
Semana 4 - Semana de lectura
En esta semana nos dedicamos a un contexto más teórico, aunque paralelamente, seguimos tratando de “domesticar” el drone con AeroStack2.
Index
- TFM Deeplearning-autonomous_driving
- DeepPilot: A CNN for Autonomous Drone Racing
- Aerostack2
- Conducción autónoma de un vehículo en simulador mediante aprendizaje extremo a extremo basado en visión
TFM Deeplearning-autonomous_driving
Primero, empezamos leyendo el (TFM, DE Enrique Shinohara)[https://gsyc.urjc.es/jmplaza/students/tfm-deeplearning-autonomous_driving-enrique_shinohara-2023.pdf] que presenta un enfoque de aprendizaje profundo en conducción autónoma con redes neuronales de extremo a extremo. Nos será especialmente útil, ya que también utilizaremos la red neuronal PilotNet como primera aproximación a nuestro proyecto.
-
Un enfoque interesante está en el proyecto de Felipe Codevilla “End-to-end driving via conditional imitation learning”, donde se entrena un vehículo con un enfoque extremo a extremo, donde la percepción y la toma de decisiones la realiza una arquitectura de redes neuronales, con la peculiaridad de que se pueden introducir comandos desde fuera.
-
PilotNet: Consta de 9 capas, las cuales incluyen una capa de normalización, 5 capas convolucionales y 4 capas de redes neuronales totalmente conectadas o densas.
-
Otro aspecto interesante es cómo se incorpora la capa de velocidades previas junto al modelo.
-
Reducción y redimensión de píxeles en la imagen para agilizar el entrenamiento, además de tener en cuenta la forma de equilibrar los datos de la manera correcta.
-
Albumentation: Biblioteca que se utiliza durante el entrenamiento con el fin de aumentar la variedad del conjunto de datos permitiendo cambiar la iluminación, desenfocarla o añadir condiciones temporales.
DeepPilot: A CNN for Autonomous Drone Racing
El fundamento de esta CNN (Convolutional Neural Network) es que recibe imágenes de la cámara del drone y predice 4 órdenes de vuelo que representan la posición angular del drone en yaw, pitch y roll, y la componente vertical de la velocidad, refiriéndose a la altitud.
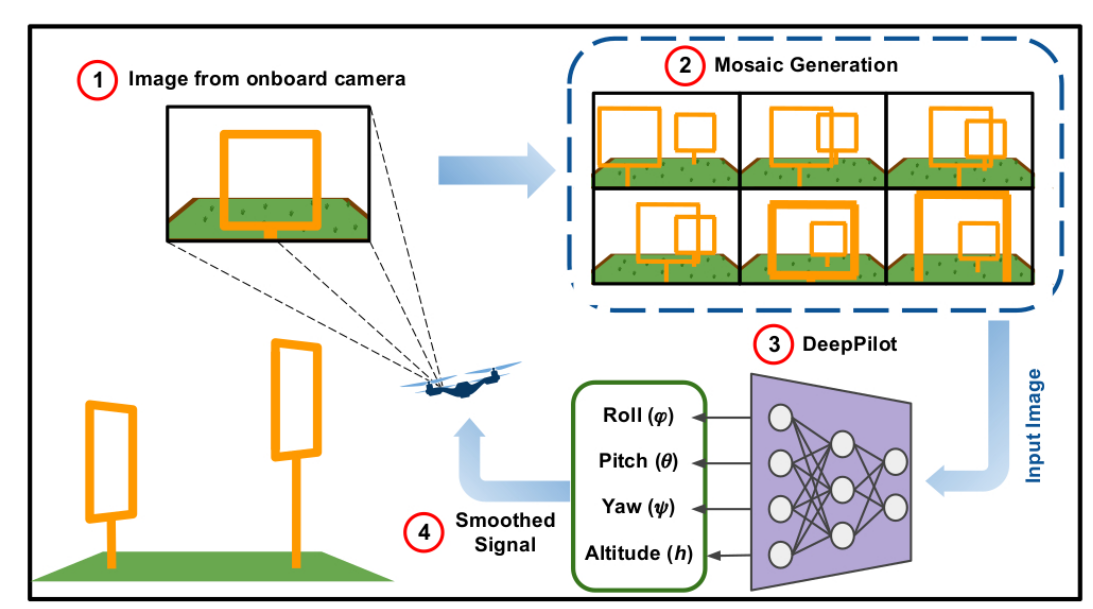
También se plantea el uso de imágenes consecutivas como entrada, para añadir una tendencia de movimiento y reducir el número de capas. Primero se hace una aproximación con 1 frame, pero haciendo pruebas con 2, 4, 6 y 8 frames se observa que al añadir más frames a la entrada, se actúa con un proceso de memoria, ya que contienen una tendencia de movimiento.
Otro aspecto importante es que se desacoplan yaw y la altitud de pitch y roll. Esta idea está basada en redes que trabajan con VisualSLAM y odometría.
