Semana 13 - Comparando soluciones
En esta semana se desarrolló una manera de cuantificar cuán buena es cada solución para el problema y qué resultados aporta.
Índice
Balanceo del dataset
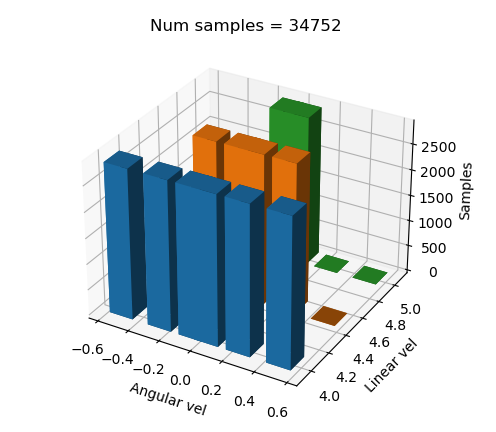
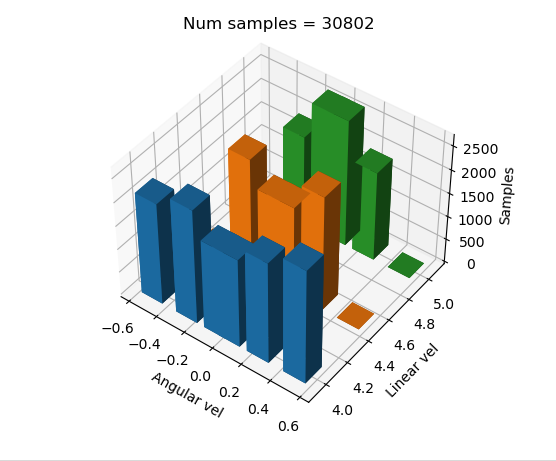
Se terminó de balancear el dataset para que, a nivel de código, se tuviera una manera mucho mejor de poner etiquetas y, a su vez, modificar estas mismas si era necesario. Quedando la gráfica de la siguiente manera:
Lo primero que se hace es balancear todas las etiquetas al mismo número de muestras para posteriormente submuestrear en un porcentaje concreto cada label, así