More experiments adding classification and extreme sequence data for LSTM models
New experiments this week.
Experiments:
- Results for classification brain with extreme data
- Comparison of best brains for each architecture
- Adding extreme sequences to LSTM based architectures
1. Results for classification brain with extreme data
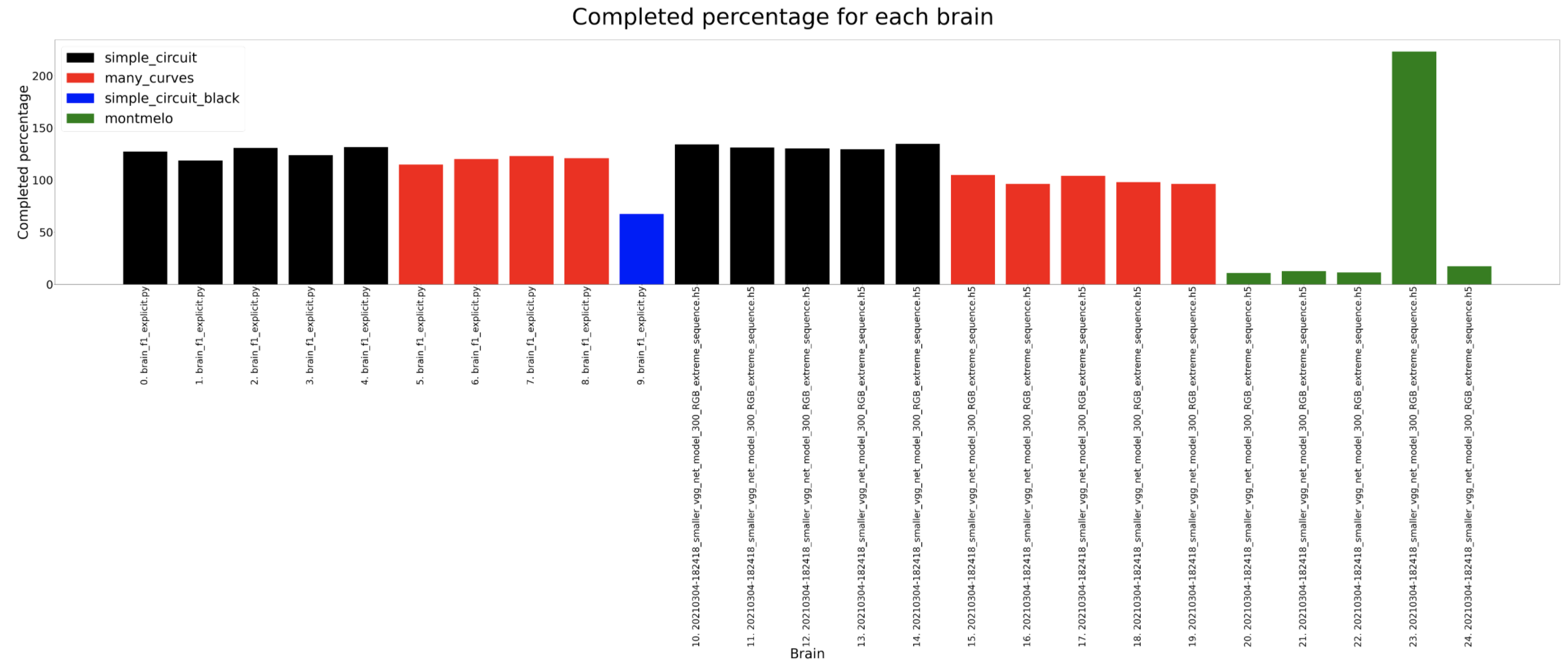
Adding more diversity to the brains that we have used, we add a classification brain. Its architecture is based on a Smaller VGG network that is trained with the same dataset as the rest of the regression based architectures. For this new scenario, the different values in the dataset are classified in different categories. 4 categories for the V and 7 for the W. Additionally, extreme data is added taking into consideration for this purpose the extreme cases of W, radically_left turns of radically_right turns, replicating them in the dataset generating a bias towards those values which are scarce. The results show that this brain is able to complete the different circuits in more or less the same time and interpreting the differences in time to the classification schema chosen.
Click on the images to expand them.
