MountainCar openAI Gym exercise revisited after reading sutton section 1
After reading the section I of sutton reinforcement learning book, the previous implementation of the proposed openAIGym exercise “mountainCar” has been reviewed.
This revision consisted of:
- Updating the reward function so it is simpler and alligned with theoretical basics of reinforcement learning.
- Playing with the initialization of the q_table used in the q_learning algorithm.
- Last and least, the hyperparameters has been slightly modified to analyse their affection to the results.
you can find all the iterations tested in the results uploaded in the repository.
In there you will notice that there is not need to give plenty of information to the agent through the reward function (and indeed it could be counterproductive), but you can distribute the reward along the way to speed the learning. That said, to get a good result is enough to simply set the problem as a typical continuous task (giving a litle reward when the car achieves a new high) or as a typical episodic task (e.g reward of 0 for every action but the one that achieves the goal which reward is 1 or giving a reward of -1 for every action but the one that achieves the goal which reward is 0) both of them being discounted over the times.
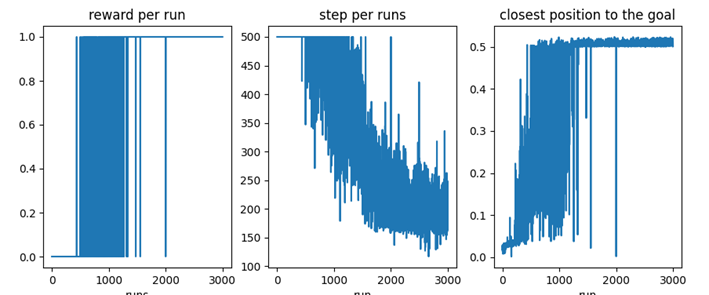
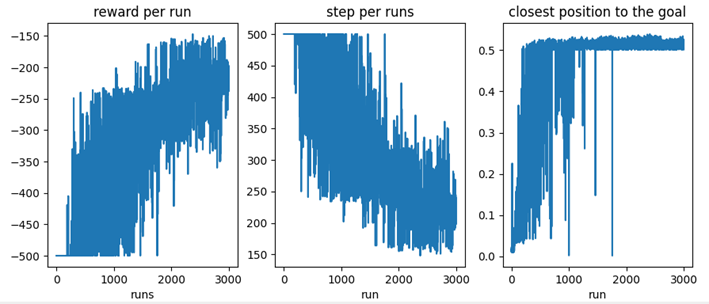
See below the configurations and the good results achieved when initialiting the q values with random values between -1 and 1 to force unties when selecting the actions:
EPISODIC TASK CONFIGURATION
- REWARD
def get_reward(state, step, last_best_state):
if state[0] >= 0.5:
return 1
else:
return 0
return 0
- HYPERPARAMETERS
MAX_RUNS=3000
MAXIMUM_STEPS=500
EXPLORATION_STEPS_PER_STATE=100
INTERPOLATION=MAX_RUNS/10
ENV_NAME = "MountainCar-v0"
GAMMA = 0.95
LEARNING_RATE = 0.2
EXPLORATION_MAX = 1.0
EXPLORATION_MIN = 0.1
EXPLORATION_DECAY = 0.99995
- Q_VALUES INITIALIZATION
self.q_values = np.random.uniform(low = -1, high = 1,
size = (self.num_states[0], self.num_states[1],
env.action_space.n))
- RESULTS
CONTINUOUS TASK CONFIGURATION
- REWARD
def get_reward(state, step, last_best_state):
if state[0] >= 0.5
return 0
else:
return -1
return 0
- HYPERPARAMETERS
MAX_RUNS=3000
MAXIMUM_STEPS=500
EXPLORATION_STEPS_PER_STATE=100
INTERPOLATION=MAX_RUNS/10
ENV_NAME = "MountainCar-v0"
GAMMA = 0.95
LEARNING_RATE = 0.2
EXPLORATION_MAX = 1.0
EXPLORATION_MIN = 0.1
EXPLORATION_DECAY = 0.99995
- Q_VALUES INITIALIZATION
self.q_values = np.random.uniform(low = -1, high = 1,
size = (self.num_states[0], self.num_states[1],
env.action_space.n))
- RESULTS
DEMO