
Semana 14 - Oversample de dataset
Índice
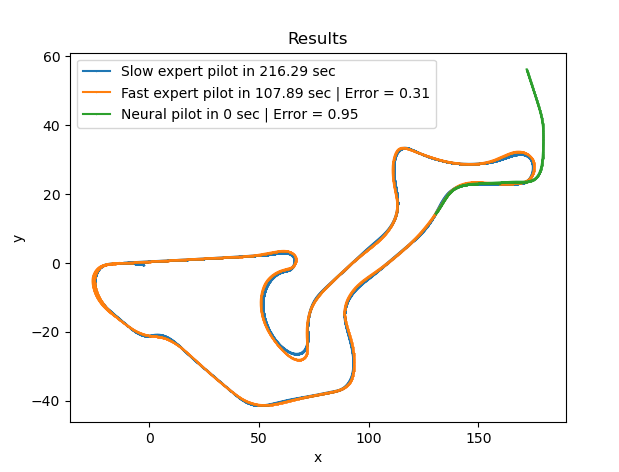
Cuantificación del error
Lo primero que se hizo esta semana fue cuantificar el error en ambos recorridos. Para esto, primero se encuentra el punto más cercano de la ruta de referencia al primer punto de la ruta a la cual se quiera calcular el error.
Una vez conseguido este punto, se recorrerá la segunda ruta y se calculará la distancia euclidiana con el punto equivalente de la ruta de referencia. Para evitar errores, se añadió una holgura de 5 puntos a la hora de comparar puntos de la ruta de referencia. El error será la distancia mínima entre estos 5 puntos y se pasará al siguiente.
Gráfica del dataset
Me encontré con una publicación que hablaba sobre la importancia de la normalización del dataset para el correcto aprendizaje, lo que me dio la idea de graficar de manera diferente las velocidades para ver de otra forma la distribución del dataset y así quizás definir de manera más óptima las etiquetas, permitiendo además un mejor análisis del dataset y su distribución.
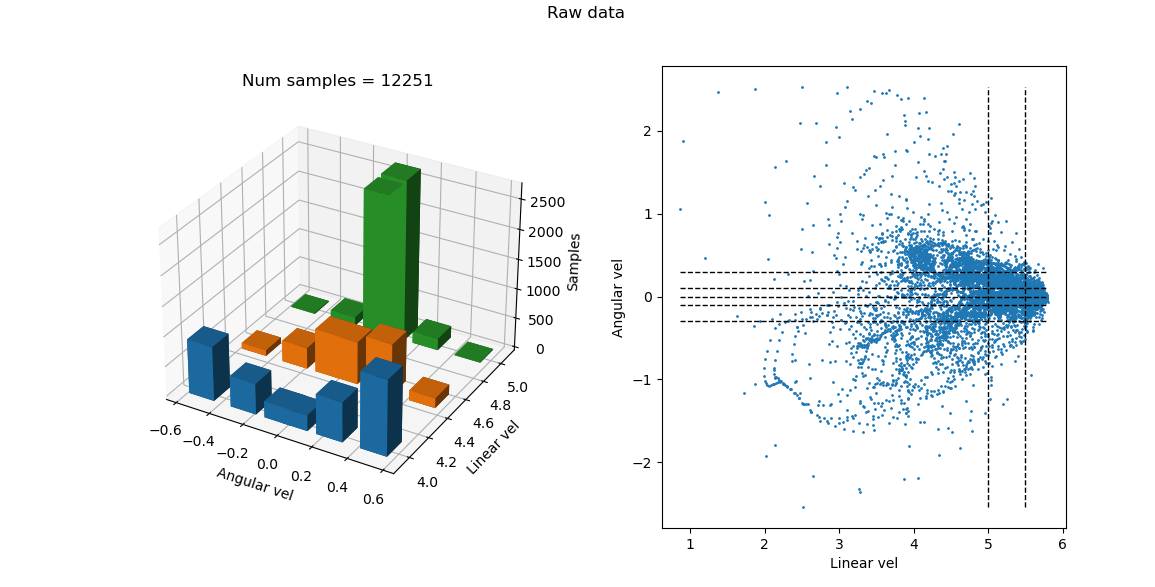
Con esta gráfica, podemos ver la distribución de los datos y etiquetas de una manera más clara. Además, a la hora de sobremuestrear, esta gráfica podría ser muy útil.