dejando los ejemplos menos frecuentes con un número de muestras menor, dejando un dataset más óptimo para entrenar y más manejable.
Gráfica de posición
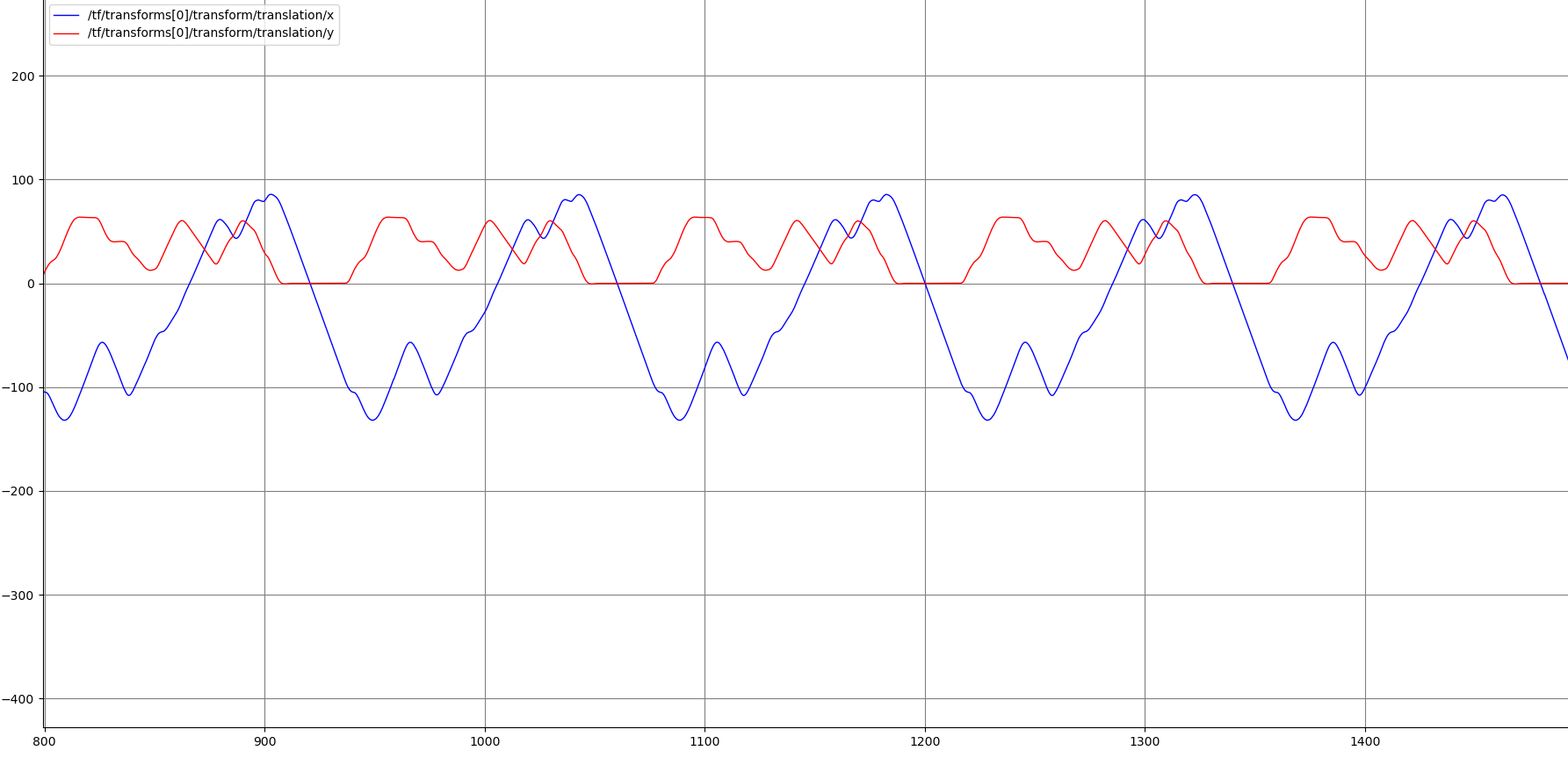
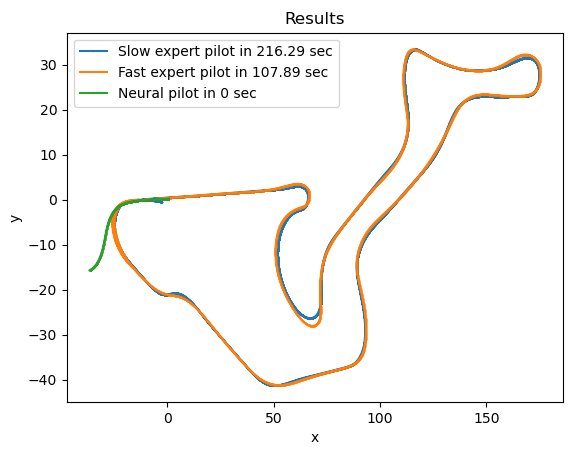
Para comparar soluciones, lo siguiente fue crear una gráfica donde se mostraran el eje x y el eje y. Primero necesitaríamos un dron que siguiera la línea a la perfección para luego comparar el resto de soluciones. Hay varios topics de donde podemos obtener la posición, pero se decidió sacar directamente de la tf del dron, ya que es el más fiable en este caso y su utilidad es comparar resultados.
