Comparing DQN and QLearn algorithms in cartpole problem resolution
INTRODUCTION
Now that we have solved cartpole with more than one algorithm, lets compare their performance
QLearning Vs DQN comparison
TRAINING
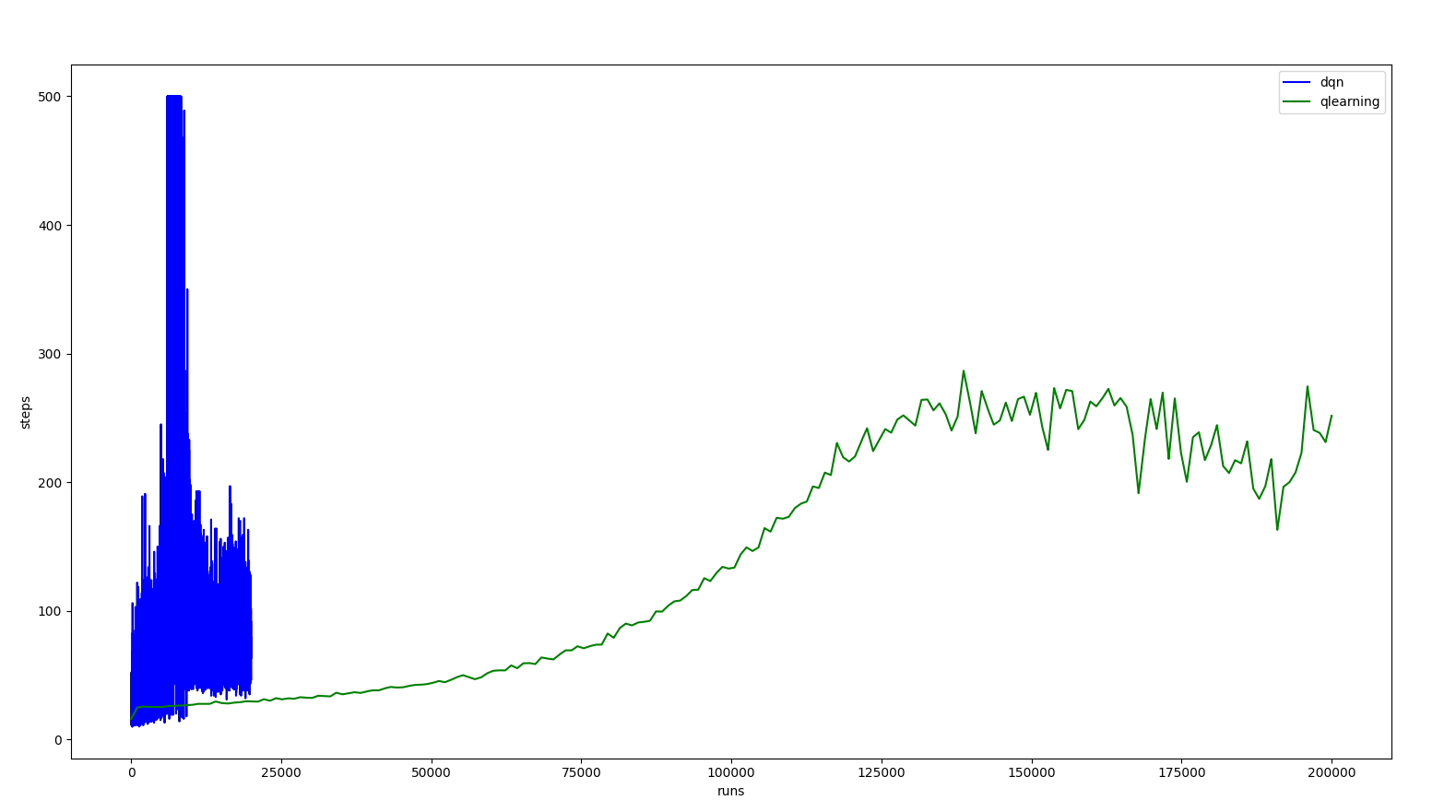
As we can see in the following figure, qlearning takes longer than dqn to train, since it needs more explorations to fill the q values table used to choose what is the best next step. That said, QLearning took more than 200000 steps and 40 minutes to learn its best policy. Moreover, DQN took 20000 steps and 20 minutes.