La siguiente modificación fue hacer que se mostraran las gráficas en la misma ventana para comparar de una manera más sencilla:
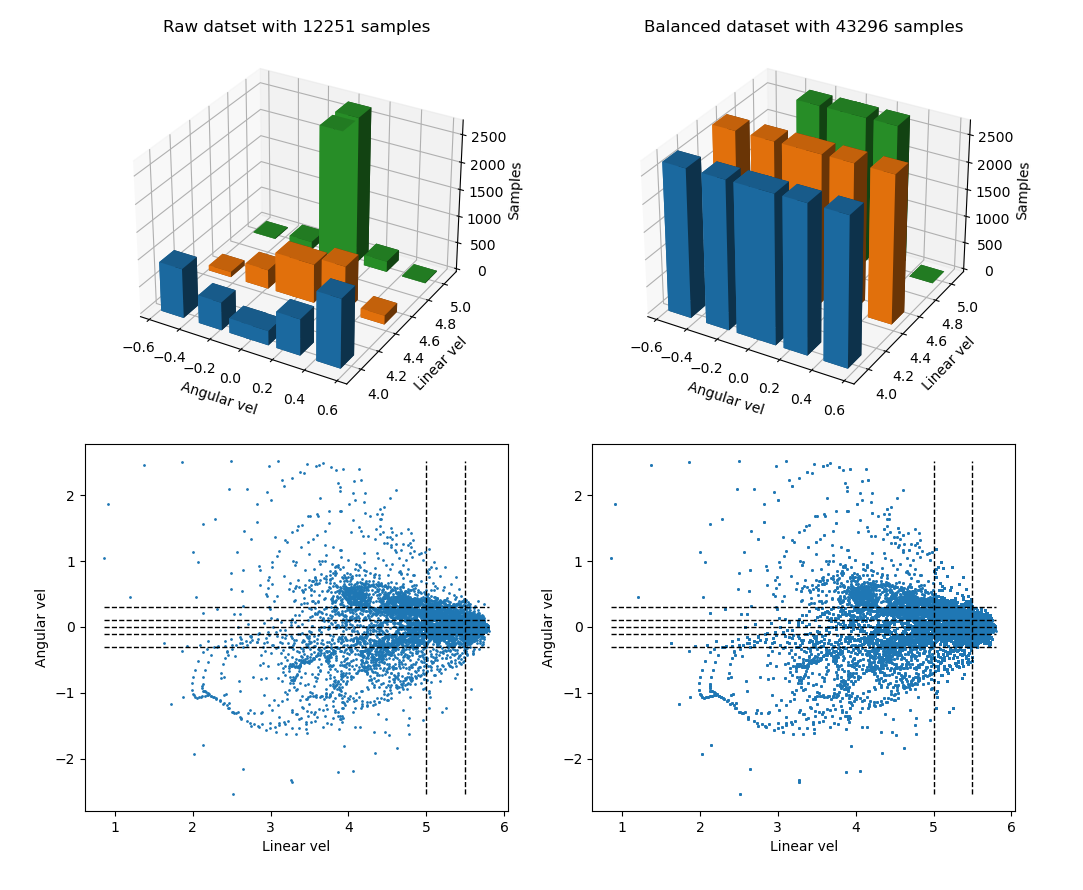
De esta manera, no solo podemos comparar operaciones sobre el dataset, sino que podremos comparar varios datasets.
Aumentación de datos
Lo siguiente fue aplicar la técnica de aumentación. En el caso de imágenes, se suele utilizar:
- Transformaciones geométricas
- Cambios en el espacio de color
- Filtros de kernel
- Eliminación de partes aleatorias
- Combinación de imágenes
- Cambio de perspectiva
- Deformaciones elásticas
- Mirroring (Varios tipos de vueltas)
Para la implementación, me parecieron interesantes:
- Transformaciones geométricas desplazando lateralmente la imagen para la velocidad angular y verticalmente para la velocidad lineal.
- Cambios en el espacio de color también es una técnica interesante, especialmente en contrastes.