También se investigó cómo calcular el error entre ambas gráficas. Los principales métodos que se encontraron fueron:
- Error Cuadrático Medio (MSE - Mean Squared Error)
- Error Absoluto Medio (MAE - Mean Absolute Error)
- Raíz del Error Cuadrático Medio (RMSE - Root Mean Squared Error)
- Error Cuadrático Medio Normalizado (NMSE - Normalized Mean Squared Error)
- Coeficiente de Correlación (por ejemplo, Pearson)
- Índice de Similitud de Fréchet
A la hora de grabar rosbags se modificó el comando de la siguiente manera:
# En la carpeta drone_driver/training_dataset
timeout 240s ros2 bag record -o folderName /drone0/self_localization/twist /drone0/sensor_measurements/frontal_camera/image_raw /tf
Esta modificación se realizó porque el anterior topic que monitorizaba las velocidades lo hacía con velocidades relativas al tf global del mapa y por eso no se ajustaban bien. Además, se graba también el topic de las tfs para poder comparar la precisión de la ruta en las distintas ejecuciones.
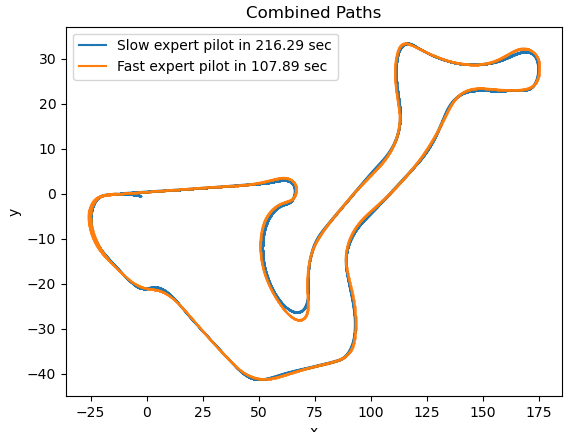
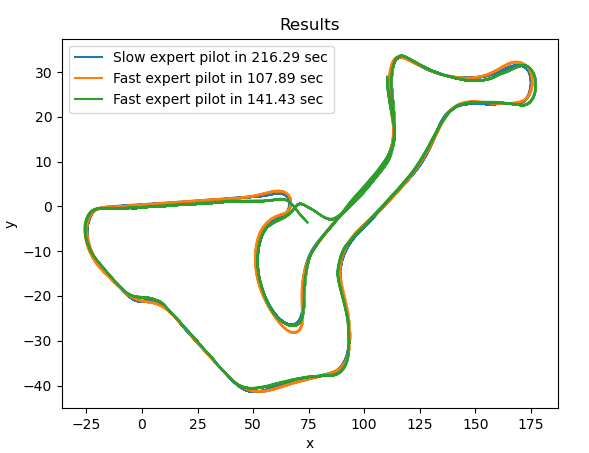
El siguiente paso fue graficar el circuito donde se realizarán los test. Primero se hizo con un piloto experto lento para tener más detalle del circuito y luego con el piloto externo que se está usando para generar el dataset de la red. Mostrando además el tiempo de vuelta y juntando los ejes X e Y para que las gráficas fueran más claras. Dando el siguiente resultado:
Una vez solucionados estos problemas, se volvió a empezar a generar otro dataset. Ahora estos se irán etiquetando y guardando para comparar soluciones.
Dataset 1
Se conservaron los parámetros de la semana pasada, pero con los problemas que se tuvieron en la misma solucionados
Dataset desbalanceado

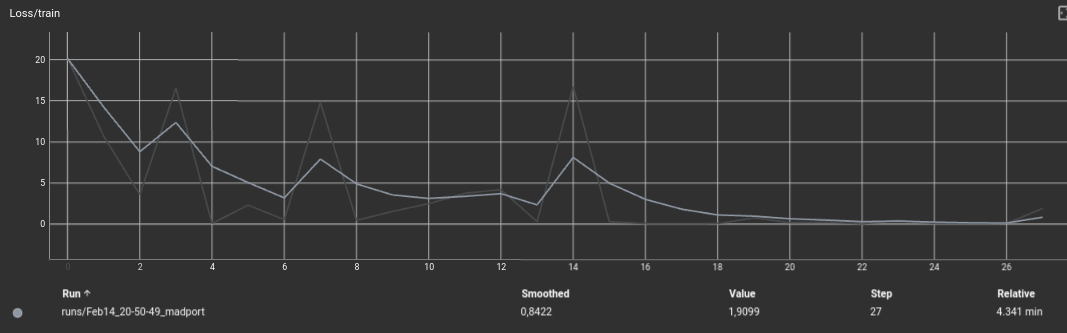
Se paró el entrenamiento ya que a partir del epoch 23 la red neuronal se podría estar sobreentrenando.