Completed distance
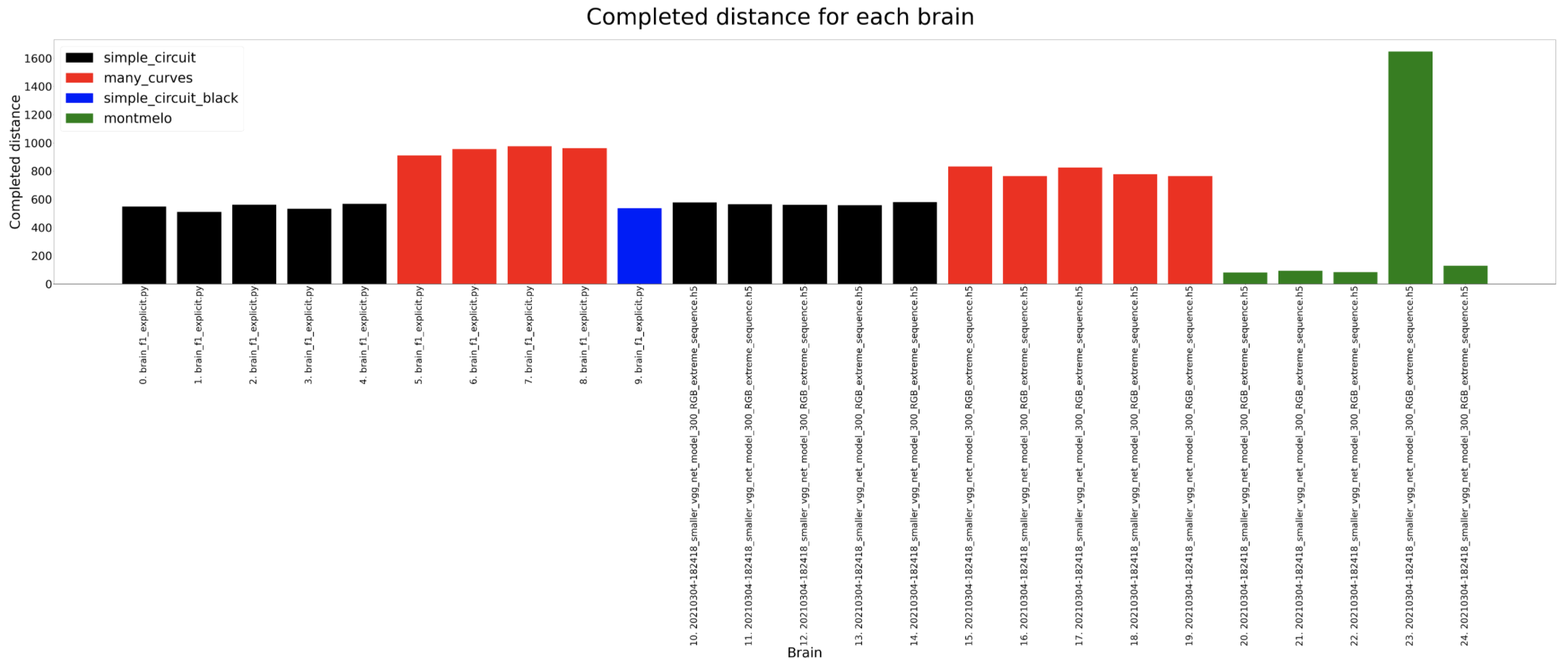
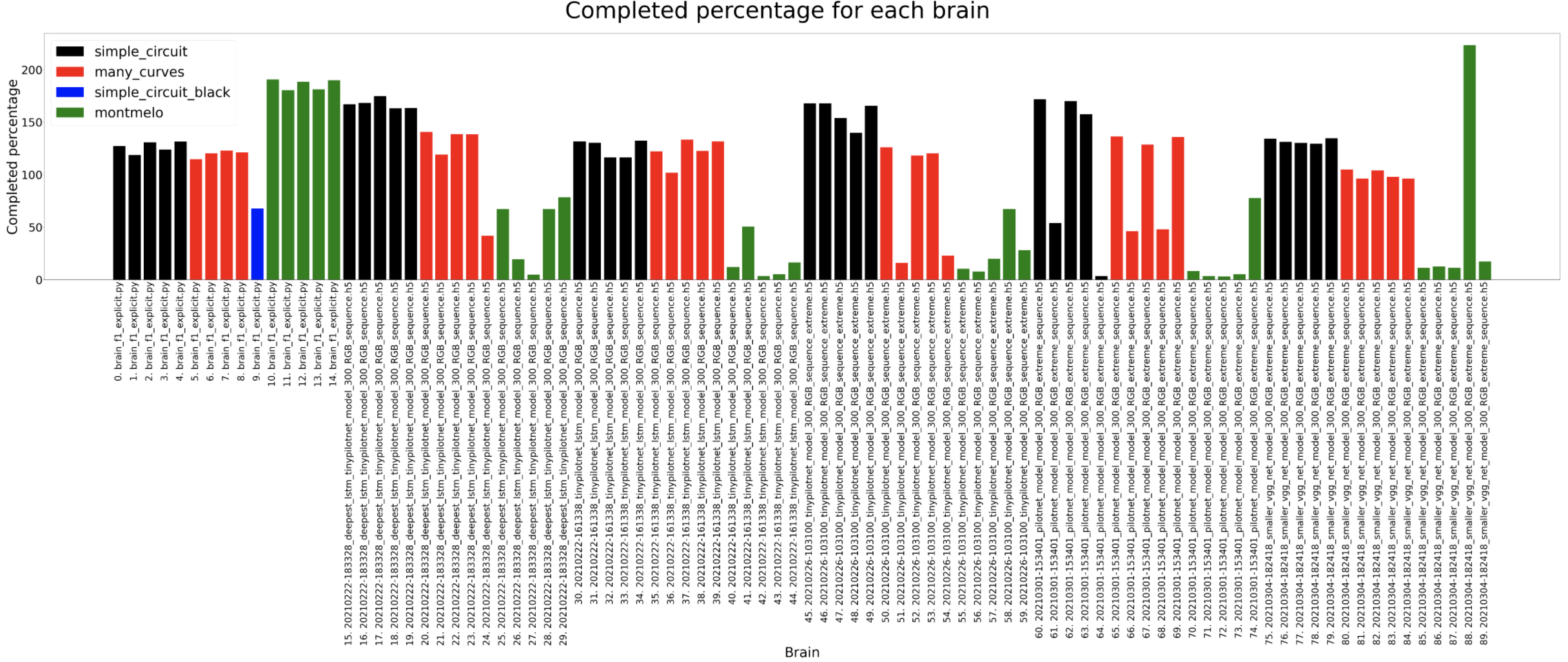
Completed percentage
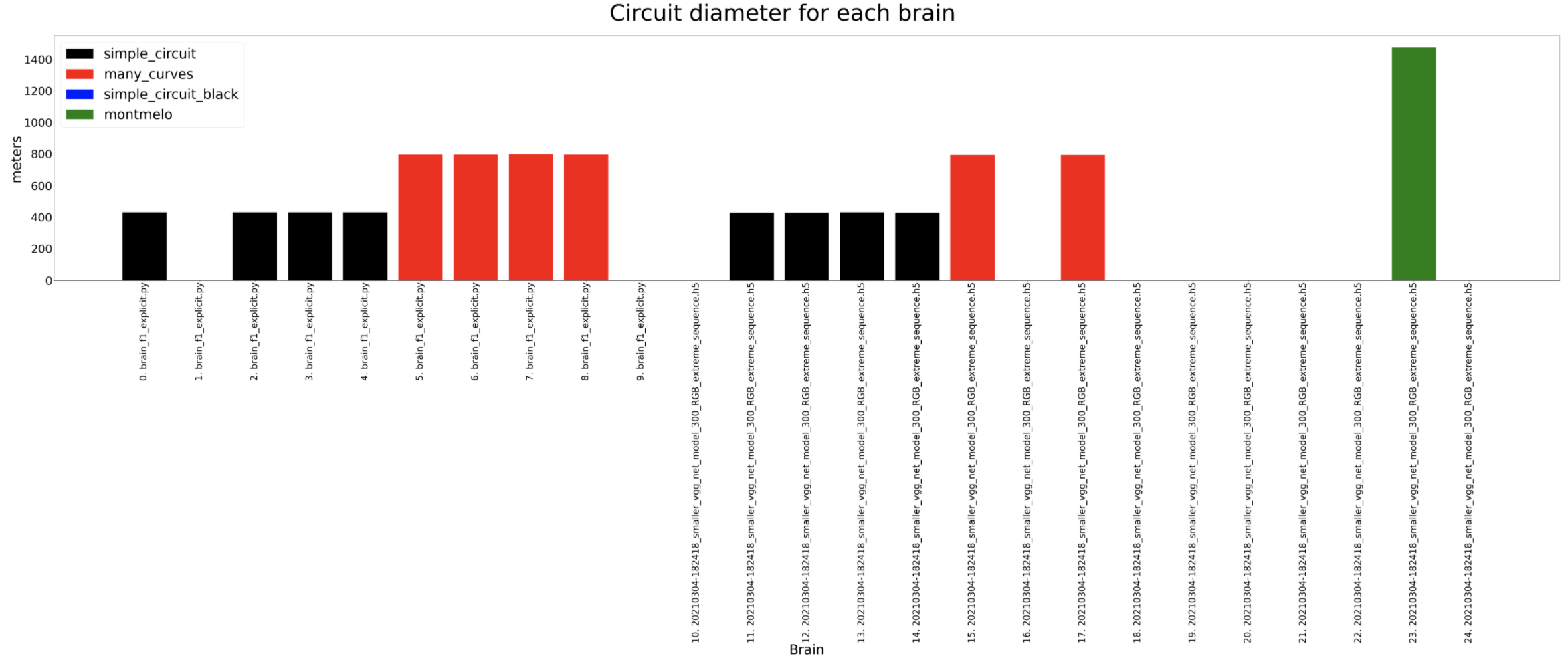
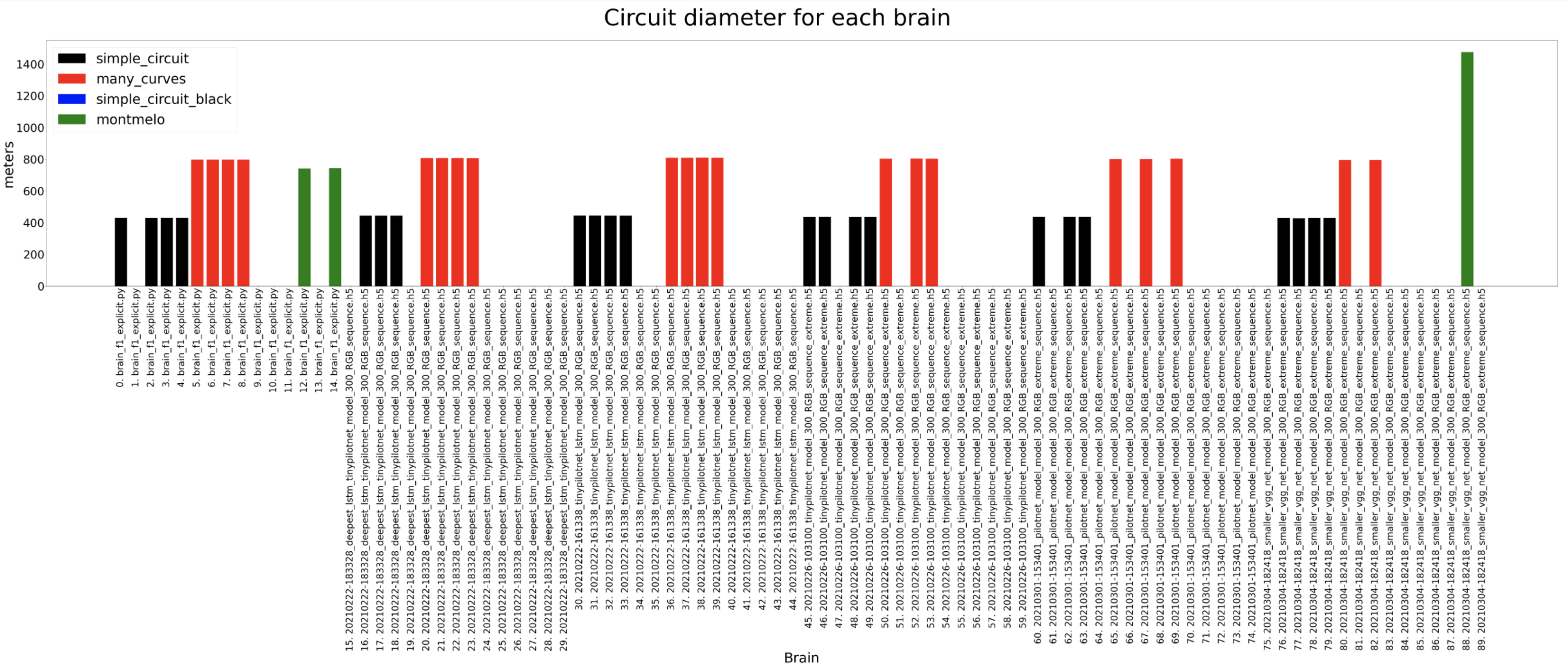
Circuit diameter