INFERENCE
SIMPLE SCENARIO ACHIEVEMENTS
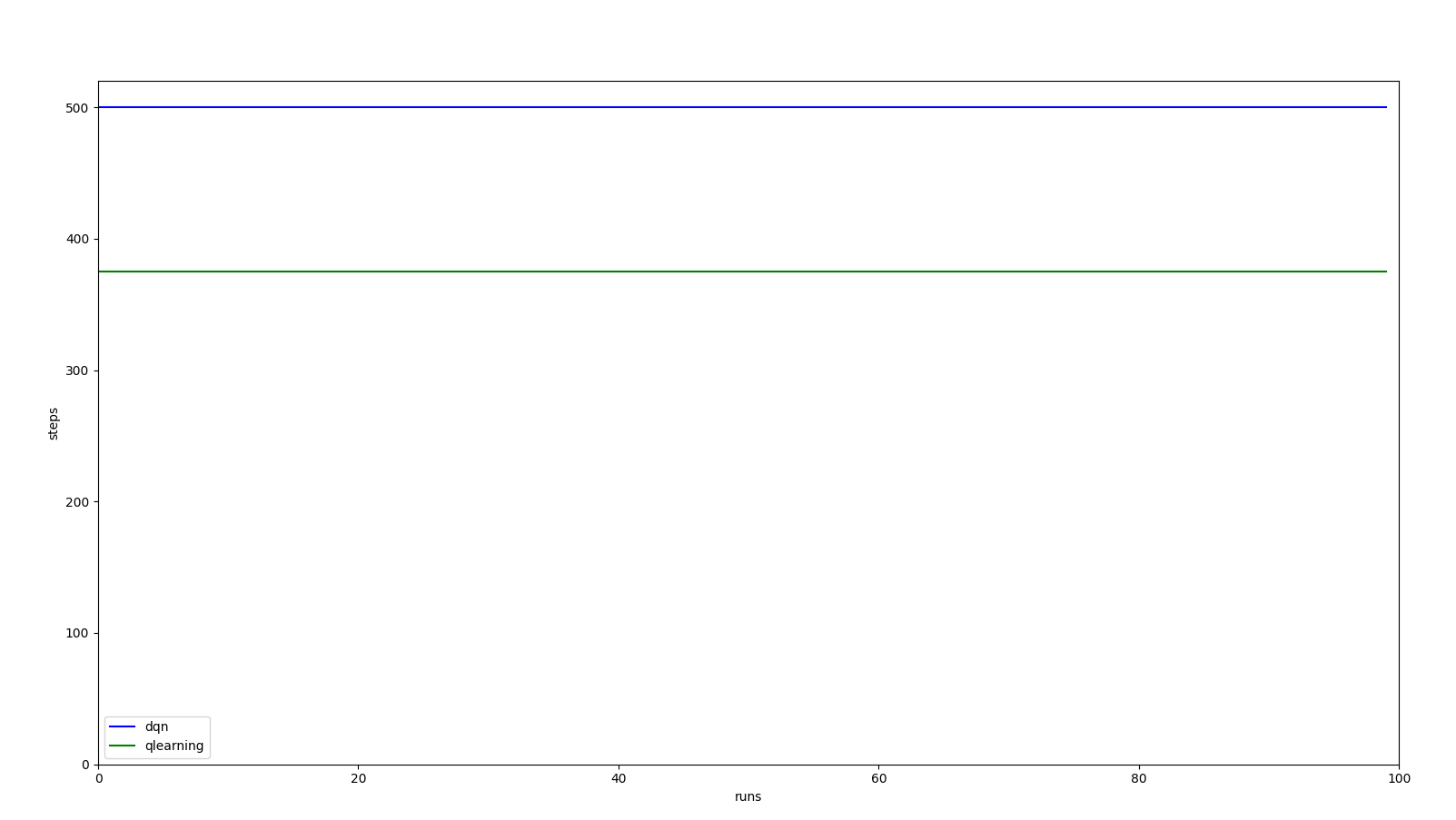
While qlearning is not able to perform more than 400 steps. DQN learns to keep the pole always vertical in a non perturbation scenario. However, if we trained infinitely we would have likely achieved a perfect agent in qlearning (lookout for the next post)
PERTURBATIONS TOLERANCE
Additionally, if we add perturbations to the problem, DQN is able to recover from quite high level of perturbations. For more details about what it is able to achieve, see the following post
