Adding deviation from the center and improved graphs
INTRODUCTION
Now that we solved cartpole problem with discrete actions, we want to explore how it would work some continuous actions algorithms. However, we want to compare their behaviour in a fair scenario, so we are also iterating the cartpole environment to behave as close as possible to the real world, improving the physics provided by openAI to not to have a fixed iteration control time.
that said, the following results are provided with the following algorithms configuration: (Since the 4 discrete actions algorithm have been exposed in previous blog, we analyse here the two continuous actions added algorithms)
PPO (continuous actions)
The idea with Proximal Policy Optimization (PPO) is that we want to improve the training stability of the policy by limiting the change you make to the policy at each training epoch: we want to avoid having too large policy updates.
For two reasons:
- We know empirically that smaller policy updates during training are more likely to converge to an optimal solution.
- A too big step in a policy update can result in falling “off the cliff” (getting a bad policy) and having a long time or even no possibility to recover.
for more details regarding PPO, it is explained in the following post And even more in detail here
We used the “Clipped Surrogate Objective” approach and the parametrization was he following:
- gamma: 1
- epsilon: 0.15
- random perturbations std: actions_force / 10
- perturbations frequency: 80% of control iterations
In this case the training took around 5 minutes to converge in ppo_discrete and 2 minutes in ppo_continouse
DDPG
This is another actor critic algorithm also closely related to Q-learning. Deep Deterministic Policy Gradient (DDPG) is an algorithm which concurrently learns a Q-function and a policy. It uses off-policy data and the Bellman equation to learn the Q-function, and uses the Q-function to learn the policy.