-
(Datasets de entrenamiento para modelo DeepPilot)[https://github.com/QuetzalCpp/DeepPilot.git]
-
También se presentan varios algoritmos donde los drones completaron las pruebas de la IROS Autonomous Drone Racing 2017. Un aspecto importante a tener en cuenta en el diseño del software de un dron es que simultáneamente hay que considerar la localización, la detección, el control y el cálculo de la ruta o path planning.
-
Otros tipos de CNN se dividen en 2 submódulos: una red se encarga de procesar las imágenes como entrada y devuelve una lista de puntos, y la segunda tendrá como entrada estos puntos y devolverá las velocidades.
Framework propuesto:
- Adquirir la imagen del drone.
- Generar una imagen mosaico con cada 5 frames.
- Predecir los comandos de vuelo con DeepPilot.
- Implementar un filtro de salida para suavizar los comandos de vuelo.
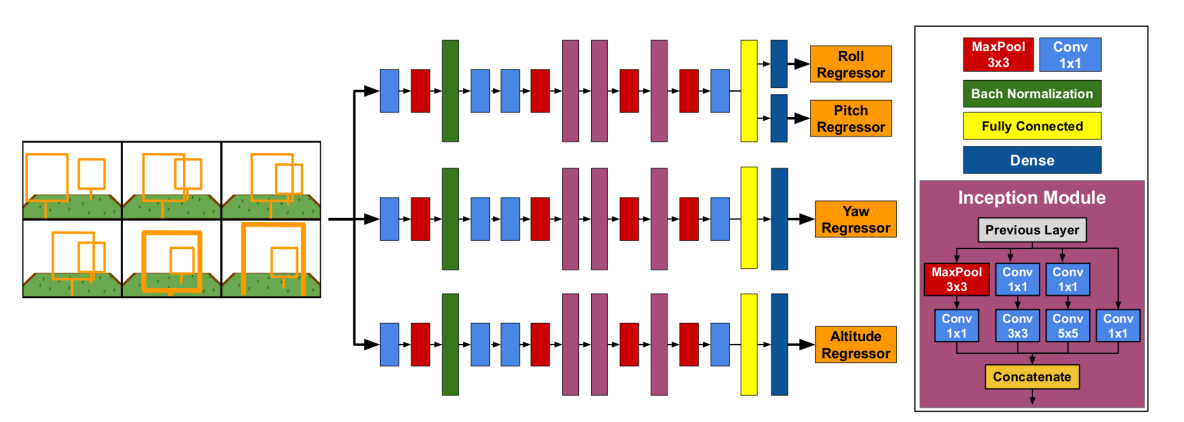
Arquitectura DeepPilot: Se basa en tener 3 modelos que corren paralelamente, uno para pitch y roll, otro para yaw y otro para la altitud. Debido a la flexibilidad de Keras y TensorFlow, se pueden ejecutar a la vez estos 3 modelos con la misma arquitectura (la única diferencia serán los pesos). Cada rama tendrá 4 capas convolucionales, 3 módulos de intercepción, 1 capa totalmente conectada y 1 capa de regresión. Cuando se entrena esta red neuronal, a cada módulo se le pasa un conjunto de datos donde el movimiento predominante sea el que se quiere entrenar.
- Filtro de ruido: El filtro EMA ayuda a reducir el ruido de la predicción a la vez que previene oscilaciones y sacudidas.
- Resultados de comparación de Deepilot vs PoseNet:
Conducción autónoma de un vehículo en simulador mediante aprendizaje extremo a extremo basado en visión
Volveremos a leer de nuevo el TFM de Vanessa Fernández Martínez pero nos centraremos en los apartados relativos a redes neuronales. Y lo resumiremos de una manera más detallada.
Tipos de redes neuronales básicos
Redes Neuronales Convolucionales (CNN):
Principalmente se utilizan para clasificar imágenes, agrupar estas imágenes por similitud y realizar el reconocimiento de objetos dentro de las escenas. Estas redes se basan en la corteza visual del cerebro humano y aplican una serie de filtros para extraer características de nivel superior. Por lo general, están compuestas por varias capas, incluyendo capas convolucionales, capas de agrupación y capas completamente conectadas (fully connected).
Redes Neuronales Recurrentes (RNN):
Su idea es utilizar información secuencial en lugar de información independiente. Este tipo de red neuronal aprende a emplear información pasada en casos donde esa información es relevante, funcionando a modo de memoria a corto plazo.
Redes de regresión
Su objetivo es predecir el valor real, gradual y continuo de una variable numérica en función de los valores de una o varias variables independientes. Esta regresión puede mostrar si existe una relación significativa entre las variables independientes y la variable dependiente.
Redes Neuronales Long Short-Term Memory (LSTM):
Son capaces de aprender dependencias a largo plazo.
Tipos de capas en redes neuronales
Capa Convolucional:
Recibe como entrda una imagen y aplica a la misma un kernel que devuelve un mapa de características, reduciendo el tamaño de los parámetros. Después de aplicar esta capa, se aplica una función de activación a los mapas de características, la mas usada suele ser la ReLU.
Además hay varios parámetros que deberíamos tener en cuenta:
- Dimensiones en los filtros de convolución: Matriz de tamaño (M x M).
