Semana 10 - Graficando
Índice
Frecuencia en piloto experto
Para tener un mayor control en el funcionamiento del piloto experto, se analizó la frecuencia de publicación de velocidades y la subscripción a imágenes. Especialmente, esto se utilizó para comparar la ejecución del código cuando está grabando el ordenador y cuando está liberado.
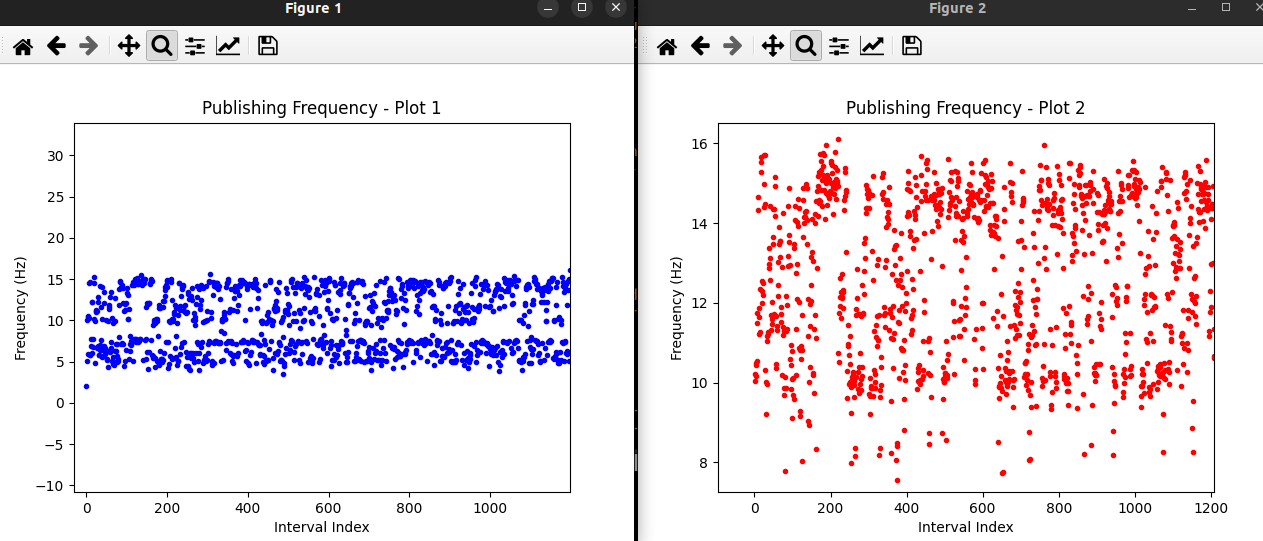
Podemos apreciar cómo la frecuencia ronda entre los 2 y 15 Hz, dejando una media de 10 Hz en la parte azul (Subscripción a la imagen).
En la parte roja, podemos ver la frecuencia de publicación donde, aunque se tenga algún repunte en torno a 8 Hz, las frecuencias se distribuyen con una media de 12.
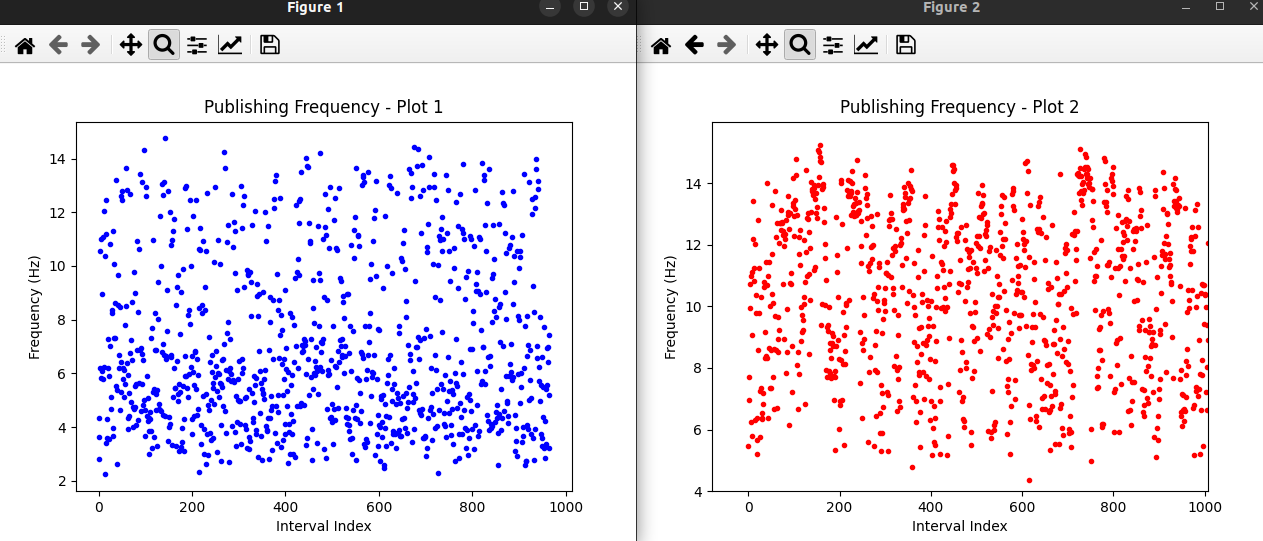
Cuando se está grabando, se puede ver una muy considerable dispersión en la distribución de los datos. Ya que el procesador del ordenador está más saturado, su rendimiento es mucho menor; sin embargo, el dron es capaz de realizar el circuito aunque un poco menos estable.
