
Week 6-7. Q learning - changes
I am still working on how to improve the handling when the problem is multivariable (linear and angular velocity) by applying the Q Learning algorithm. The car manages to stabilise on straights and not very sharp curves, but it is not able to negotiate the more complicated curves. One of the reasons may be the speed of iterations. Currently the algorithm iterates at 10-15 iterations per second. At each iteration it processes the image to obtain the observation and updates the Q-table. The algorithm may not iterate fast enough to react in time, but I don’t think it is slow. Another reason may be that the reward function is not defined correctly. It may be giving rewards within a very small range, which when discretised will give the same value, as all the values would be within the same interval. To this end, I have been modifying the reward function and the observation function to see that different values are taken and that they are reasonable. These tests are presented in these graphs:
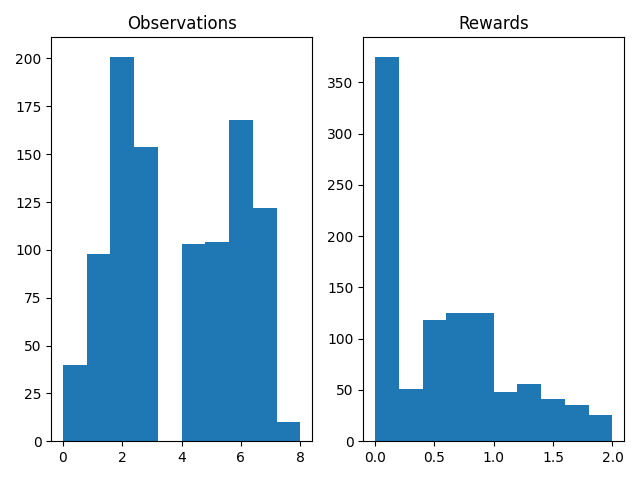
To extract the data, an agent with a random policy has been allowed to act on the environment for 1000 iterations. Discrete observations and rewards were obtained for each iteration. It can be interpreted as meaning that an observation with a value less than the mean value of the possible observations implies that the car is far to the left of the line and vice versa. Another problem I have detected is that although the algorithm almost always runs at 13-15 iterations per second, there are times when it runs at 3-5 iterations. This may be due to my hardware.