- Mirroring: si tenemos una curva, podremos hacerla espejo e invertir la velocidad angular.
Ahora graficamos los resultados. Podemos ver que algunas columnas se igualan debido a las imágenes espejo y que, en algunos casos, las medidas se centran más en los límites que deberían, como las velocidades lineales con giro 0. También vemos que los casos más repetidos se condensan más, pero que tenemos más casos raros a la vez. Esto sin tener en cuenta los cambios de imagen, los cuales aquí no podemos añadir como datos, ya que solo se tienen en cuenta las velocidades.
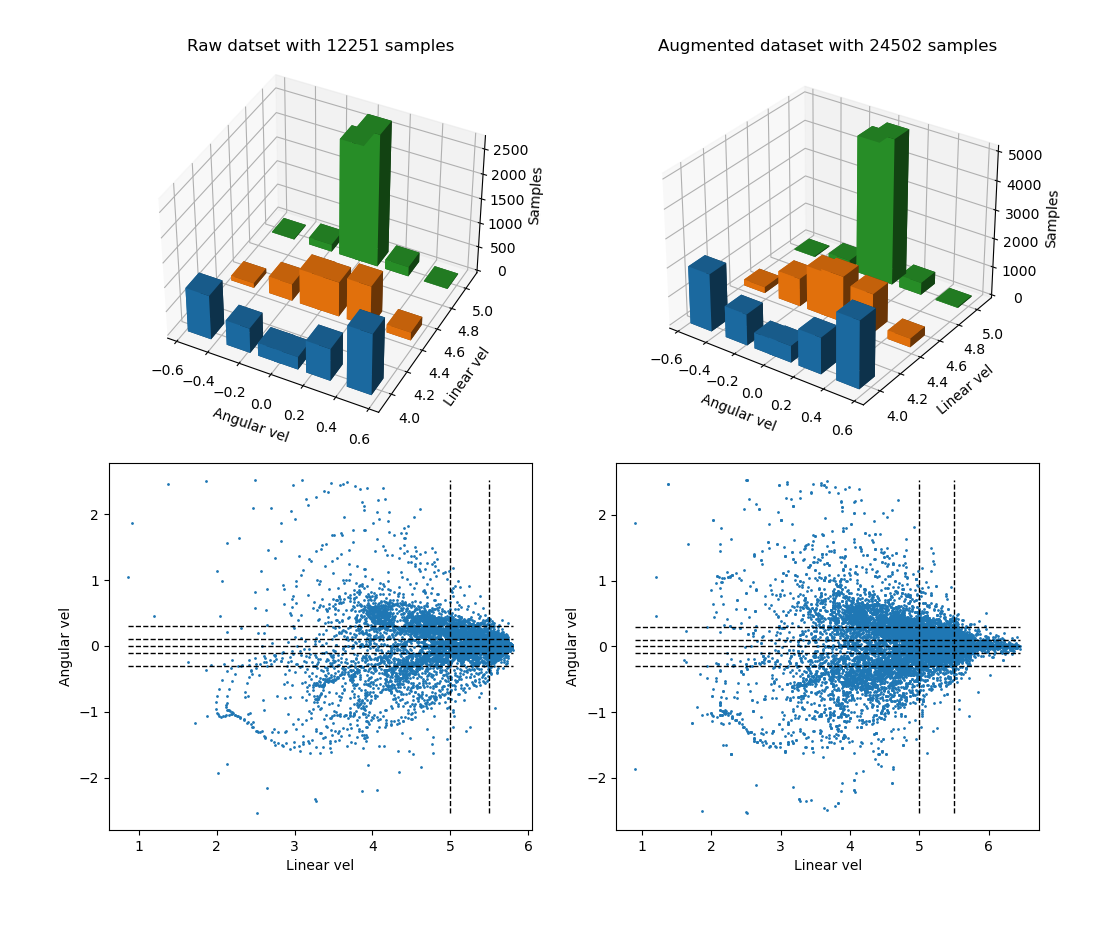
Pruebas con el dataset aumentado
Se procedió a realizar pruebas con el dataset actual para ver si se conseguía completar el circuito, pero los resultados fueron negativos. Esto nos da la lección de que la distribución de los datos es crucial y de tener un buen dataset.