Dando el siguiente resultado:
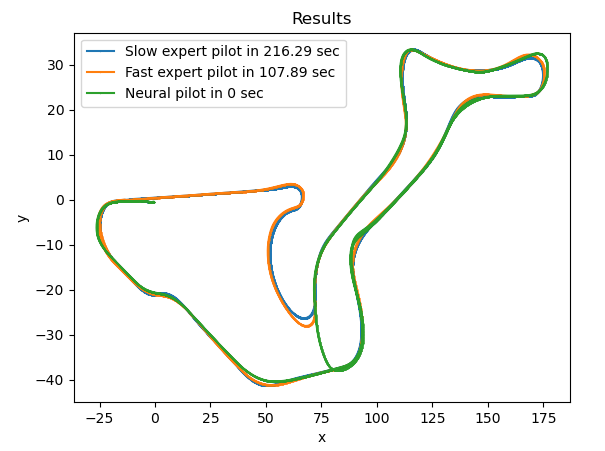
Podemos ver cómo en las curvas menos pronunciadas no tiene un suficiente número de muestras, por lo que el dron no llega a realizar la curva ni a completar el circuito.
Dataset totalmente balanceado
Dando el siguiente resultado:
Dataset parcialmente balanceado
La matriz de pesos es la siguiente:
# < 4.5 5 inf
weights = [ (1.0, 0.5, 0.4), # < -0.5
(0.7, 1.0, 0.8), # < -0.25
(0.3, 0.7, 1.0), # < 0
(0.3, 0.7, 1.0), # < 0.25
(0.7, 1.0, 0.8), # < 0.5
(1.0, 0.5, 0.4)] # < inf
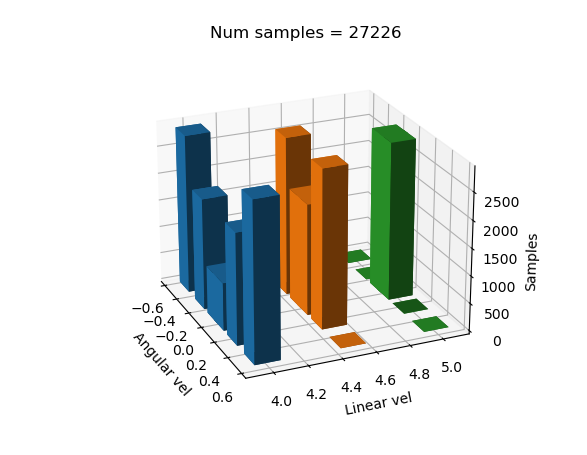

Dando el siguiente resultado:
Se vio que se tenían avances significativos, pero no eran suficientes ya que no se conseguía completar el circuito.
Etiquetado 2
Primero se pensó en que la solución podría estar en que no había suficientes etiquetas, por lo que se añadieron 2 etiquetas angulares más para tener en cuenta también los casos más extremos.