Profiling en piloto experto
También se comprobaron qué partes del código eran las que más procesamiento se llevaban. Con respecto al nodo de obtención de imagen, no se vio ninguna función que consumiera un tiempo excesivo. Sin embargo, en el nodo de control se encontró que la obtención de la velocidad angular, concretamente en el proceso por el que se calcula la media tanto en x como en y de los píxeles de la representación binaria de la línea, este proceso tarda 0.08 segundos cada vez que se realiza.
Para poder reducir su coste computacional, se pensaron varias opciones, entre ellas dejar al dron con un solo punto de referencia para que pueda ser más fiel al mismo (el más óptimo es la franja del más lejano). Reducir el tamaño de las franjas donde se comprueba para que se itere sobre menos píxeles o añadir un salto extra cuando el píxel sea negro, ya que todos los blancos estarán sobre el mismo área. A partir de este nuevo modelo se volvió a grabar otro dataset.
Gráficas del dataset
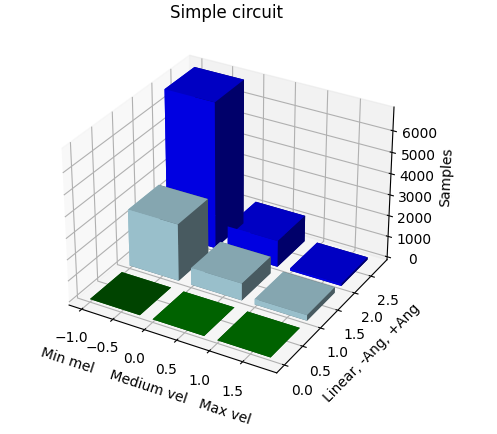
Las gráficas que se realizaron en semanas anteriores no eran del todo óptimas para visualizar la distribución del dataset, por lo que se crearon gráficas en 3D para mostrar de manera más clara dicha distribución. En este ejemplo se presenta la distribución de muestras en el primer circuito:
Otros avances adicionales para llegar a este dataset incluyeron el desarrollo de un programa que guardara las imágenes con sus respectivas etiquetas en carpetas separadas, en lugar de obtenerlas directamente para el entrenamiento. Otro problema encontrado fue que al recibir las imágenes directamente del tópico de la cámara, estas se obtenían a una frecuencia mayor que las velocidades. Para compensar esto, se relacionó el sello temporal de las velocidades y de las imágenes para guardar una imagen por cada velocidad publicada. En caso de que el dataset resultara reducido, se podría optar por guardar las dos imágenes más cercanas para cada velocidad.
Balanceo del dataset
En implementaciones anteriores, el dataset se almacenaba en una lista con cada etiqueta asociada a su respectiva imagen, y aumentar la longitud de estas listas equilibraba el dataset mediante oversampling. Se investigaron varias herramientas que pudieran realizar esta tarea de manera más eficiente:
- Resampling o undersampling con scikit-learn
- Generación de datos sintéticos con SMOTE
- Otras herramientas especializadas
La mayoría de los lugares donde se buscó información recomendaban o utilizaban imblearn. Además, también se encontró la técnica de undersampling, cuya función es evitar entrenar la red con muchas muestras repetidas para intentar prevenir el sobreentrenamiento.
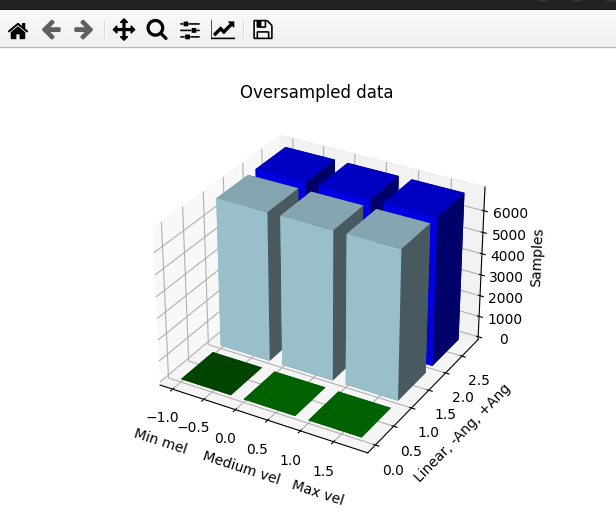
Finalmente utilizando RandomOverSampler de la librería imblearn.over_sampling se consiguió el siguiente dataset: