Week 3 - Balanceo del dataset
Exploracion de los datos
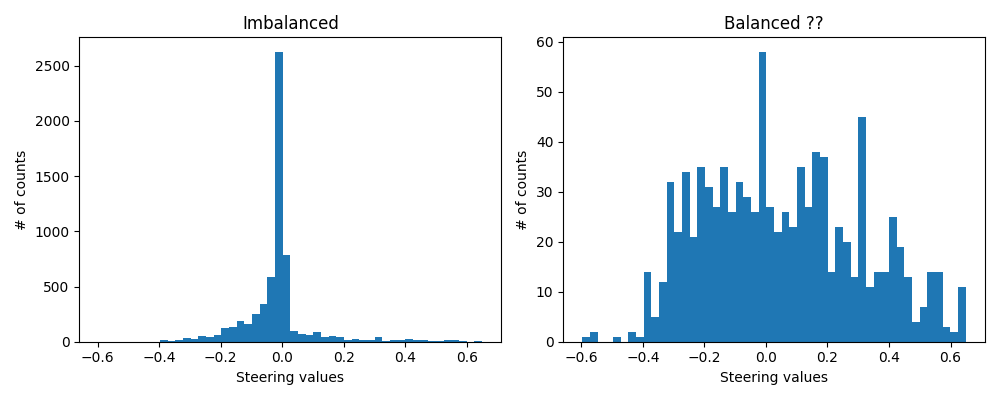
El dataset generado consta de un conjunto de 15.700 imágenes con sus respectivas etiquetas. Al representar los valores correspondientes al ángulo de giro (steer) en un histograma con 50 intervalos, se observa una distribución altamente desequilibrada.
histogram = plt.hist(df['steer_values'], bins=50)
plt.xlabel("Ángulo de giro")
plt.ylabel("# de Conteos")
plt.show(histogram)
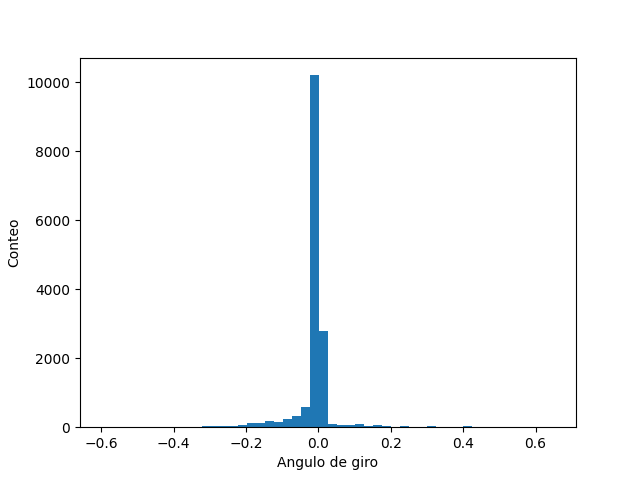
Como se aprecia en la imagen, la cantidad de valores cercanos al cero en el ángulo de giro supera los 10000 muestras, mientras que en los demás intervalos no se alcanza a superar los 100 valores. Esto indica que en la simulación predominó la conducción en línea recta. Si el modelo se entrena con estos datos, es probable que generalice este comportamiento y solo pueda predecir una dirección cero para todas las salidas, por lo tanto, no aprendería el mapeo correcto de la dirección de las imágenes.