Dataset desbalanceado
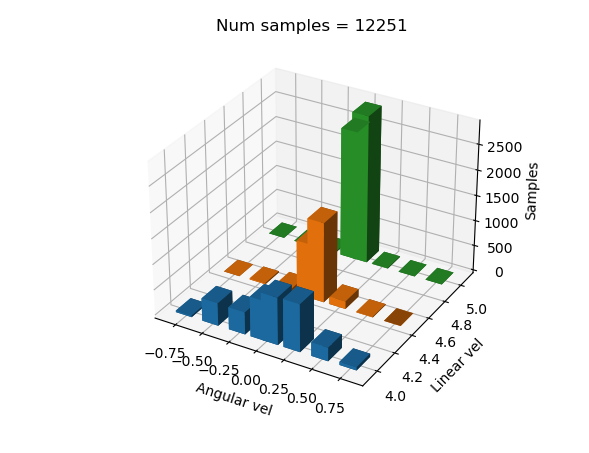
Dando el siguiente dataset semibalanced:
# < 5 5.5 inf
weights = [(0.40, 0.0, 0.0), # < -1.5
(0.50, 0.3, 0.0), # < -0.6
(0.60, 0.5, 0.7), # < -0.3
(0.70, 0.8, 0.99), # < 0
(0.70, 0.8, 0.99), # < 0.3
(0.60, 0.5, 0.7), # < 0.6
(0.50, 0.3, 0.0), # < 1.5
(0.40, 0.0, 0.0)] # < inf
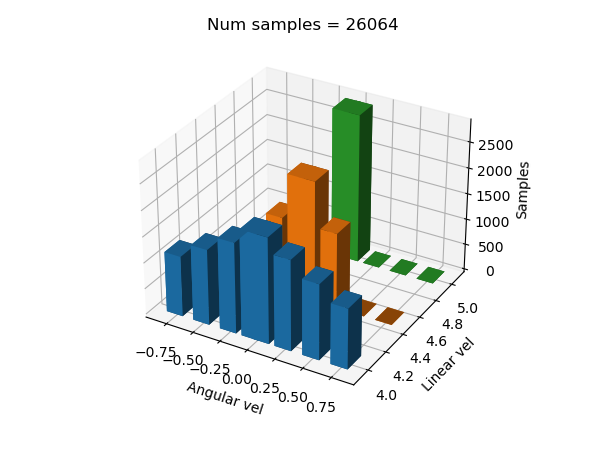
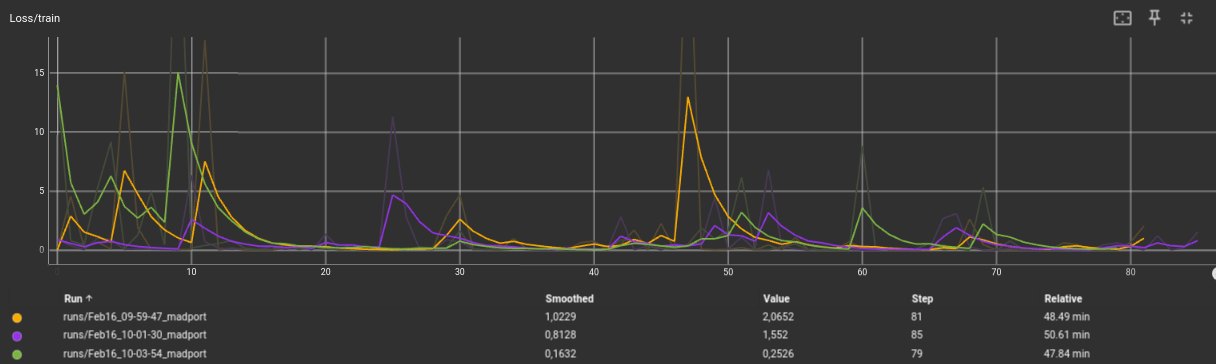
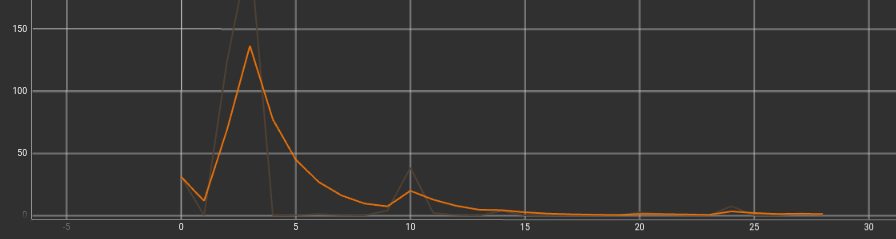
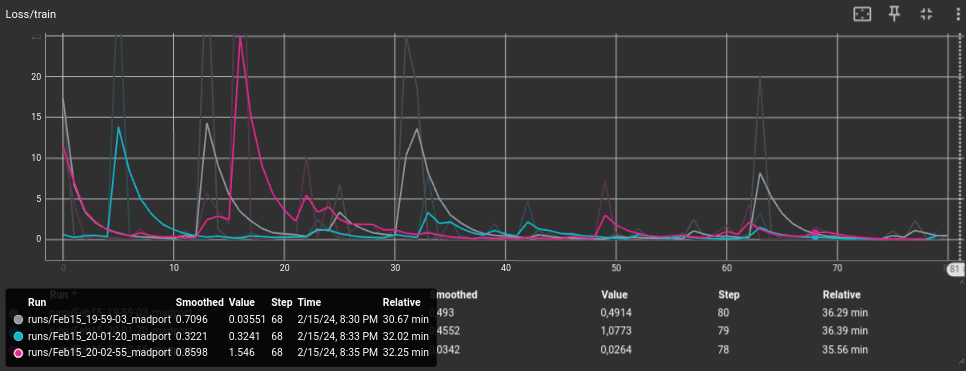
