LSTM network and the higher resolution network, increasing the size of the input image up to 20x40 pixels), Cropping-DeeperLSTM-TinyPilotNet (is similar to the DeeperLSTM-TinyPilotNet network developed above, but the image cropping effect is applied to its input), Edge-DeeperLSTM-TinyPilotNet (an edge detection is made and a sum type fusion is made, highlighting the edges in the image). It is observed that the only network that improves the RMSE is the TinyPilotNet with higher resolution. However, visually in the simulator it is seen that driving is much better through CNNs containing LSTM layers. The use of RGB-TinyPilotNet, as well as HD-TinyPilotNet, is discarded, as these networks aren’t able to guide the vehicle without leaving the road. Following the criterion of improving the average error with respect to the center of the lane for the rest of the networks, the order of performance from best to worst is the following: 1.DeeperLSTM-TinyPilotNet, 2.Cropping-DeeperLSTM-TinyPilotNet, 3.TinyPilotNet, 4.LSTM-TinyPilotNet, 5.Higher resolution TinyPilotNet, 6.Edge-DeeperLSTM-TinyPilotNet. Based on the pitch angle, once the RGB network has been discarded, the order of the different networks ordered from best to worst performance is as follows: 1.Higher resolution TinyPilotNet, 2.DeeperLSTM-TinyPilotNet, 3.Edge-DeeperLSTM-TinyPilotNet, 4.LSTM-TinyPilotNet, 5.Cropping-DeeperLSTM-TinyPilotNet, 6.TinyPilotNet.
-
Control of steering wheel angle and acceleration through CNNs disconnected: the angle of the steering wheel and the acceleration of the vehicle at each moment are controlled simultaneously. For this, two convolutional neuronal networks will be configured, each specialized in a type of displacement. Based on the results obtained in the steering wheel control, it test the following networks: TinyPilotNet, Higher resolution TinyPilotNet, DeeperLSTM-TinyPilotNet, Edge-DeeperLSTM-TinyPilotNet. The only network that improves this the RMSE is the Higher resolution TinyPilotNet. Networks that include LSTM layers aren’t able to keep the vehicle inside the circuit. Higher resolution TinyPilotNet equals TinyPilotNet with respect to the deviation from the lane center. None of the trained CNNs is capable of improving the pitch factor of the simple network. In conclusion, the training of separate networks to control longitudinal and lateral displacement is not a reliable method.
-
Control of the angle of the steering wheel and acceleration through the same CNN: it proposes to control the vehicle through a single convolutional neural network, so that it has two outputs, which stores the values of angle and acceleration. For this, it is necessary to modify the architecture of the previously used networks slightly, changing the output neuron for a pair of neurons. The networks trained following this method are the following: TinyPilotNet, Higher resolution TinyPilotNet, DeeperLSTM-TinyPilotNet, Edge-DeeperLSTM-TinyPilotNet, DeepestLSTM-TinyPilotNet, Edge-DeepestLSTM-TinyPilotNet. The only network that improves this the RMSE is the Higher resolution TinyPilotNet. The networks TinyPilotNet, DeeperLSTM-TinyPilotNet and the trained with detection of edges aren’t able to keep the vehicle on the road. Following the criterion of the improvement of the average error with respect to the center of the lane for the rest of the networks, the order of performance from best to worst is the following: 1.DeepestLSTM-TinyPilotNet, 2.Higher resolution TinyPilotNet. The only networks that improve the average pitch parameter of the network TinyPilotNet are the ones that include a greater number of layers. The DeepestLSTM-TinyPilotNet network improves up to 36% pitch, producing a smoother and more natural circulation without applying edge detection to the information. The use of a network with LSTM layers and a greater number of configurable parameters produces a more natural driving, with less pitch and minor deviation. However, the fact of controlling the steering wheel and accelerator make the results slightly worse than those obtained in the case of steering wheel control exclusively.
In conclusion:
-
A slight increase in the resolution of the input image produces notable improvements in both quality factors without assuming a significant increase in the size of the network or the processing time.