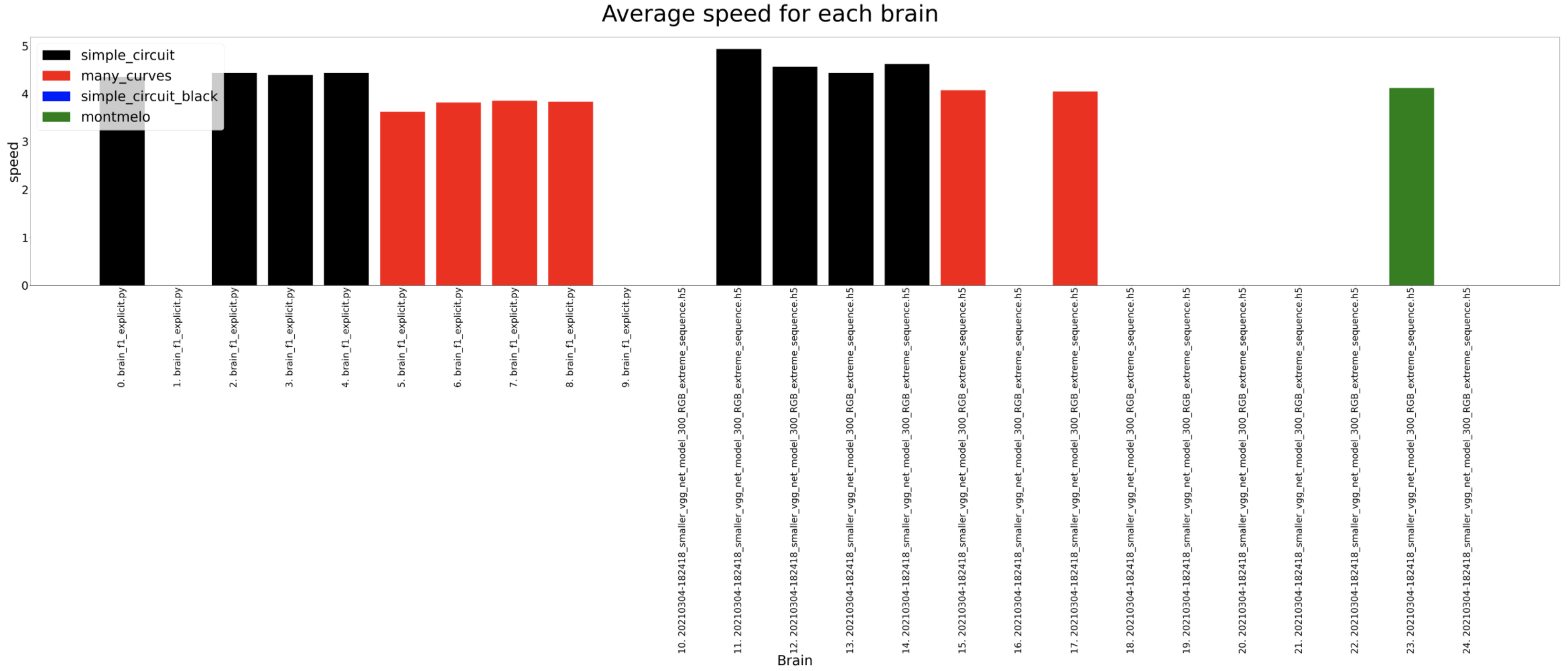
Average speed
Lap seconds
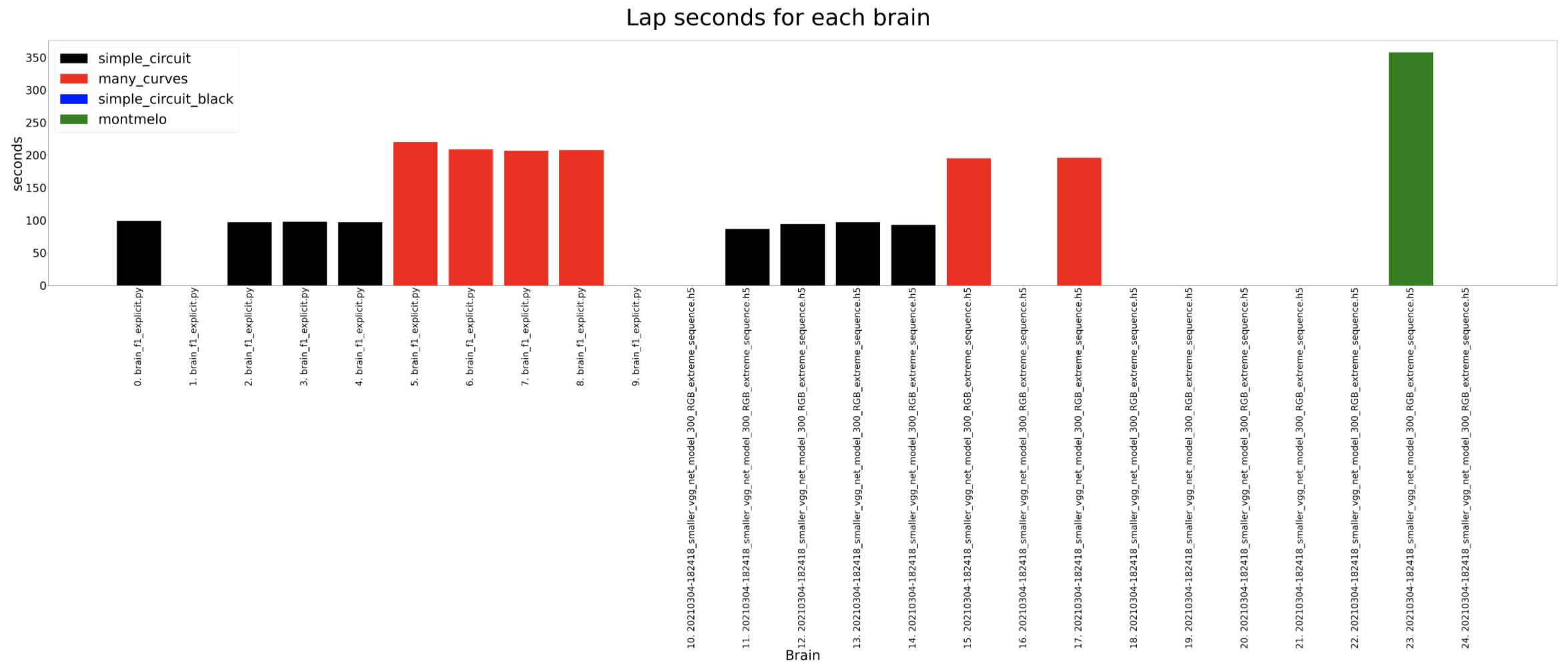
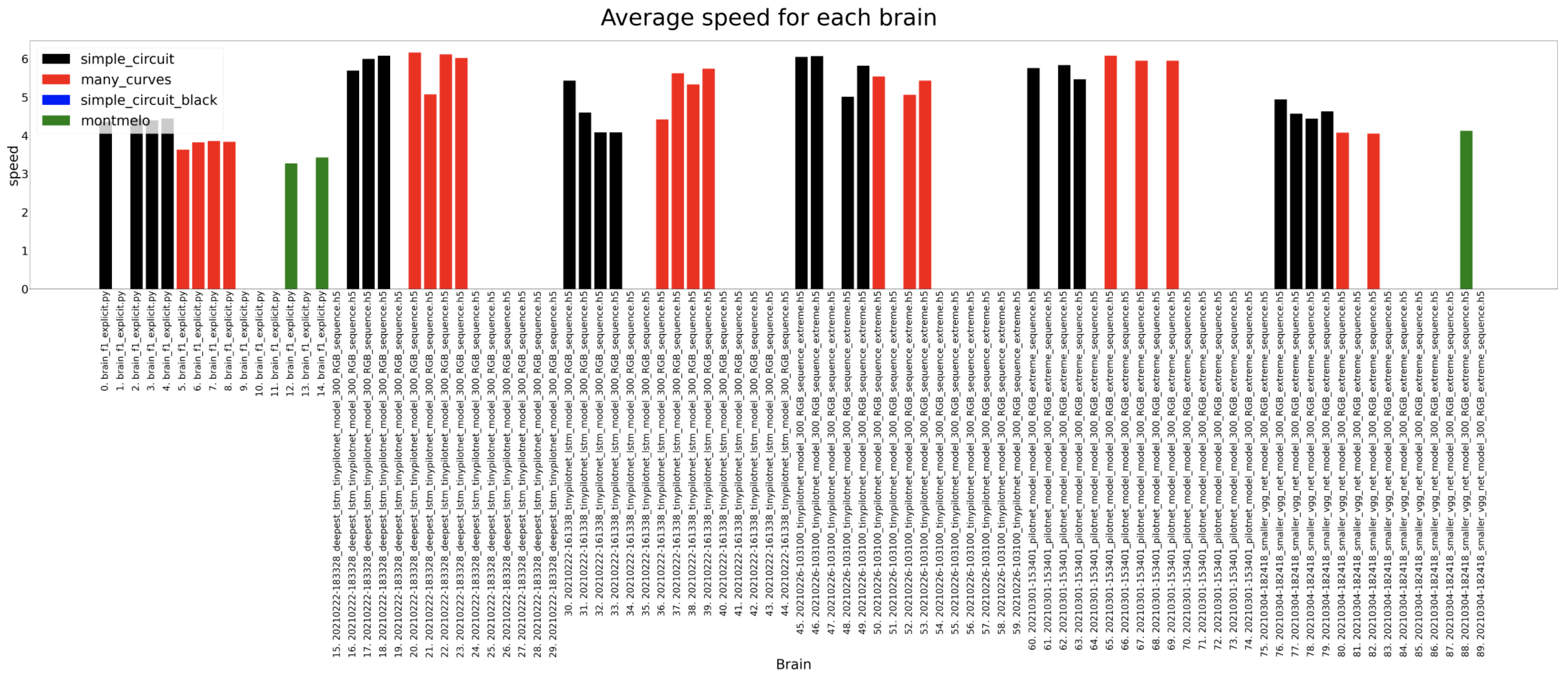