El siguiente presentimiento fue que tal vez con 30 epochs la red neuronal no era capaz de aprender adecuadamente. A partir de esta misma distribución de dataset, se hicieron pruebas con 3 tamaños de batch distintos: 4, 20 y 100. El tiempo de convergencia fue parecido, aunque el resultado fue sin duda por parte de epoch = 4:
- Naranja: Epoch = 4
- Morado: Epoch = 20
- Gris: Epoch = 100
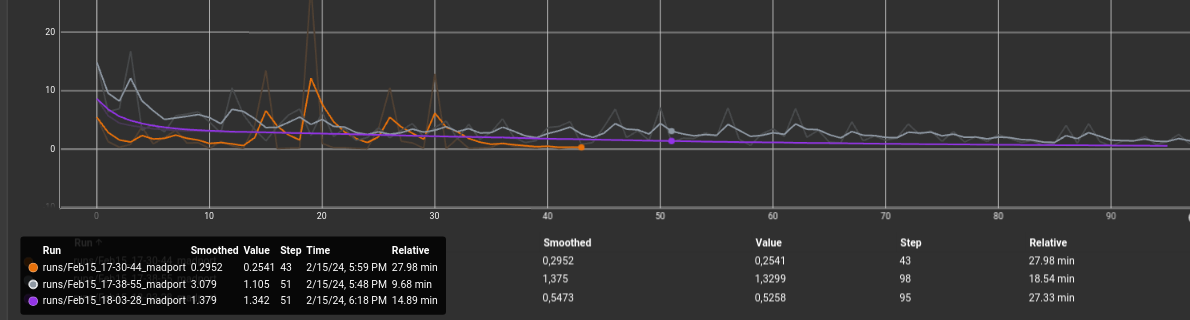
Además, hay que destacar que la media de frecuencia de publicación era en torno a 30 Hz.