the used network had a 1 hidden layer with 128 neurons an adam optimizer, tanh activation functions for inermediate layers and none activation function for the last one. The used hyper parameters were the following:
- gamma: 0.99
- learning rate: 1e-4
- batch size: 128
In this case the training took around 10 minutes
TRAINING
As it can be seen in the following image, ppo is much faster and efficient when learning. Both of them converge in less than 1000 iterations, being the training much more stable from then.
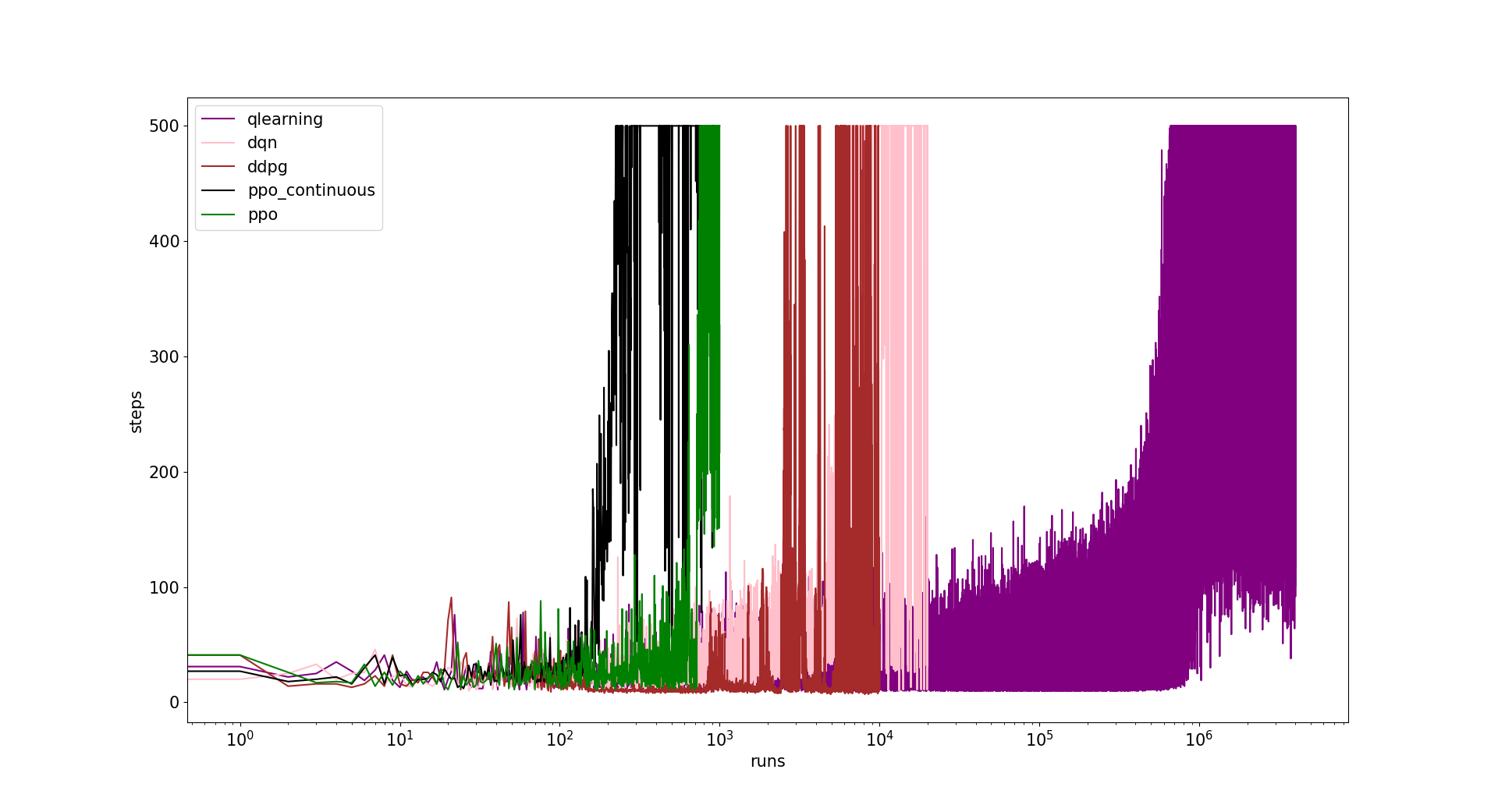
We do not have reasons to think yet that discrete actions provides any advantage with respect to continuous actions in ppo.
INFERENCE
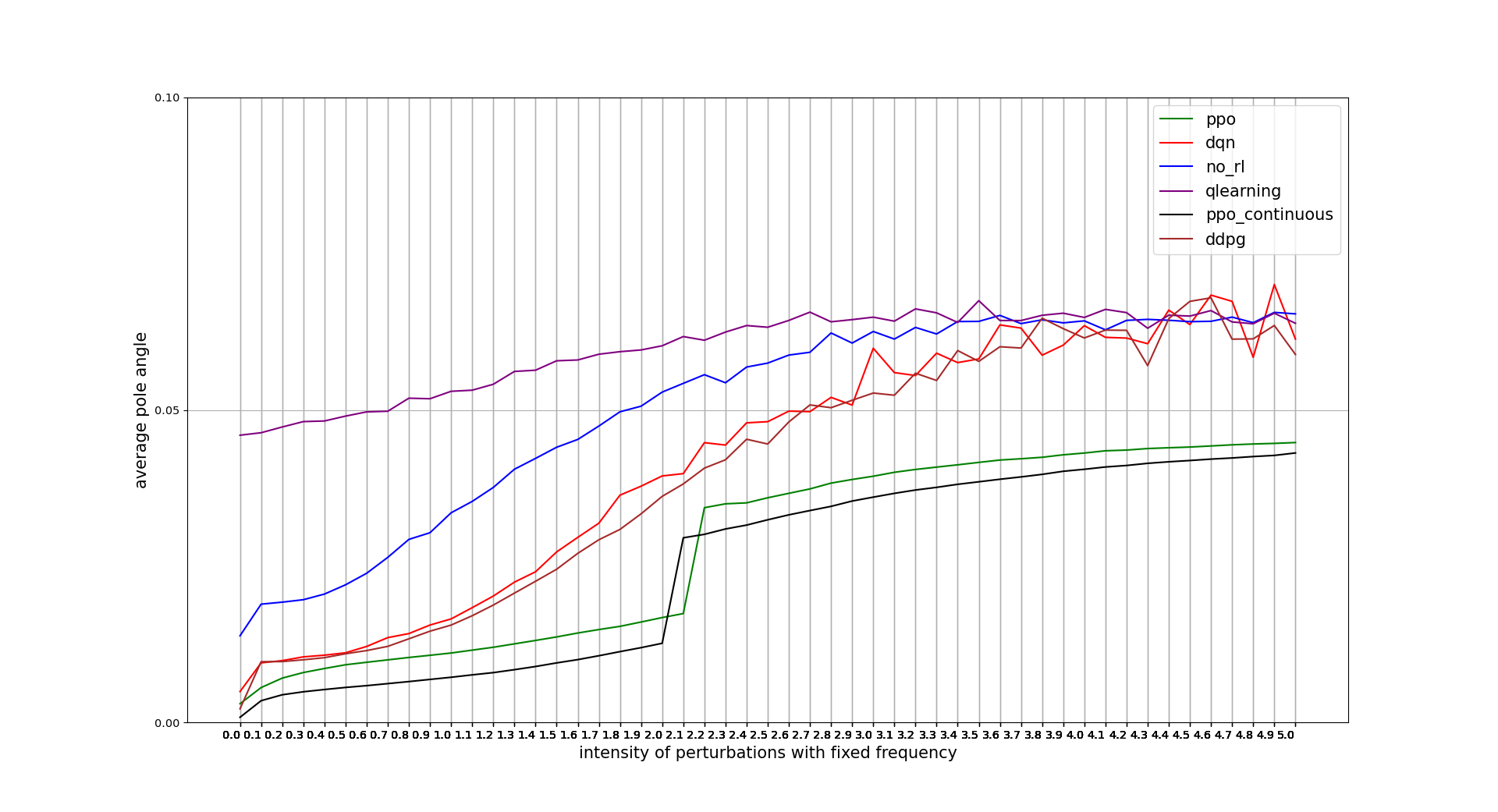
PERTURBATIONS INTENSITY TOLERANCE
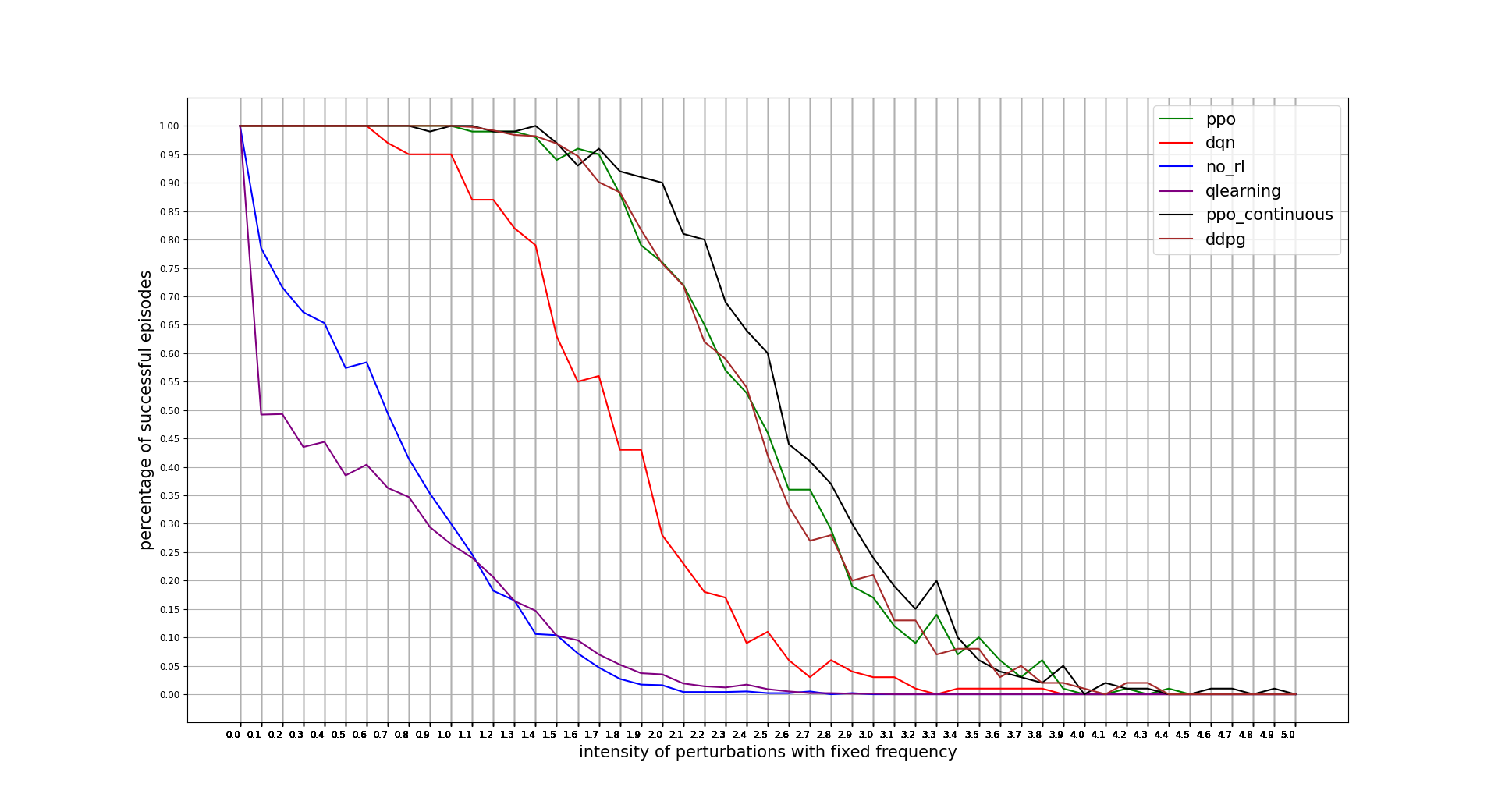
PPO continuous actions wins in this regard, being the discrete actions algorithm outperformed by the continuous ones. Note that x units is the percentage of the intensity applied with respect to the maximum intensity available for the agent actions. 0.1 = 10%
confidence intervals:
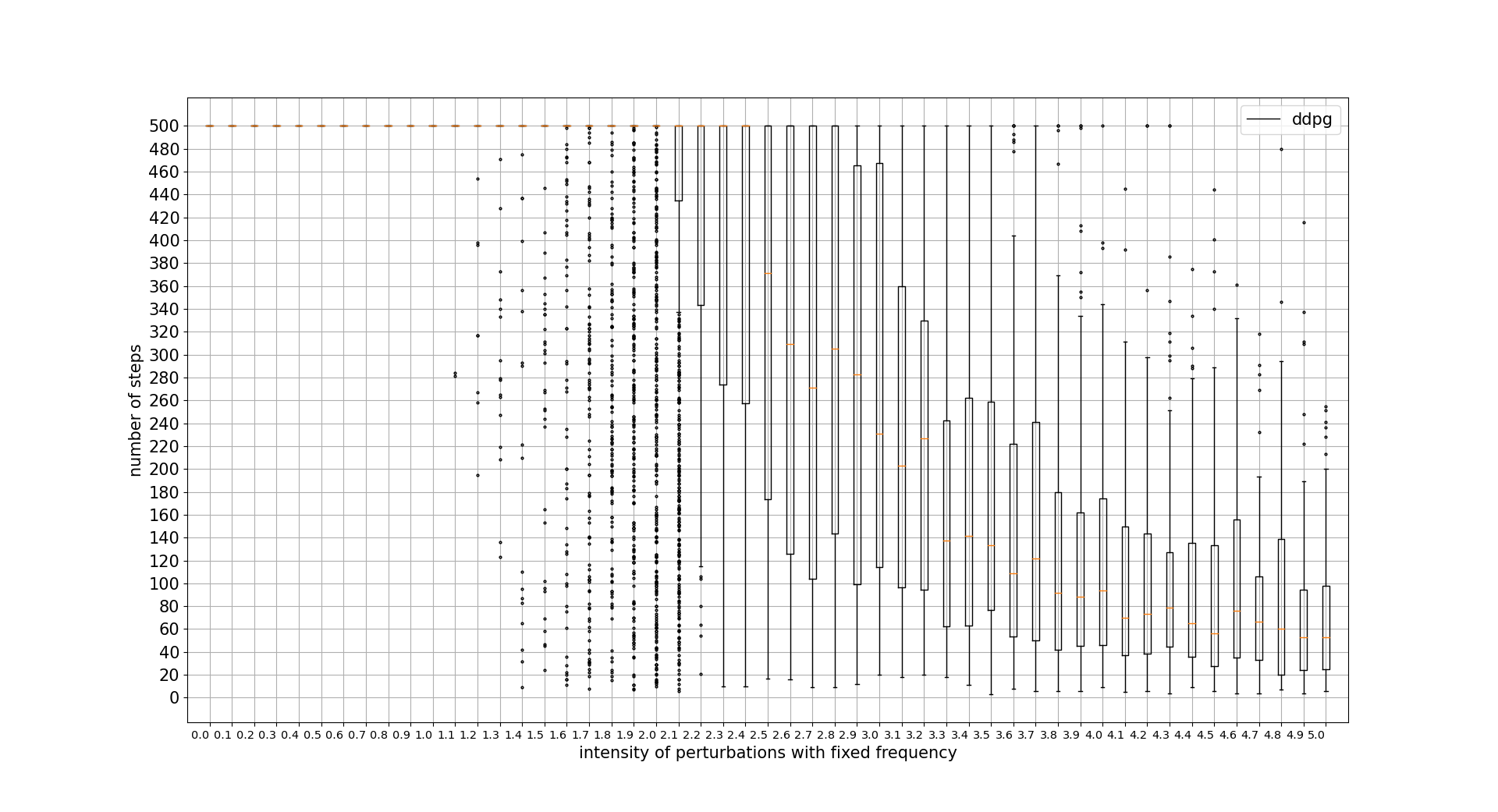
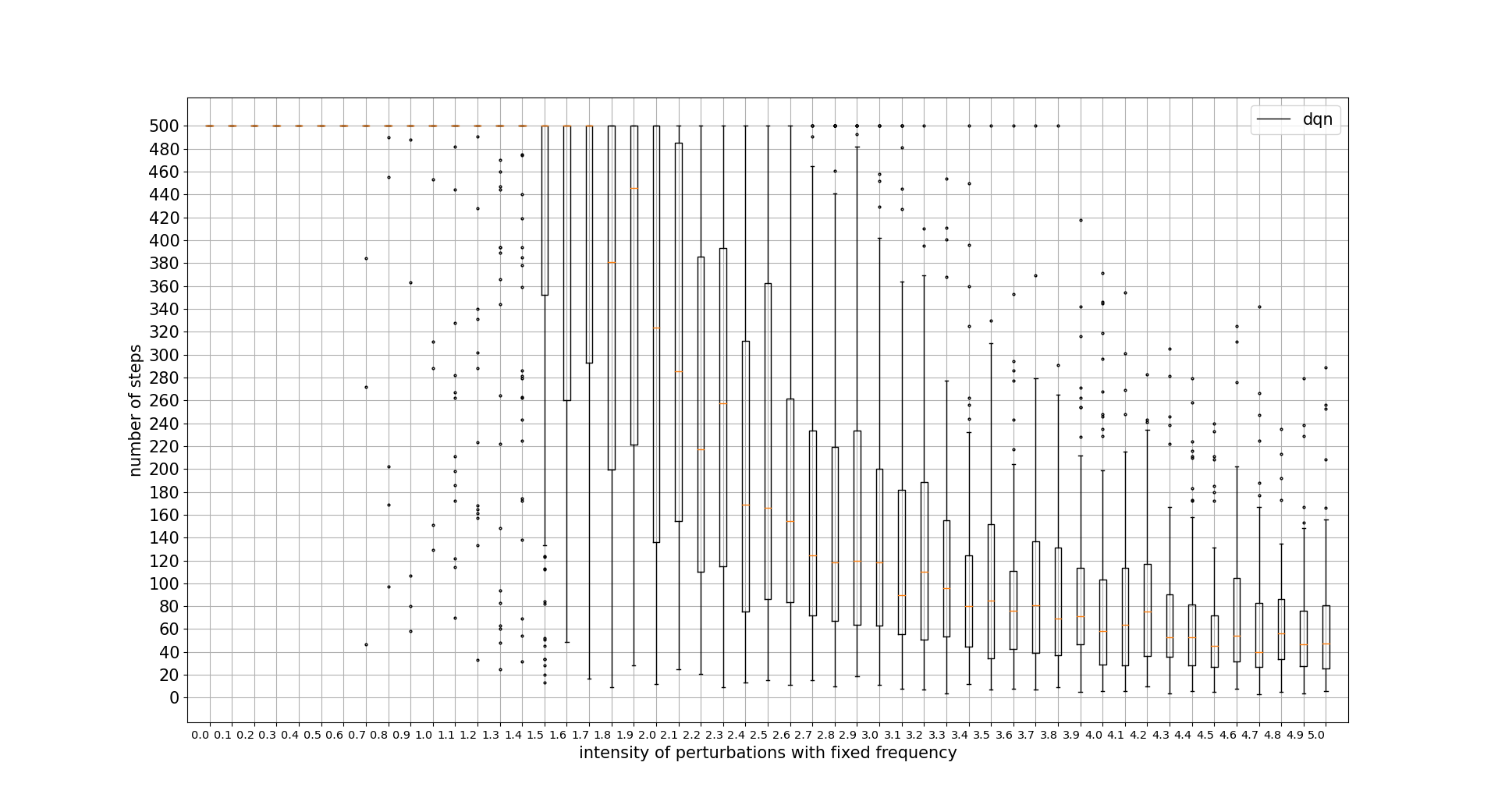
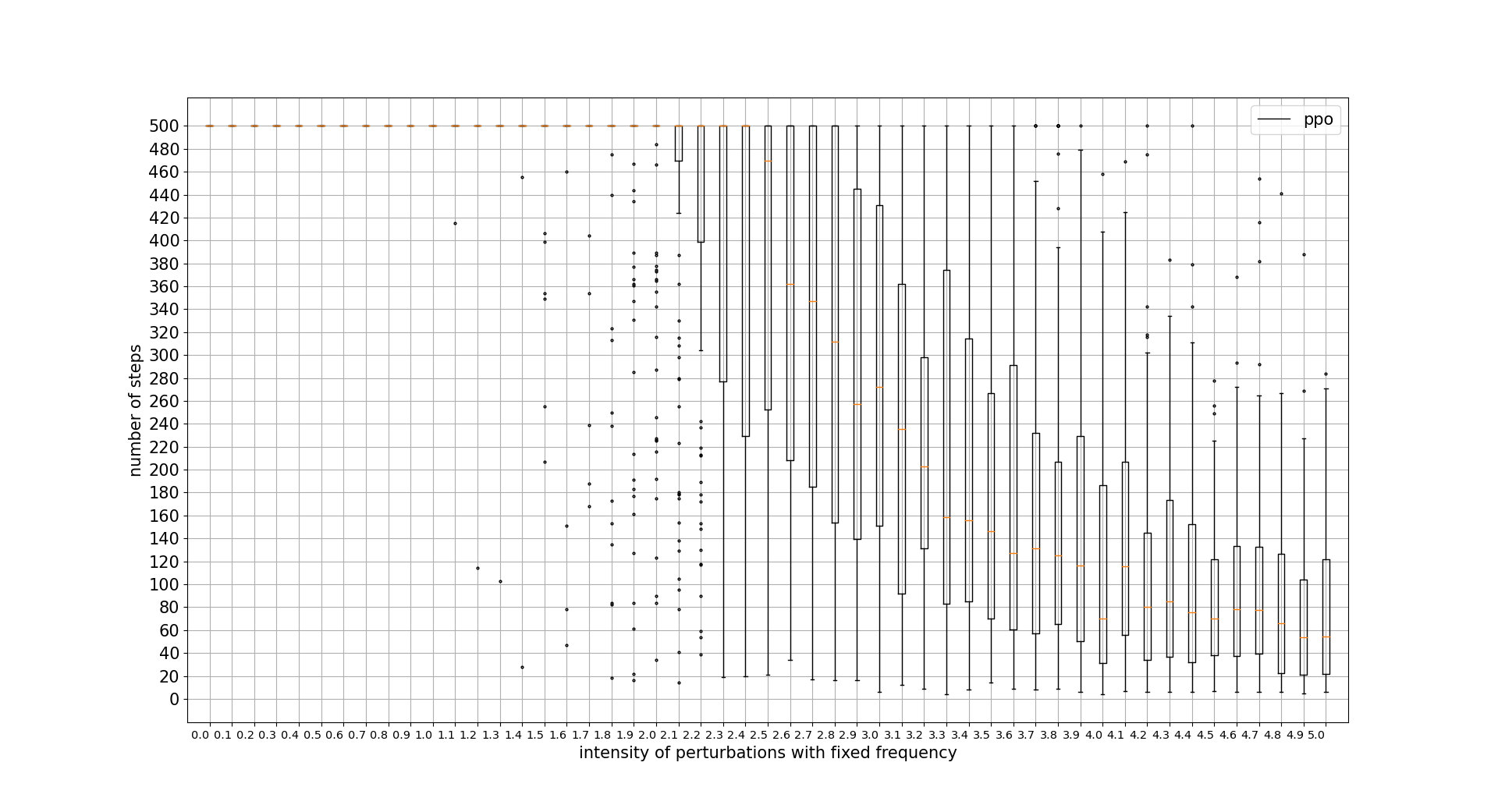
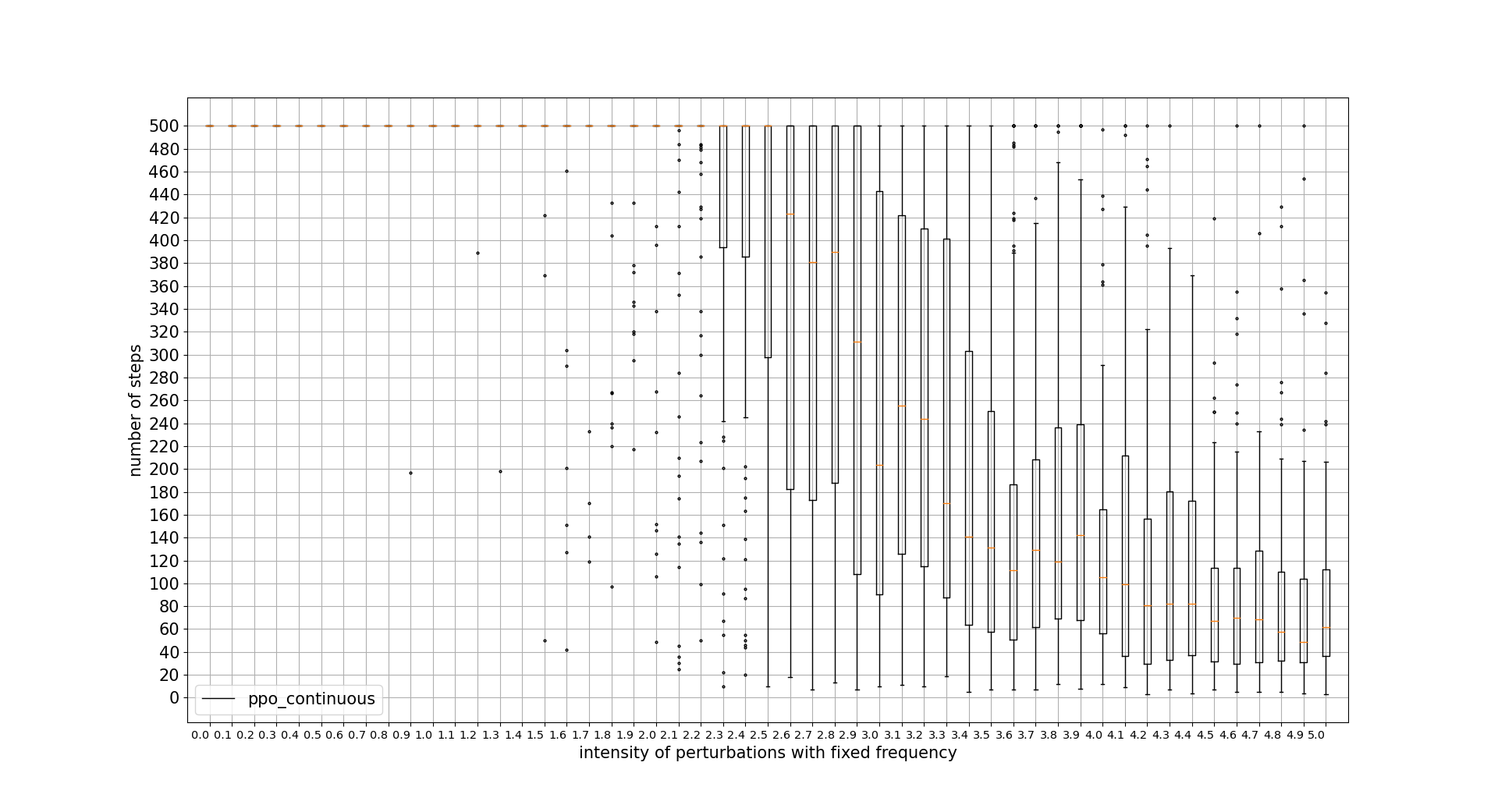
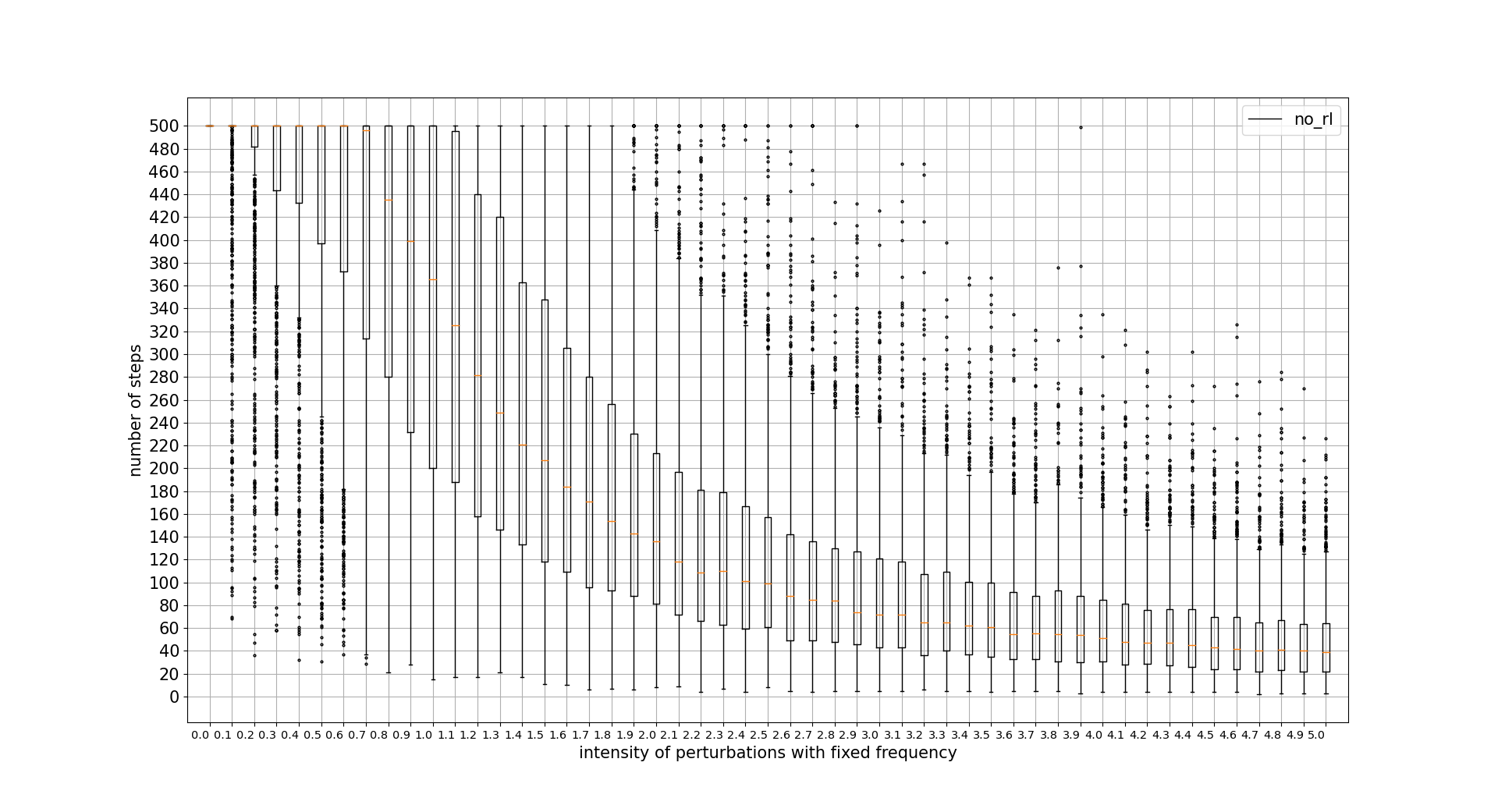
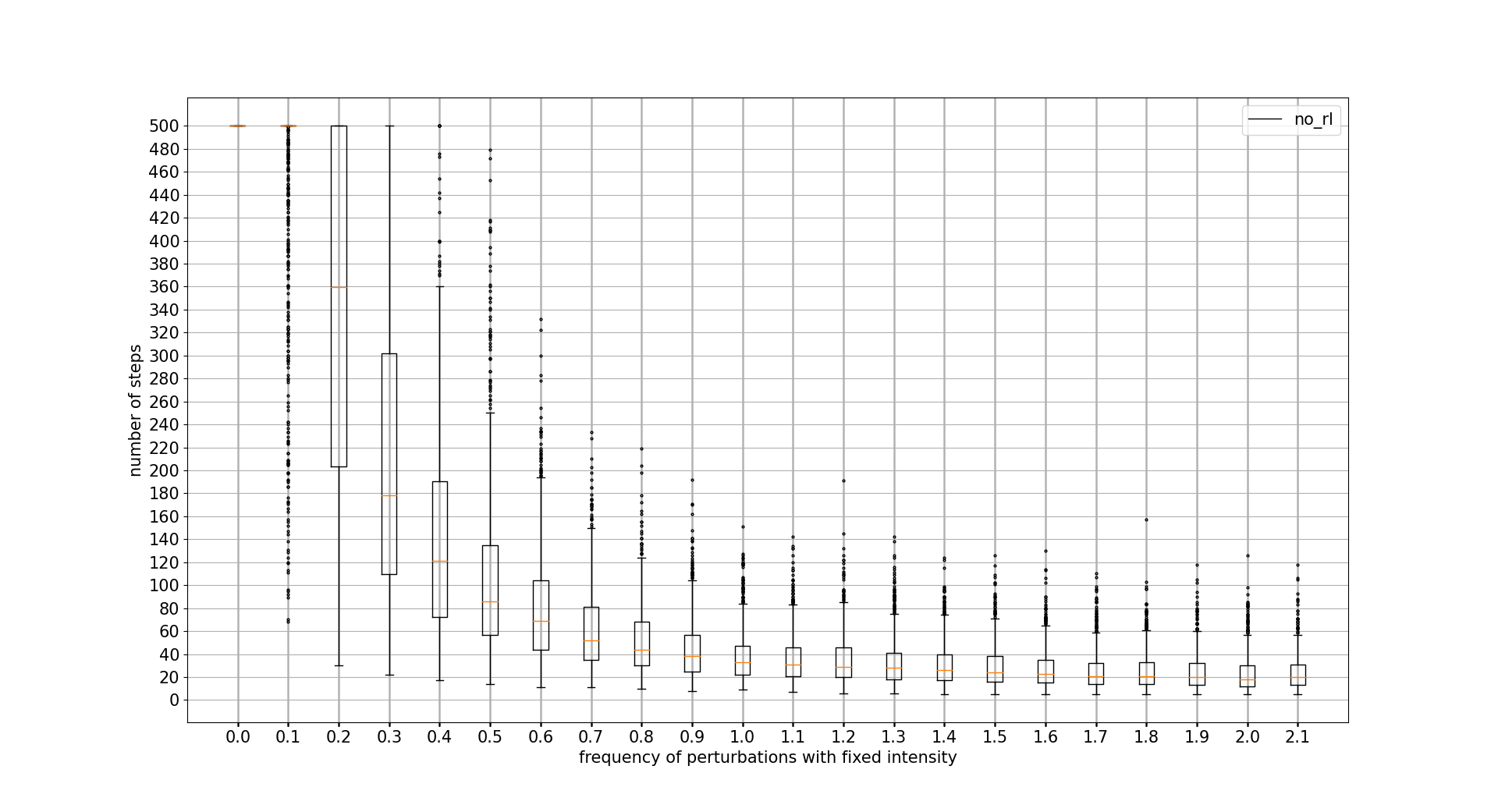
PERTURBATIONS FREQUENCY TOLERANCE
In this case, PPO wins at all cost. DDPG is not able to outperform PPO discrete actions algorithm. Note that x axis unit is the percentage of iteration controls where a perturbation is applied 0.1 = 10%
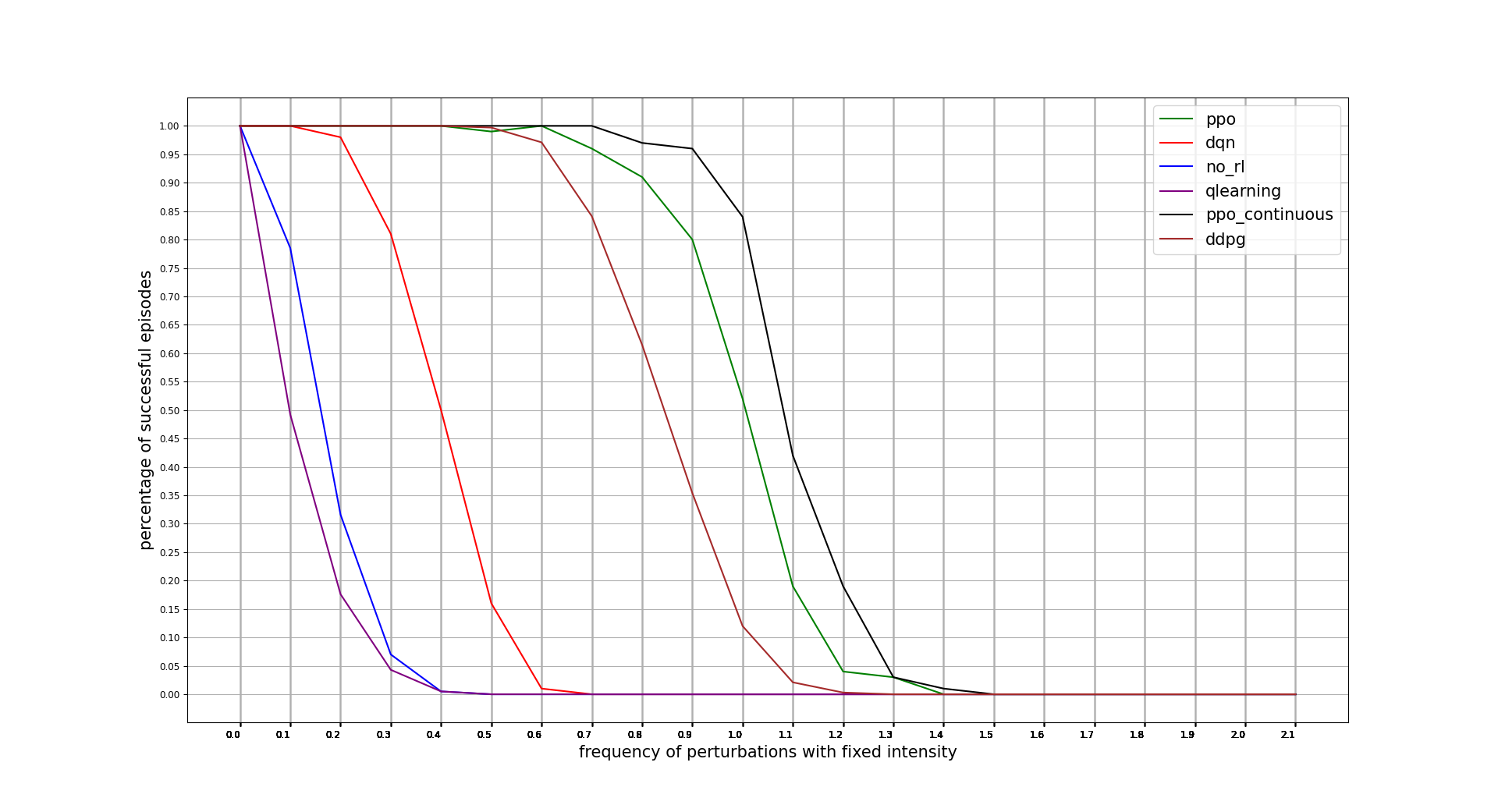
confidence intervals:
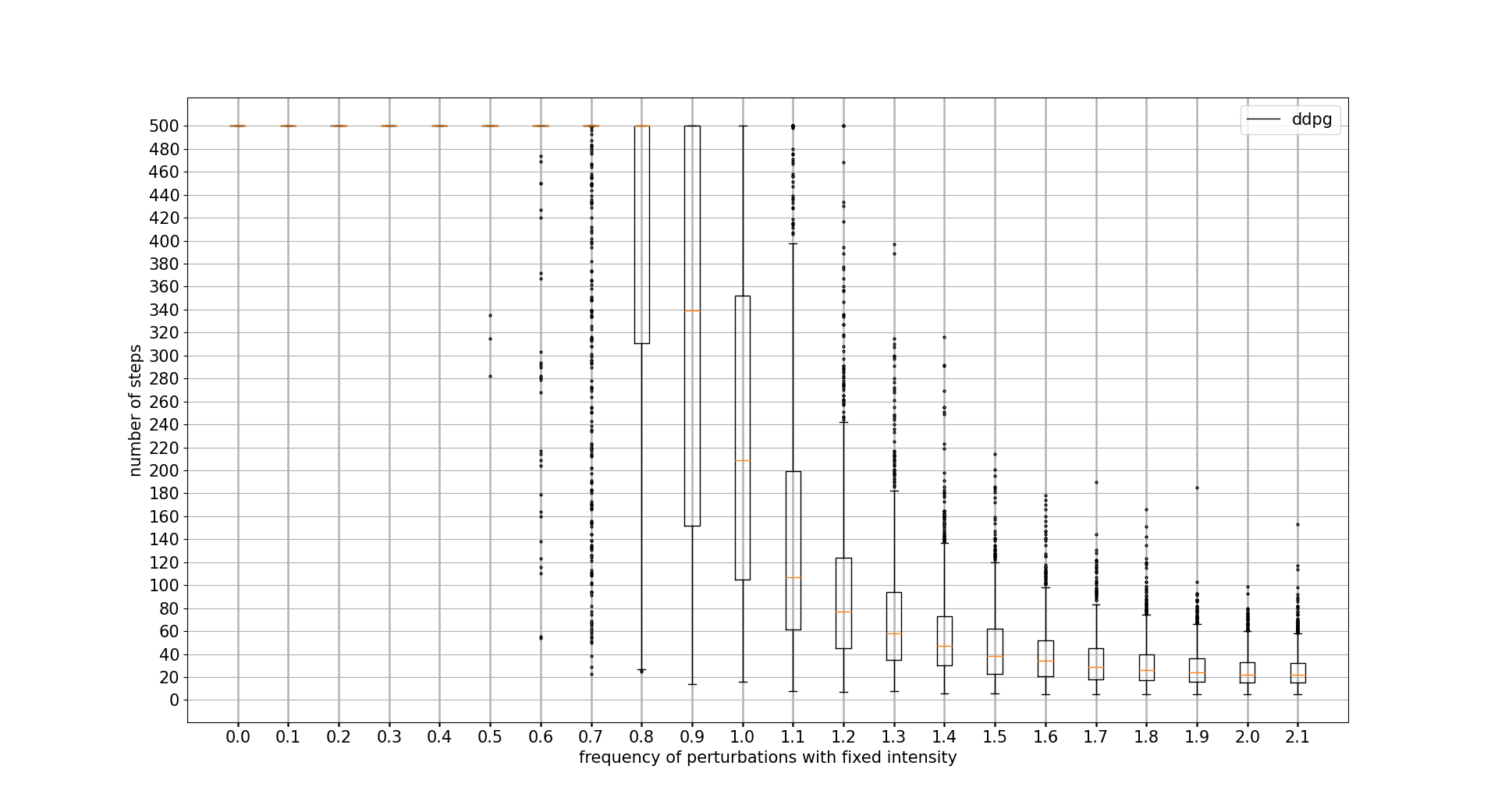
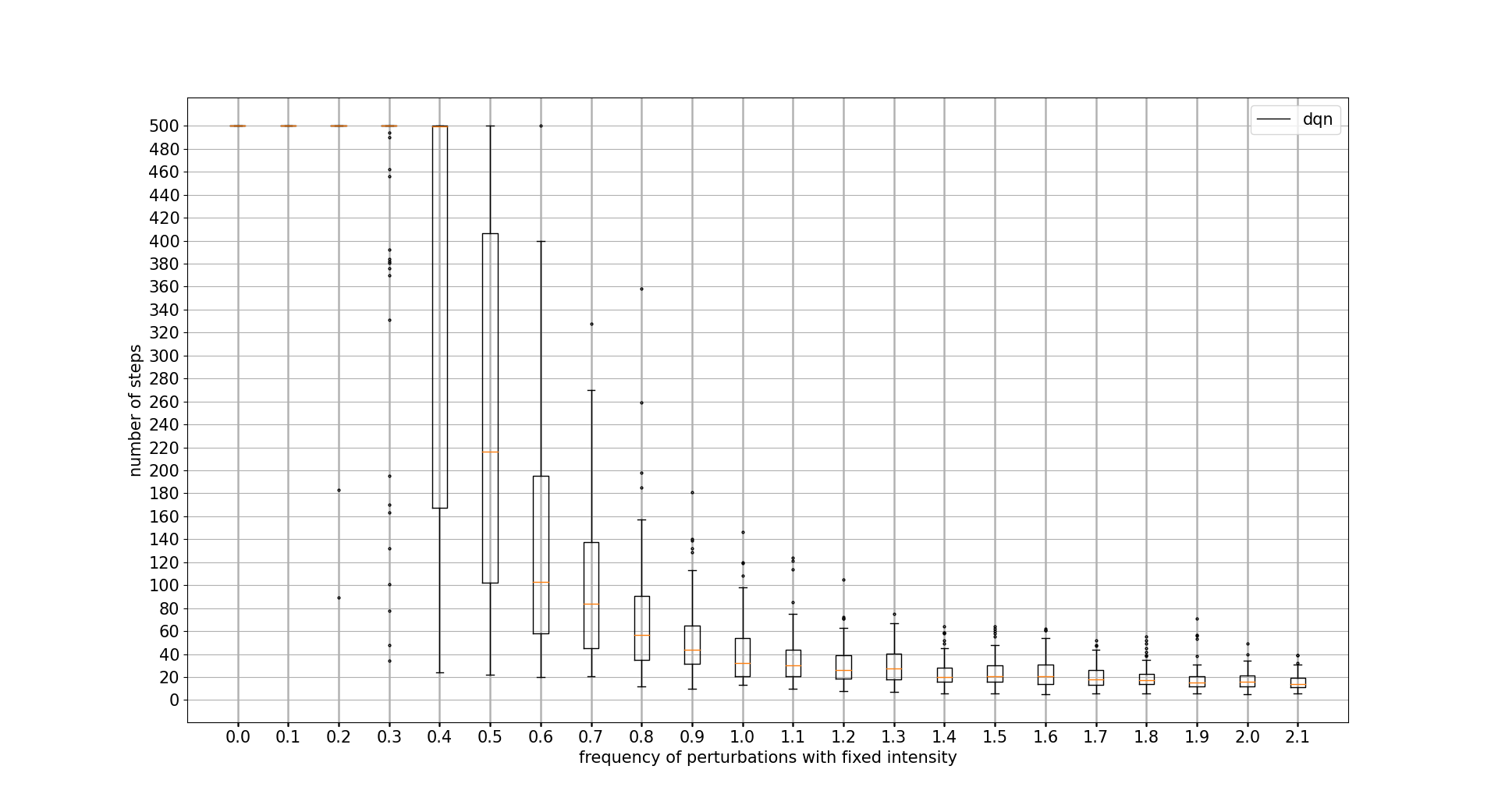
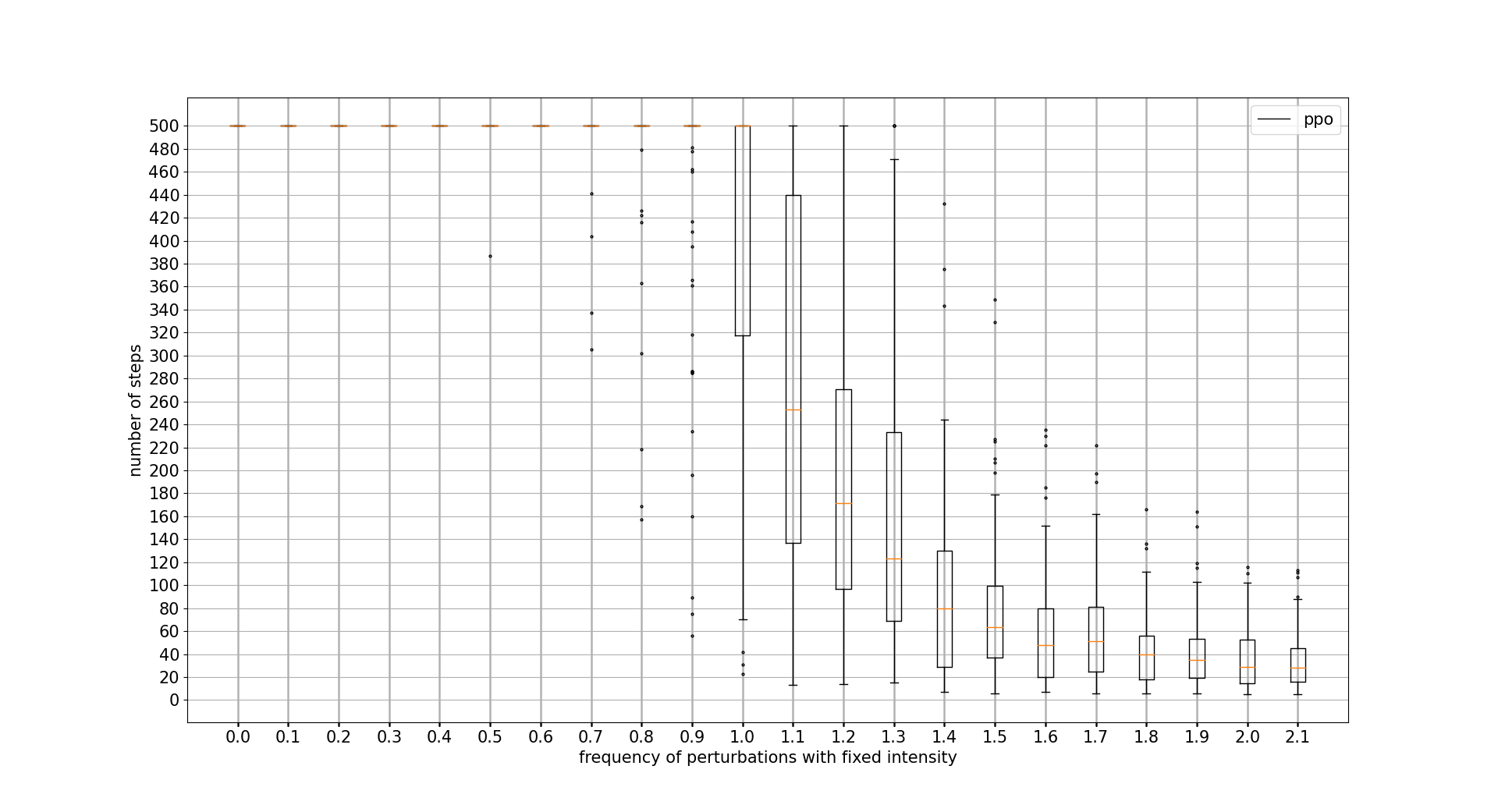
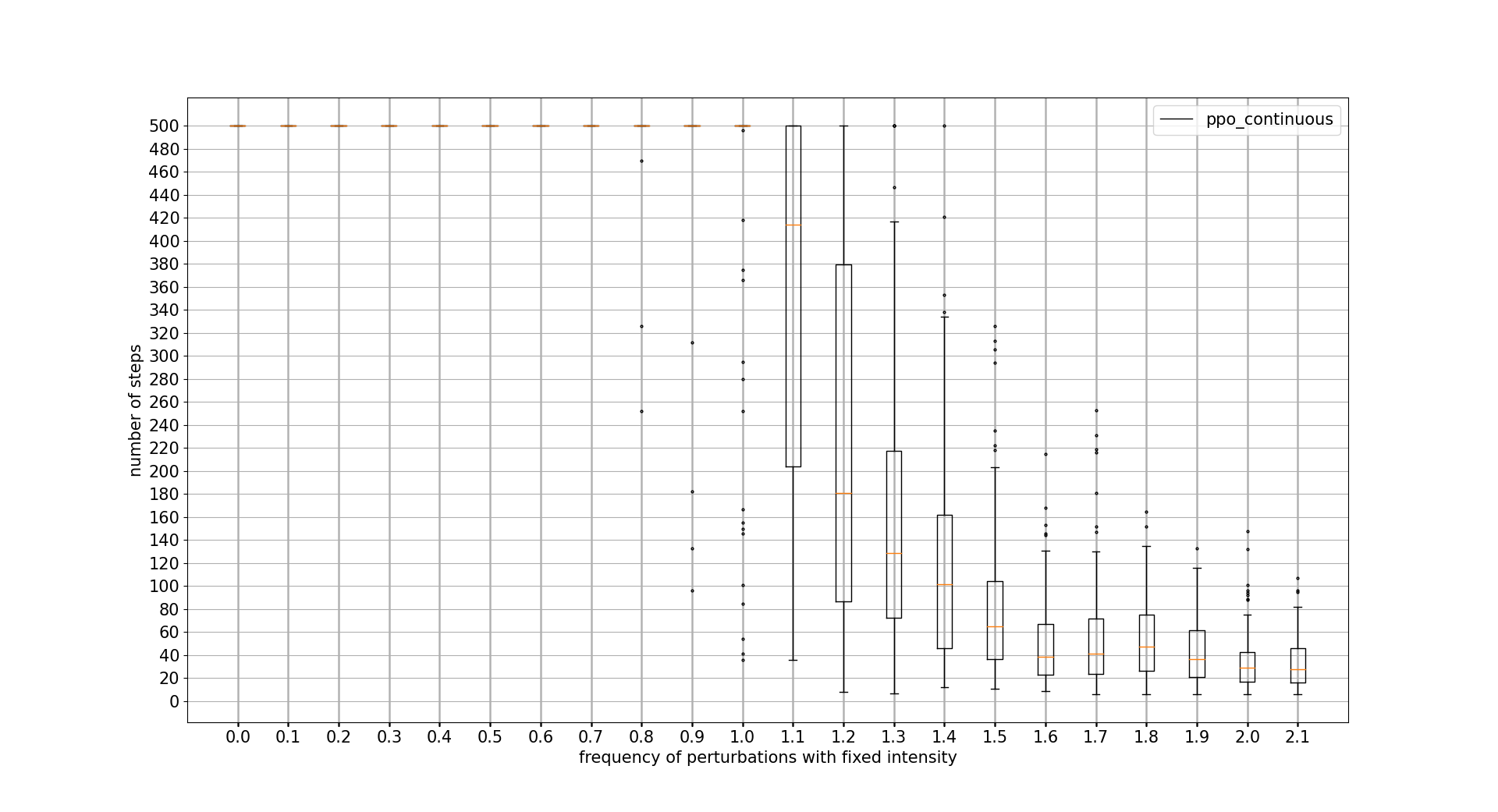
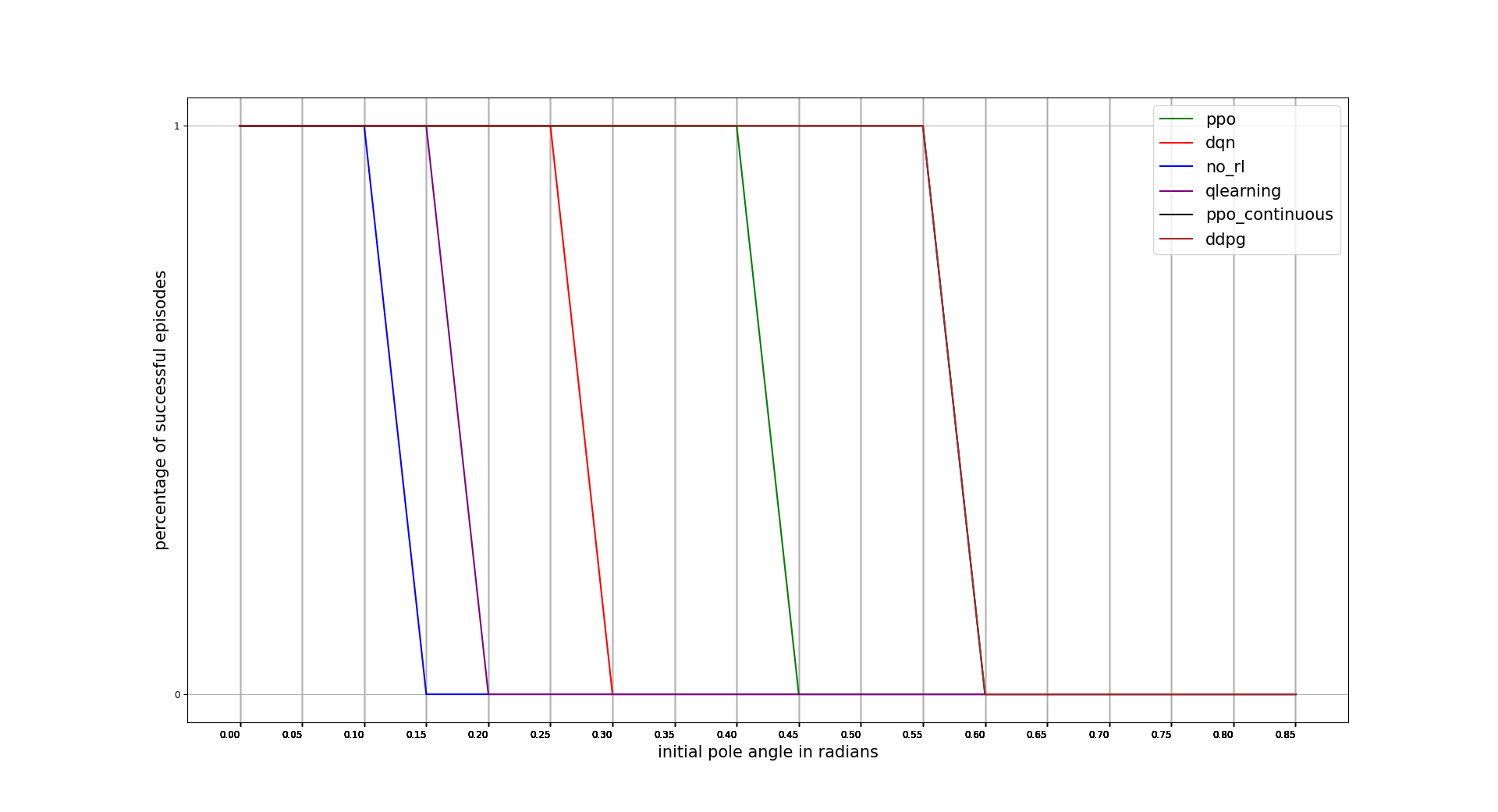
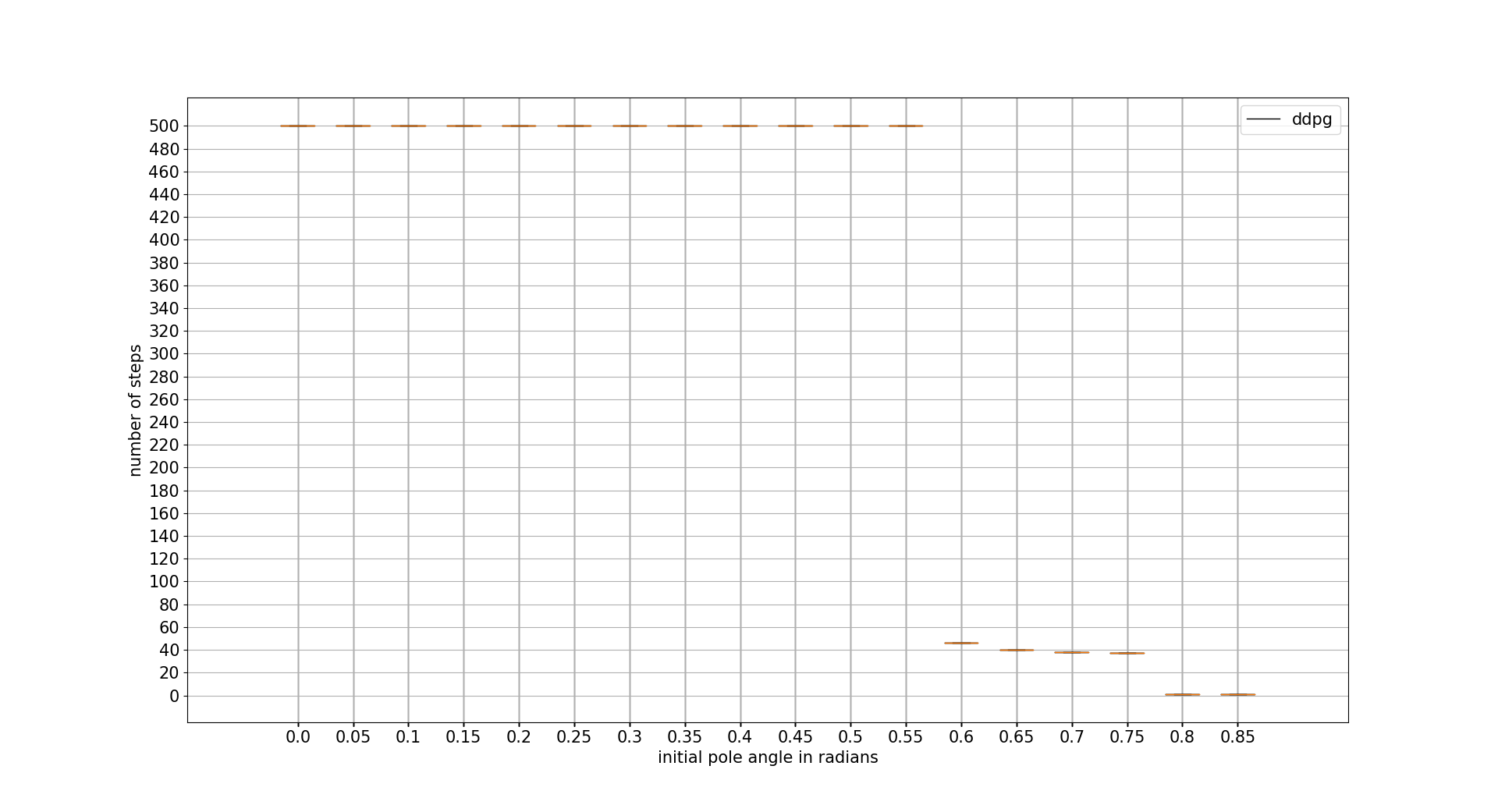
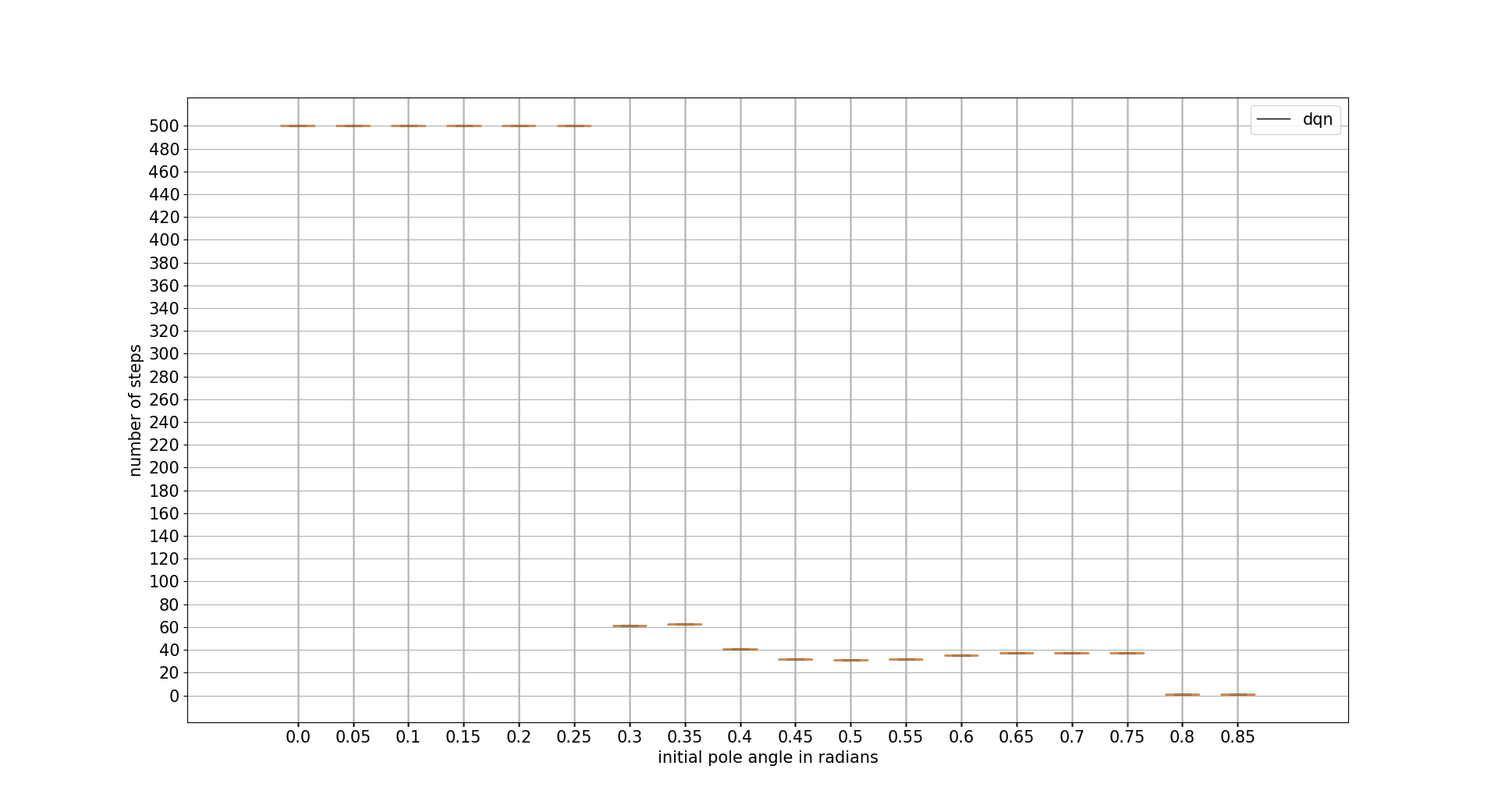
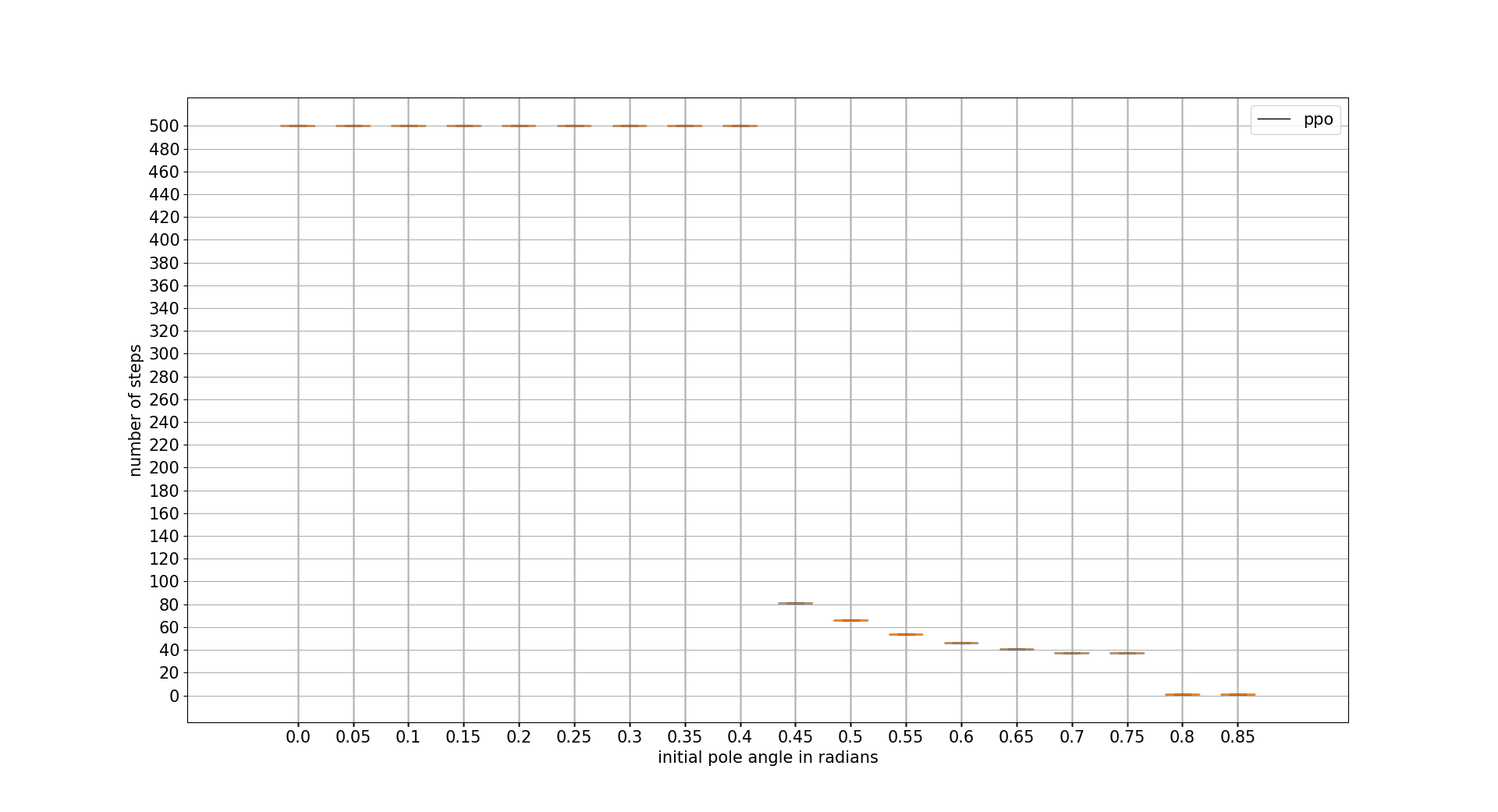
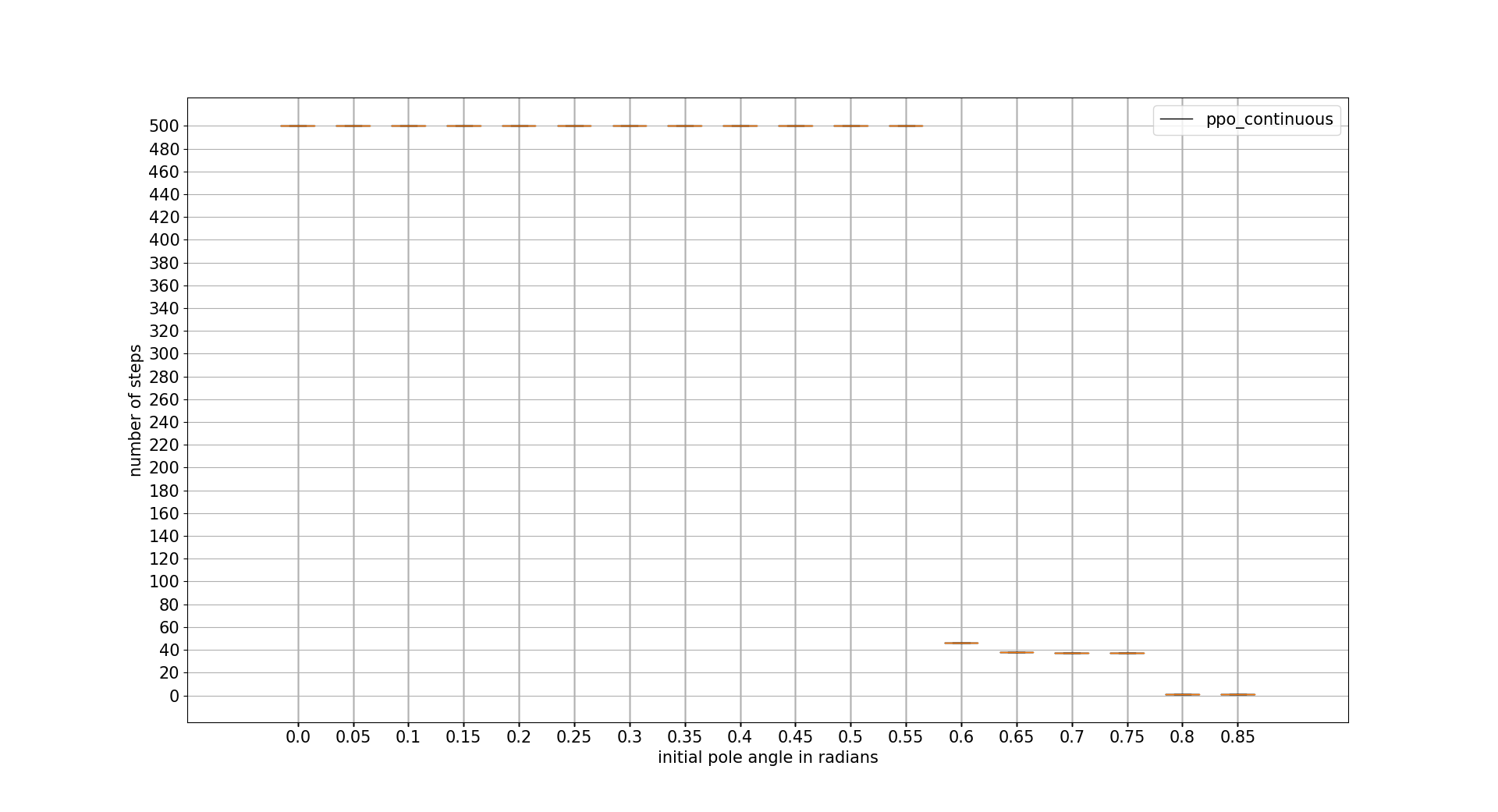
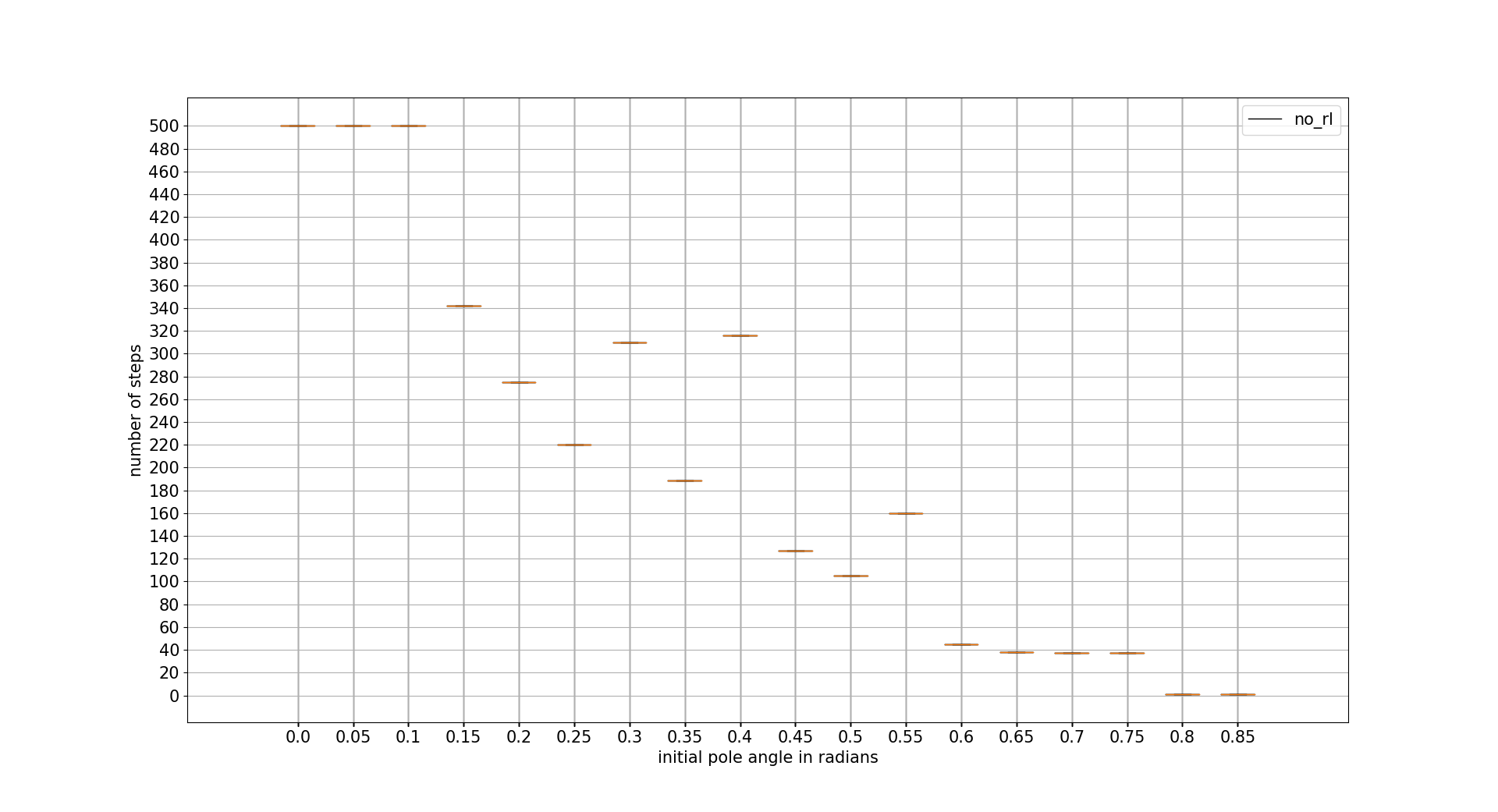
INITIAL POLE ANGLE TOLERANCE
In this case DDPG is the best one with difference. Recovering from a really adverse initial position. Note that the x axis units are radians
confidence intervals:
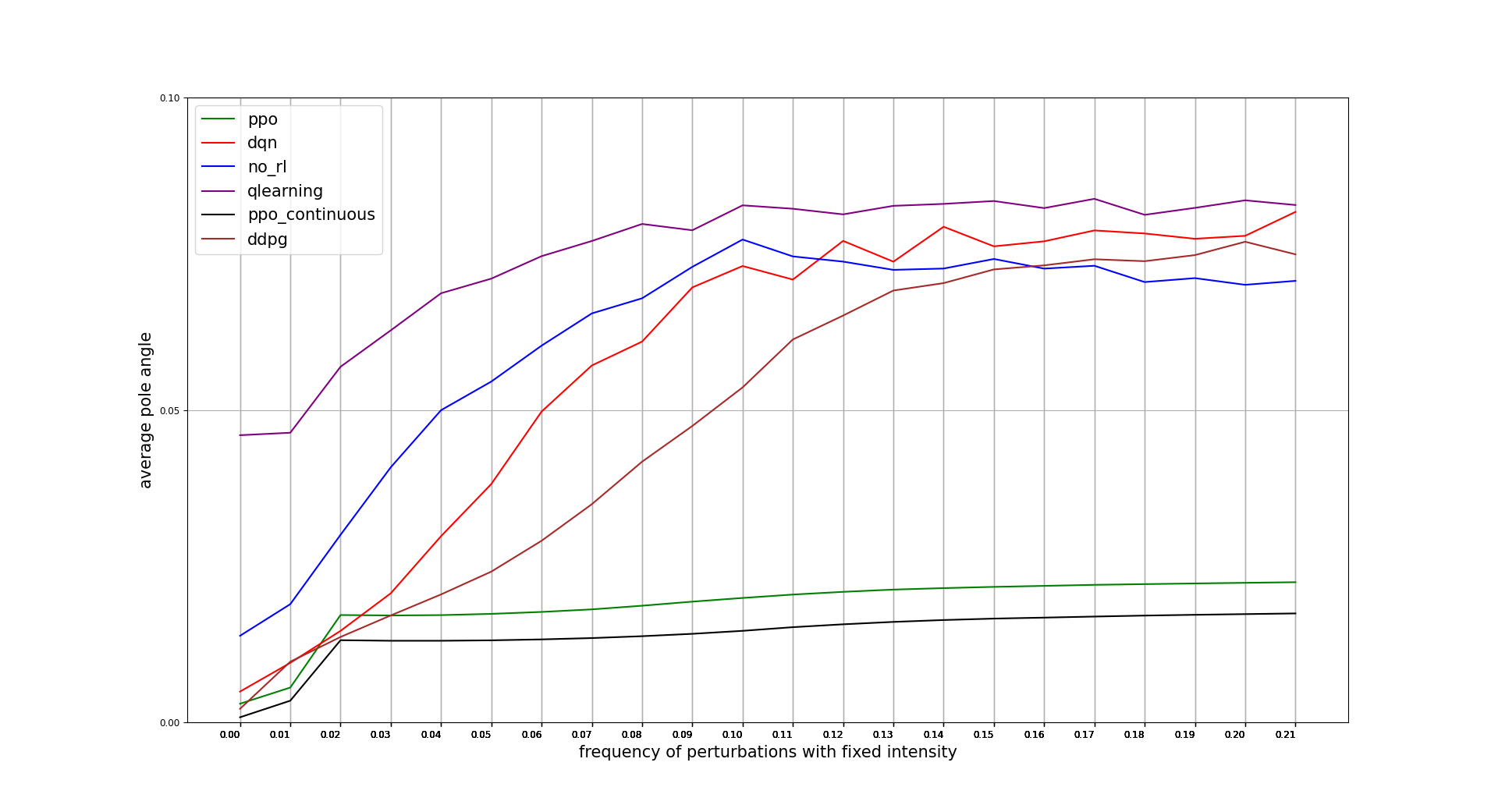
Absolute average angle deviation with respect to the center
An interesting analysis to perform is how stable is the agent to the different perturbations, so we also illustrate in the following graph the absolute average deviation from the vertical in the different use cases previously mentioned
training control iteration times
The following are the times that 1 control iteration takes at training time:
-
QLEARNING -> 3.0823134953899285e-05 (Fastest)
-
DQN -> 0.00017751333668847394 (Fastest DRL)
-
PPO_CONTINUOUS -> 0.0010866998368678623
-
PPO -> 0.0016804589243498828
-
DDPG -> 0.0028640604265402826
inferencing control iteration times
The following are the times that 1 control iteration takes at inferencing time:
-
PROGRAMMATIC -> 1.3000000000000858e-05 (Fastest)
-
QLEARNING -> 2.6726140000009457e-05 (Fastest RL)
-
DDPG -> 0.0001359128571428555
-
DQN -> 0.00014053947368421053
-
PPO -> 0.00028647799999999924
-
PPO_CONTINUOUS -> 0.0008786243257633599 (Slowest)
CONCLUSIONS
In here we demonstrated the following:
- when the problem is simple and we do not have too many inputs-outputs, an continuous actions algorithm works better than a discrete one.
- ppo still being the most sample efficient and best performance agent of these 4.
- DRL discrete actions algorithm behaves quite well, but continuous actions are better in all regards for a simple and constrained problem like this one.
- the iteration control is quite similar in all algorithms, not being in this simple problem a key factor to choose one or another. However, it has to be consistent the frequency when training with the frequency when inferencing
- neural networks with 1 hidden layer is more than enough for this. In case the task is not that easy (and solution seems to not to be a linear combination of the inputs) we could consider adding more layers, but we must note that the training will be longer and more unstable. However, adding neurons to the hidden layer can improve the training, being however 128 more than enough for a simple problem like this (according to some lectures it should work even with around 4).
- 1 solidity test could give enough information to know which algorithm is better solving the problem. However, it could happen that unexpected situations or a modification in the problem to solve makes a different algorithm/agent better for that specific use case (we showed that DDPG tolerates better adverse initial position while PPO tolerates better random perturbances)
- When training with continuous actions and a robust algorithm, adding perturbations at training time can help
- training and inferencing iteration control frequencies must be controlled in order to decide at a reasonable frequency
- increasing this control iteration frequency can help to improve the agent behavior, but keep also in mind that actions must be adjusted accordingly (mostly when using a discrete actions algorithm)
- Both inferencing and training times can vary according to the way of implementing each algorithm, but an approximation of the speed at training and inferencing in this report illustrates that DQN is the fastest one, DQN takes less time in training at each iteration than other DRL ones and PPO_Continuous is the slowest at inferencing time