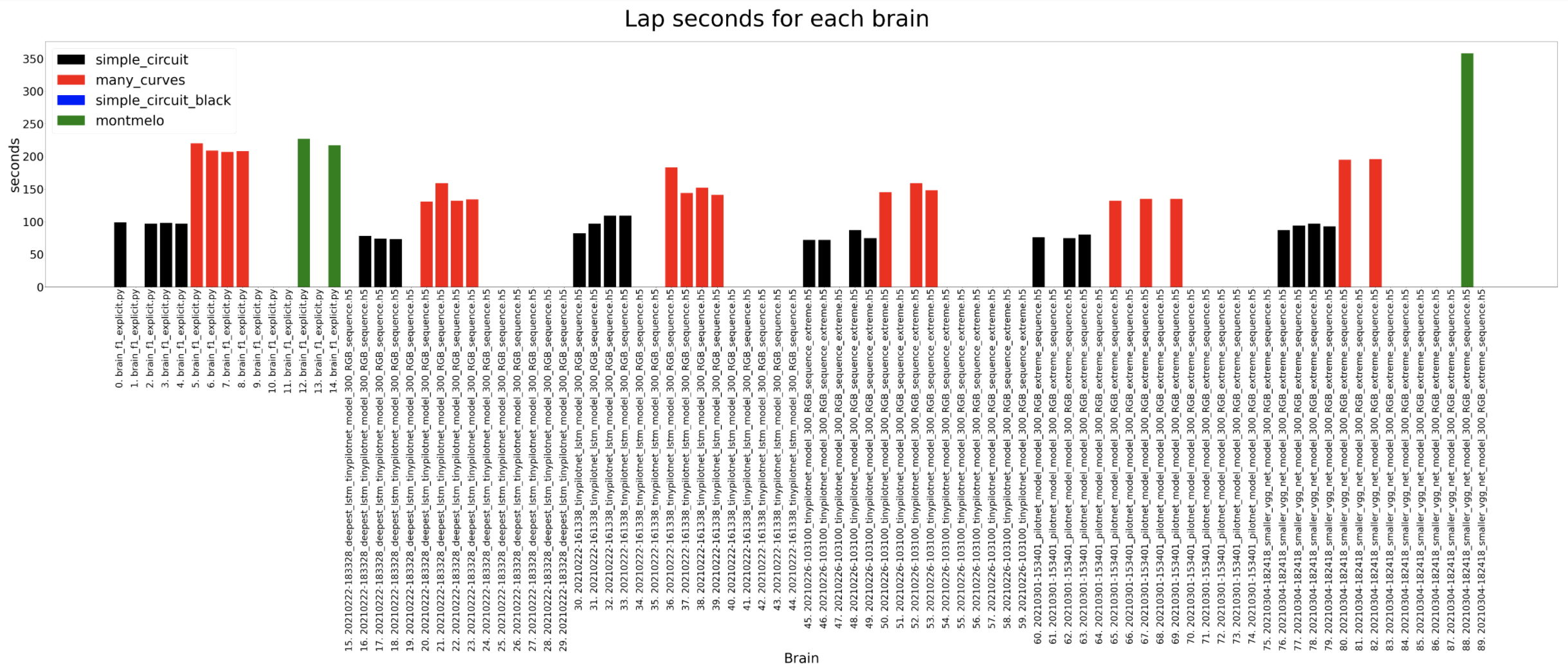
2. Comparison of best brains for each architecture
Complete comparison until now of the best trained models for each architecture. The brains generally can complete the different circuits except for the Montmelo one. The only one that manages to complete a full lap in Montmelo is the classification brain.