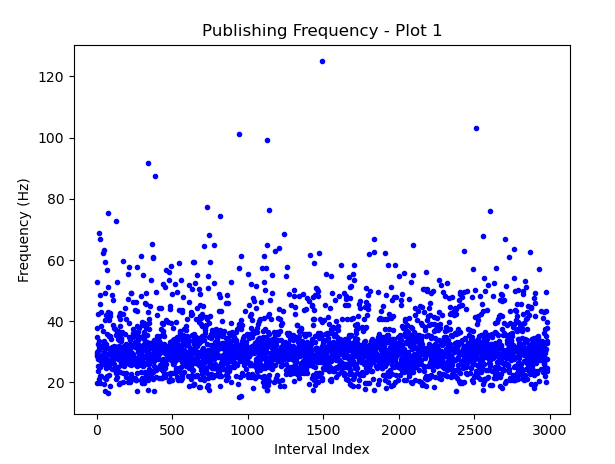
Entrenamiento simultáneo
Dado que ahora el entrenamiento lleva más tiempo y, en algunas ocasiones, se pueden esperar hasta 20 minutos para que el dron falle en la primera curva, se decidió realizar la prueba de entrenar el modelo simultáneamente con varias distribuciones de dataset para posteriormente analizar todos los resultados de una manera más clara
Distribución 1:
Todas las etiquetas perfectamente equilibradas
# < 5 5.5 inf
weights = [(0.99, 0.99, 0.99), # < -1.5
(0.99, 0.99, 0.99), # < -0.6
(0.99, 0.99, 0.99), # < -0.3
(0.99, 0.99, 0.99), # < 0
(0.99, 0.99, 0.99), # < 0.3
(0.99, 0.99, 0.99), # < 0.6
(0.99, 0.99, 0.99), # 1.5
(0.99, 0.99, 0.99)] # < inf
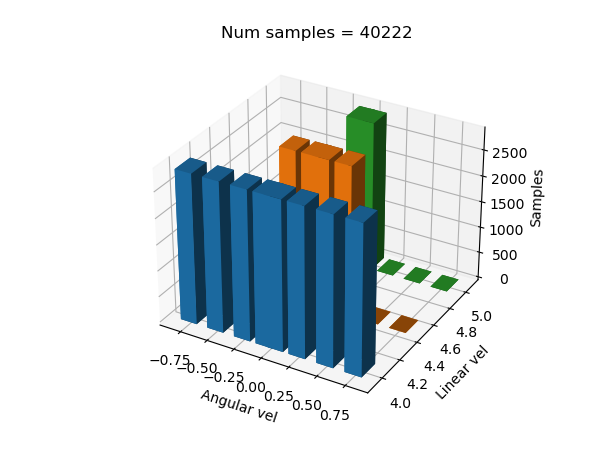
Distribución 2:
Etiquetas ligeramente desequilibradas
# < 5 5.5 inf
weights = [(0.80, 0.0, 0.0), # < -1.5
(0.60, 0.7, 0.0), # < -0.6
(0.70, 0.8, 0.8), # < -0.3
(0.70, 0.99, 0.99), # < 0
(0.70, 0.99, 0.99), # < 0.3
(0.60, 0.8, 0.8), # < 0.6
(0.70, 0.7, 0.0), # < 1.5
(0.80, 0.0, 0.0)] # < inf
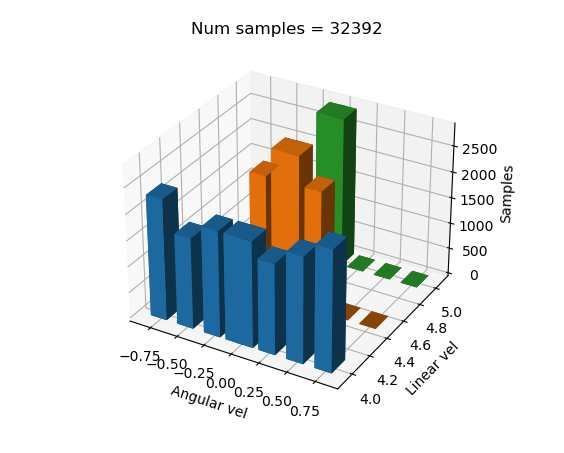
Distribución 3:
Etiquetas muy desequilibradas
# < 5 5.5 inf
weights = [(0.80, 0.0, 0.0), # < -1.5
(0.60, 0.5, 0.0), # < -0.6
(0.70, 0.6, 0.6), # < -0.3
(0.40, 0.7, 0.99), # < 0
(0.40, 0.7, 0.99), # < 0.3
(0.60, 0.6, 0.6), # < 0.6
(0.70, 0.5, 0.0), # < 1.5
(0.80, 0.0, 0.0)] # < inf
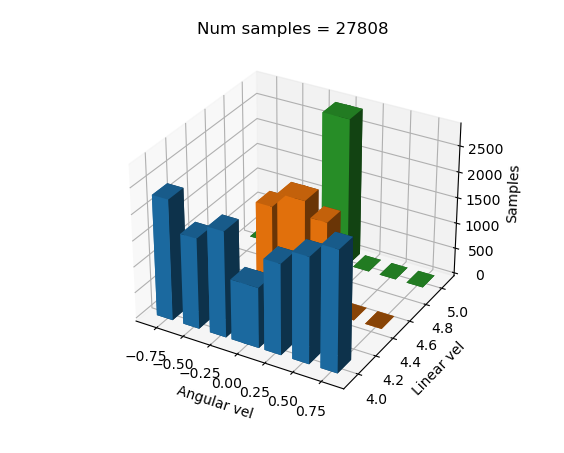
Resultado
Aparentemente, el entrenamiento se realizó bien, pero a la hora de probarlo, los tres dieron malos resultados.