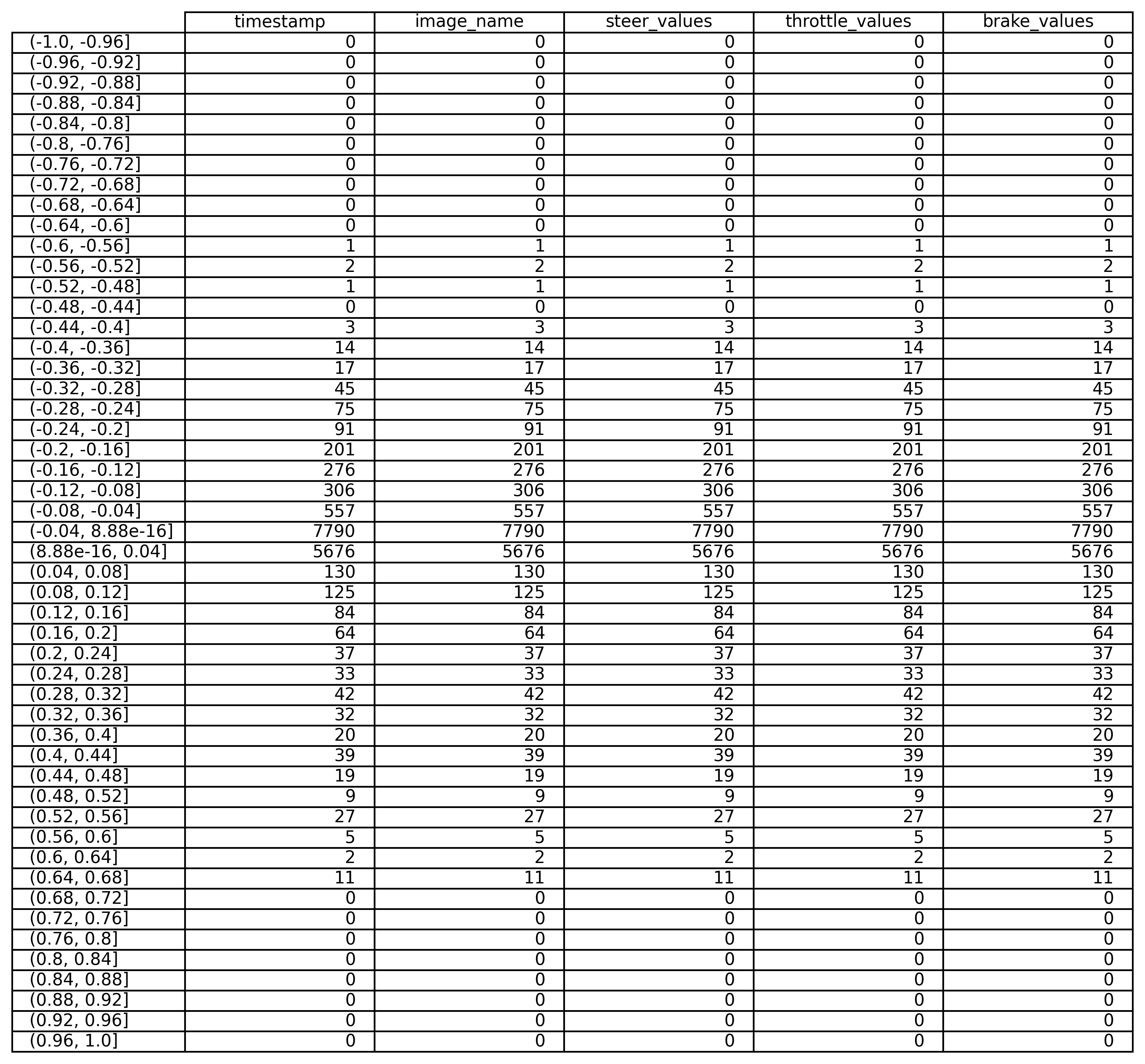
Para equilibrar el conjunto de datos, se empleó la técnica de submuestreo. Para ello, se dividió el conjunto de datos en 50 intervalos y se tomó el valor medio.
samples = 49
bin_width = 0.04
resampled = pd.concat([
part_df.sample(min(samples, part_df.shape[0]), random_state=1)
for small_r in np.arange(-1, 1.01, bin_width)
for part_df in [df[(df['steer_values'] >= small_r) & (df['steer_values'] < small_r + bin_width)]]
])
El resultado obtenido parece indicar una mejora con respecto a los datos originales. No obstante, es crucial entrenar el modelo para evaluar su rendimiento real. Existe la posibilidad de que aún presente sesgos en su desempeño, ya que podría lograr una alta precisión en una clase mayoritaria mientras que no proporciona información útil en las clases minoritarias.