Completed distance
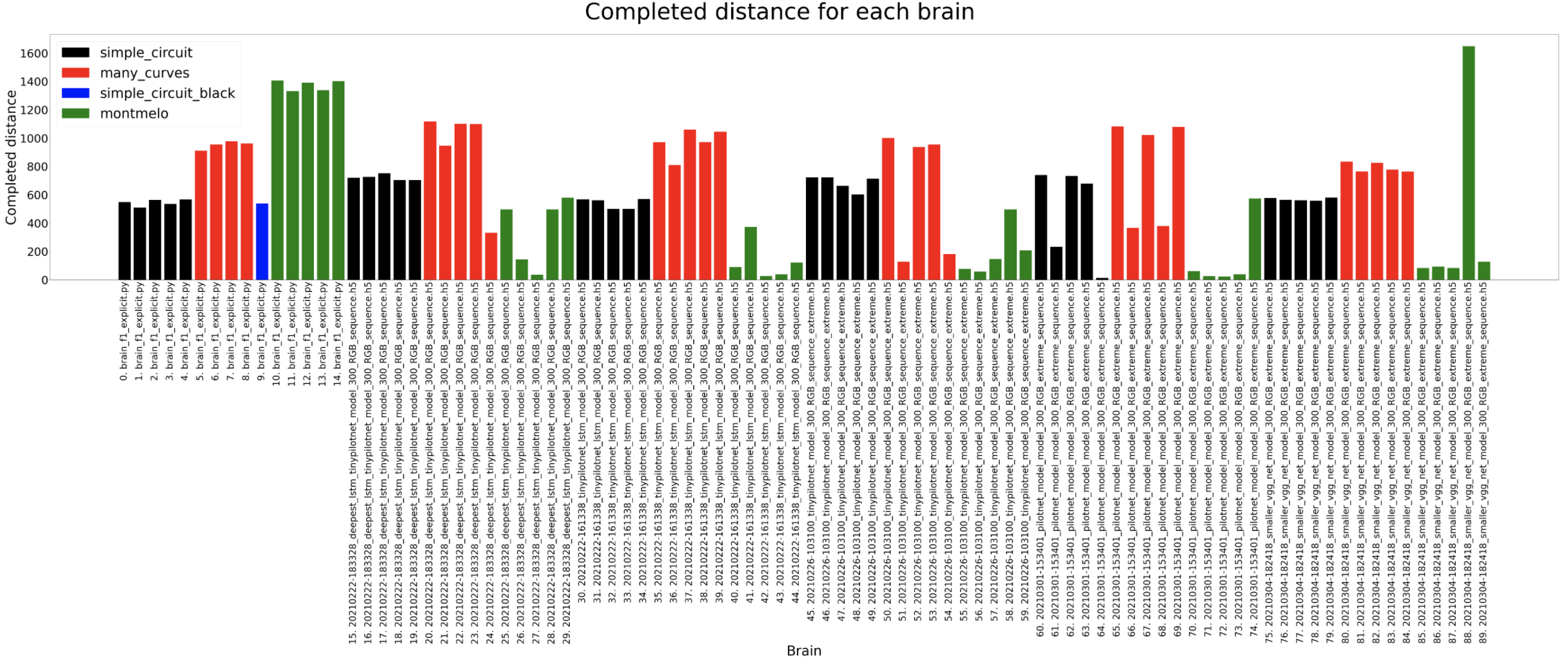
Completed percentage
Circuit diameter
Average speed
Lap seconds
3. Adding extreme sequences to LSTM based architectures
We already trained the CNN based architectures with extreme data in the previous week and discovered that it made the models improve by a great amount, so in this new experiment, we try adding extreme sequences to the LSTM based architectures to understand if it improves them.
3 ways of data augmentation are explored, but none improves the networks in the only scenario where they have issues, the Montmeló circuit. These experiments with data augmentation are:
- Add extreme sequences twice.
- Remove moderate sequences.
- Remove moderate sequences and add extreme sequences twice.
None of them where successful.