Paso atrás
Dado que con la etiqueta “mas” no se lograron los resultados esperados, se intentó volver al etiquetado inicial y usar la misma técnica. Con los siguientes valores angulares: ANGULAR_UMBRALS = [-0.3, -0.1, 0, 0.1, 0.3, float(‘inf’)]
Distribución 1:
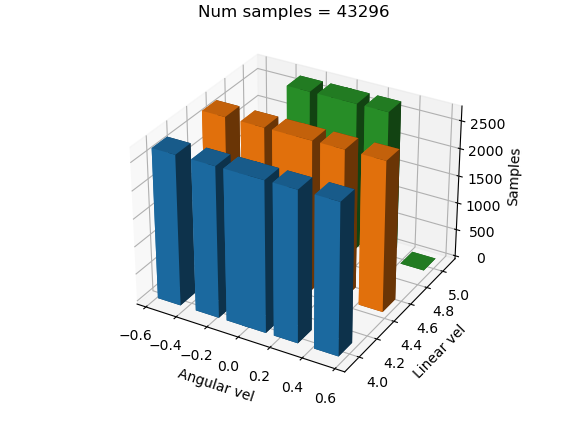
Distribución 2:
# < 5 5.5 inf
weights = [(0.80, 0.0, 0.0), # < -0.3
(0.90, 0.7, 0.4), # < -0.1
(0.50, 0.5, 0.99), # < 0
(0.50, 0.5, 0.99), # < 0.1
(0.80, 0.7, 0.4), # < 0.3
(0.90, 0.0, 0.0)] # < inf
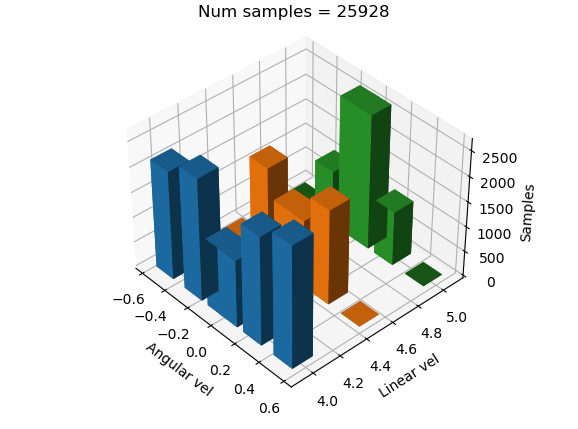
Distribución 3:
# < 5 5.5 inf
weights = [(0.80, 0.0, 0.0), # < -0.3
(0.90, 0.9, 0.7), # < -0.1
(0.70, 0.7, 0.99), # < 0
(0.70, 0.7, 0.99), # < 0.1
(0.80, 0.9, 0.7), # < 0.3
(0.90, 0.0, 0.0)] # < inf
Los resultados tampoco mejoraron; al analizar el comportamiento del piloto experto, en curvas cerradas hay picos de 3 en frames muy específicos, esto podría ser el motivo por el cual el dron falla.