Robotics URJC
Personal webpage for TFM Students.
View the Project on GitHub RoboticsLabURJC/2017-tfm-vanessa-fernandez
Week 9: Improving driver node, classification network, and driver test
Driver node
The driver node has been modified to make an inference per cycle. To do this, the threadNetwork.py file and the classification_network.py file have been created. threadNetwork allows you to make a prediction per cycle by calling the predict method of the class ClassificationNetwork (classification_network.py).
Classification network
A file (add_classification_data.py) has been created to modify the data.json file and add the left/right classification. If the data w is positive then the classification will be left, while if w is negative the classification will be right.
Once the dataset is complete, a file has been created to divide the data into train and test. It has been decided to divide the dataset by 70% for train and 30% for test. Since the dataset was 5006 pairs of values, we now have 3504 pairs of train values and 1502 pairs of test values. The train data is in 1, and test is in 2.
The classification_train.py file has been created that allows training a classification network. This classification network aims to differentiate between left and right. In this file before training we eliminate the pairs of values where the angle is close to 0 (with margin 0.08), because they will not be very significant data. In addition, we divide the train set by 80% for train and 20% for validation.
In our case we will use a very small convnet with few layers and few filters per layer, alongside dropout. Dropout also helps reduce overfitting, by preventing a layer from seeing twice the exact same pattern. Our model have a simple stack of 3 convolution layers with a ReLU activation and followed by max-pooling layers. This is very similar to the architectures that Yann LeCun advocated in the 1990s for image classification (with the exception of ReLU). On top of it we stick two fully-connected layers. We end the model with a single unit and a sigmoid activation, which is perfect for a binary classification. To go with it we will also use the binary_crossentropy loss to train our model. The model (classification_model.py) is as follows:
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# The model so far outputs 3D feature maps (height, width, features)
model.add(Flatten()) # This converts our 3D feature maps to 1D feature vectors
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
After training the network, we save the model (models/model_classification.h5) and evaluate the model with the validation set:
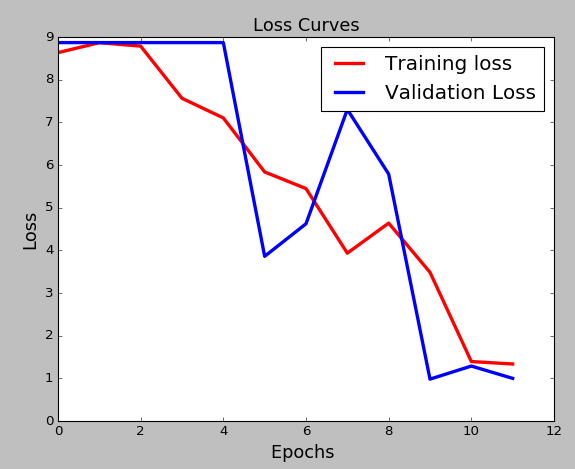
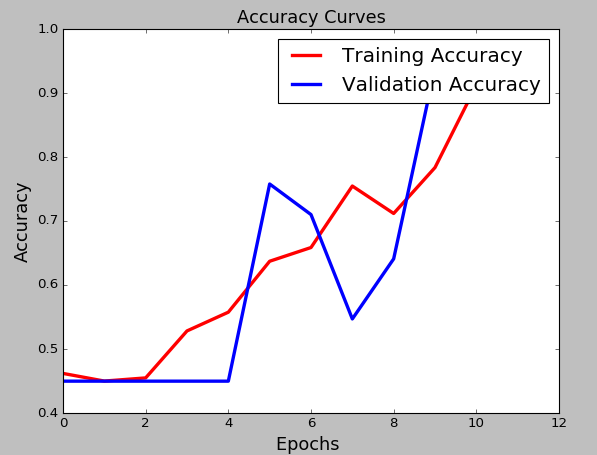
We also show the graphs of loss and accuracy for training and validation according to the epochs:
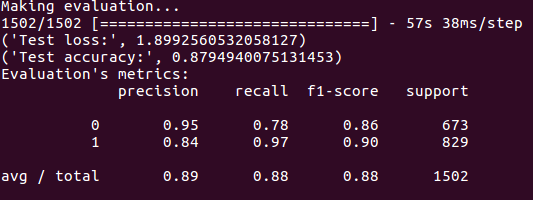
In addition, the classification_test.py file has been created to evaluate the model in a data set that has not been seen by the network. In this file the test set is used and accuracy, precision, recall, F1-score are evaluated and the confusion matrix is painted. The results are the following:

Driver test
I’ve tried to go around the circuit with formula 1 based on the predictions of left or right. To do this, a prediction is made in each iteration that will tell us right or left. If the prediction is right we give a negative angular speed and if it is left it will be positive. At all times we leave a constant linear speed. The result is not good, as the car hits a curve.