On the other hand, QLearning performance considerably decrease when adding a minimum perturbation. To illustrate it we will test both agents adding a perturbation of 10 (equal to the action intensity) the 20% of the control iterations The following figure illustrates how more solid is DQN than QLearning:
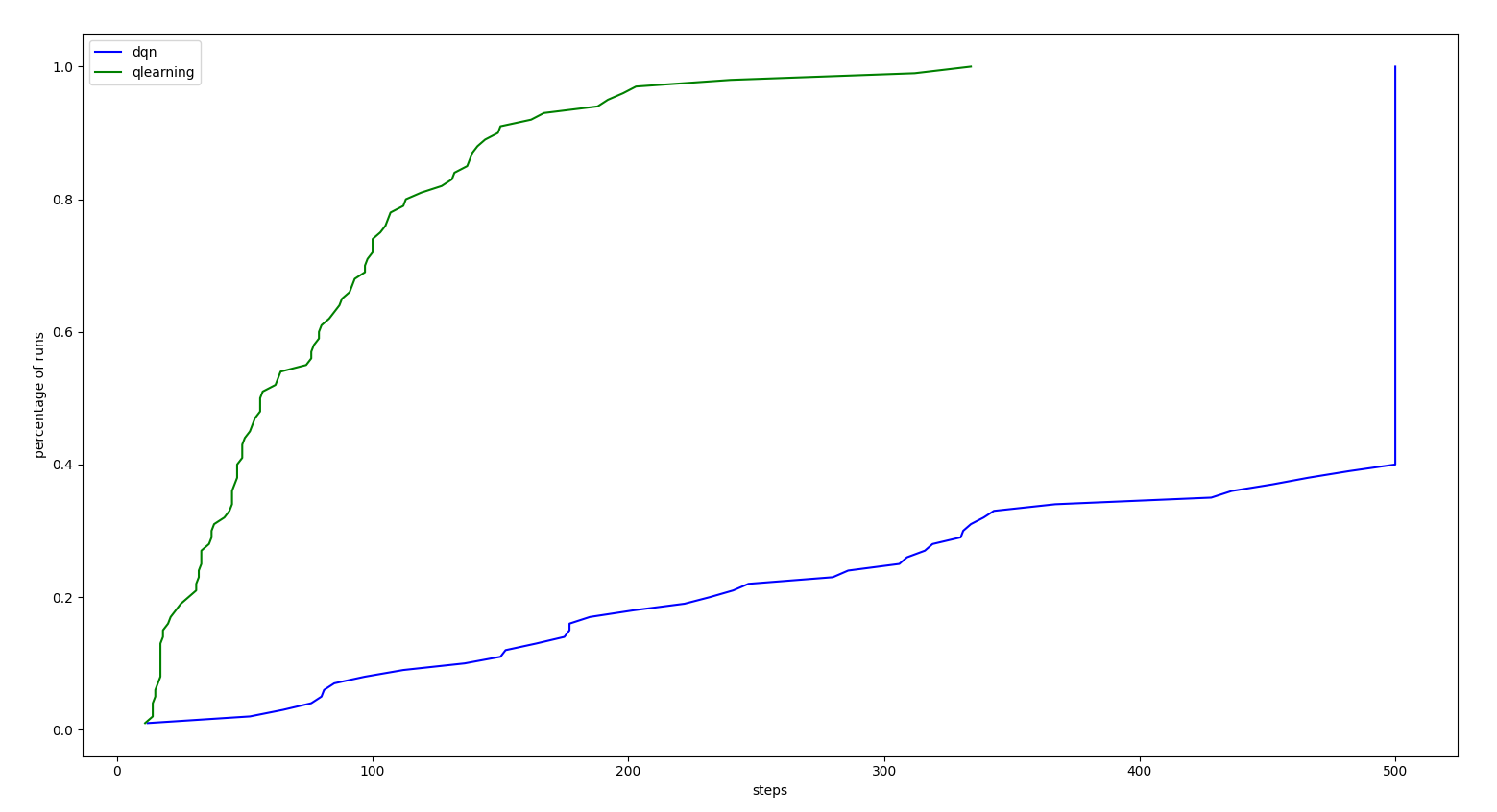
- The DQN agent is able to reach the 500 steps (goal achievement) the 60 percent of the episodes
- The Qlearning agent reach a maximum of 300 steps, being the 80% of the episodes below 100 steps
Note that the actions taken by the agent have an intensity of 10.
CONCLUSION
We showed that when a wide possible actions and states are encountered, a DRL algorithm is much more adequate