-
The inclusion of Long Short-Term Memory (LSTM) layers in the output of a convolutional neural network provides an influence of the values previously contributed by it, which leads to a smoother conduction.
-
The use of the RGB color input image instead of using only the saturation of the HSV color space results in a lesser understanding of the environment by CNN, which leads to bad driving. When using the saturation channel, the road remains highlighted in black, while the exterior of this one obtains lighter colors, producing a simple distinction of the circuit.
-
The information about acceleration doesn’t produce better control of the steering angle.
-
To obtain evaluation metric values similar to those obtained by a CNN that only controls the steering wheel on a CNN that controls steering wheel and accelerator is necessary increase the depth of the network.
-
The greater definition of edges in the input image through the Canny filter doesn’t produce significant improvement.
-
Make a cropping in the input image to extract only the information from the road doesn’t improve driving.
Creation of the synthetic dataset
I have created a synthetic dataset. To create this dataset I have created a background image and I have created a code that allows you to modify this background and add a road line. This code allows to generate a dataset of 200 images with lines at different angles. The angle of each road in each image has been saved in a txt file. Next, we can see an example of the images.
Background:

Image:

Getting started with Neural Network for regression
Also, I’ve started to study Neural Network for regression. A regression model allows us to predict a continuous value based on data that it already know. I’ve followed a tutorial that creates a model of neural networks for regression on financial data. The code can be found at Github. Next, the code is explained:
At the beginning, we preprocess the data and leave 60% of data for training and 40% for test.
We built our neural net model:
-
tf.Variable will create a variable of which value will be changing during optimization steps.
-
tf.random_uniform will generate random number of uniform distribution of dimension specified ([input_dim,number_of_nodes_in_layer]).
-
tf.zeros will create zeros of dimension specified (vector of (1,number_of_hidden_node)).
-
tf.add() will add two parameters.
-
tf.matmul() will multiply two matrices (Weight matrix and input data matrix).
-
tf.nn.relu() is an activation function that after multiplication and addition of weights and biases we apply activation function.
-
tf.placeholder() will define gateway for data to graph.
-
tf.reduce_mean() and tf.square() are function for mean and square in mathematics.
-
tf.train.GradientDescentOptimizer() is class for applying gradient decent.
-
GradientDescentOptimizer() has method minimize() to mimize target function/cost function.
We will train neural network by iterating it through each sample in dataset. Two for loops used one for epochs and other for iteration of each data. Completion of outer for loop will signify that an epoch is completed.
-
tf.Session() initiate current session.
-
sess.run() is function that run elements in graph.
-
tf.global_variables_initializer() will initialize all variables.
-
tf.train.Saver() class will help us to save our model.
-
sess.run([cost,train],feed_dict={xs:X_train[j,:], ys:y_train[j]}) this actually running cost and train step with data feeding to neural network one sample at a time.
-
sess.run(output,feed_dict={xs: X_train}) this running neural network feeding with only test features from dataset.
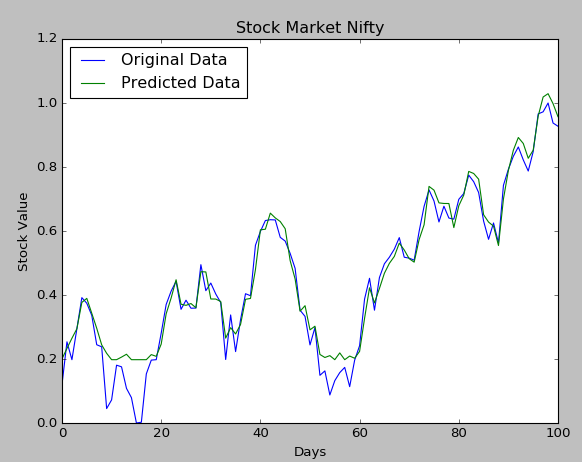
So finally we completed our neural net in Tensorflow for predicting stock market price. The result can be seen in the following graph: