Previous weeks - Getting the basics
How to train the Networks
After learning basics about how can we implement Neural Networks to predict object in the next frames of a video recording we need to understand how can we train this kind of Networks.
For that, Nuria created a dataset generator that we can use for create linear, parabolic or sinusoidal, defined the height and the weight of the image/frame, color of the point (for raw iamges)
First we are going to explain the differences between raw and modeled:
Modeled images are just coordenates in a text file that give us the current position of the point/pixel draw in the image representing the object to predict.
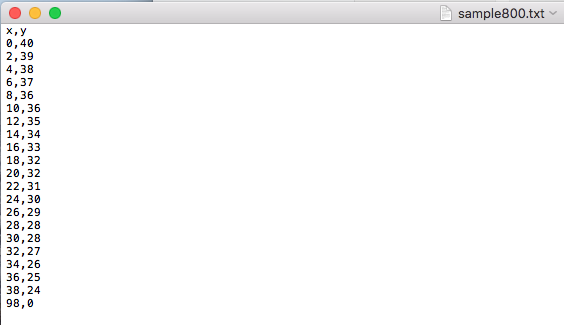
Raw images are .png images created with black and a white pixel indicating the position of the object.
Using sequence_generator_config.yml and main_gen.py you can configure the dataset expected chaging number of samples, raw or modeled, percentage of train and test values…
You can find the files in the repository: /Generator & Train_Test/Generator AMM with the modified changes for my analisys:
sequence_generator_config
Root to save
###root: C:/Users/optiva/Desktop/TFG/2020-tfg-alvaro-martin/Dataset root: /Users/Martin/Desktop/
Type of element to generate
to_generate: f #frame(‘f’)
If toGenerate = ‘n’; Function type
func_type: linear #linear
If toGenerate = ‘v’ or ‘f’; Motion type
motion_type: linear # linear, parabolic, sinusoidal
If toGenerate = ‘f’; Height, width, object
height: 80 width: 120 object: point # point, circle obj_color: 255 # For b/w: 255; For color: [0, 255, 0] dof: var # fix, var, (var_1), (var_2) Ordenados por orden 1,2,3,4..
circle_parameters: radius: 5
Number of samples
n_samples: 5000
Number of know points (x values)
n_points: 69
Gap between last know and to predict samples
gap: 30
Noise
noise: flag: False #True to add noise to the samples mean: 0 stand_deviation: 50
Separate train, test and validation
split: flag: True #True to separate fraction_test: 0.1 fraction_validation: 0.1