- Número de filtros de convolución: Determina la profundidad del volumen de salida, cada filtro genera un mapa de características.
- Stride: Determina cuánto vamos a deslizar el filtro sobre la matriz de entrada.
- Padding: Añade alrededor de la matriz de entrada ceros para evitar perder dimensiones tras la convolución.
Capa de Pooling:
Se emplea para reducir dimensiones espaciales. Su funcionamiento se basa en una ventana deslizante que actúa sobre el volumen de la entrada. Las clases de submuestreo más empleadas son:
- Max pooling: Se queda con los valores máximos de la ventana deslizante.
- Average pooling: Calcula cada píxel del volumen de salida realizando el promedio de píxeles que se encuenta dentro de una ventana.
Capa fully connected:
Conectan cada neurona de la capa de entrada con cada neurona de la capa de salida con un peso asignado a cada conexión.
Capa LSTM
Puede añadir o quitar información a partir de estructuras denominadas puertas. Hay tres tipos de ellas
- Forget gate: Decide que información se desecha.
- Input gate: Decide qué valores se deben actualizar.
- Unidad de salida.
Redes neuronales para conducción autónoma
PilotNet:
Como estudiamos en documentos anteriores, consta de 9 capas, que incluyen una capa de normalización, 5 capas convolucionales y 3 capas fully-conected o densas. Si seguimos leyendo, podemos notar cómo se entra más en profundidad en la arquitectura. Las 2 primeras capas convolucionales usan un stride de 2x2 y un kernel de 5x5, mientras que las 3 últimas no tienen stride y poseen un kernel de 3x3.
Las 3 capas fully-connected fueron diseñadas para funcionar como un controlador de dirección, pero no es posible saber exactamente qué partes actúan como tal.
Las activaciones de los mapas de nivel superior se convierten en máscaras para las activaciones de niveles inferiores utilizando el siguiente algoritmo:
- En cada capa, las activaciones de los mapas de características se promedian.
- El mapa con el promedio más alto se escala según el tamaño del mapa de la capa de abajo.
- El mapa promediado aumentado de un nivel superior se multiplica después con el mapa promediado de la capa de abajo, lo que resulta en una máscara de tamaño intermedio.
- La máscara intermedia se escala al tamaño de los mapas de la capa inferior de la misma manera que en el paso 2.
- El mapa intermedio mejorado se multiplica nuevamente con el mapa promediado de la capa de abajo.
- Los pasos 4 y 5 se repiten hasta que se alcanza la entrada. La última máscara, que tiene el tamaño de la imagen de entrada, se normaliza a un rango de 0-1 y se convierte en la máscara de visualización final.”
Este proceso hará que PilotNet aprenda a reconocer objetos relevantes en la carretera y sea capaz de mantener el vehículo en un carril con éxito.
TinyPilotNet
Se compone de una capa de entrada que recibirá imágenes de 16x32 en un único canal. La imagen pasará por 2 capas convolucionales y una capa de dropout. Finalmente, el tensor pasa a dos capas fully-connected que predicen los valores de dirección y aceleración, respectivamente.
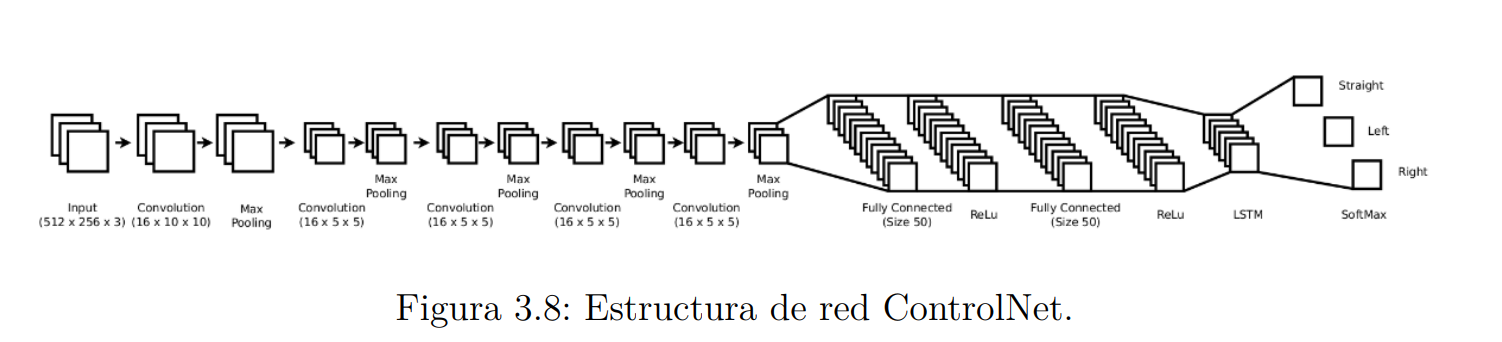
ControlNet
Arquitectura de red simple que requiere pocas imágenes de entrenamiento. Su arquitectura consiste en alternar capas convolucionales con capas de maxpooling seguidas de capas fully-connected. Además, posee una capa LSTM que permite incorporar información temporal, lo que le permite continuar moviéndose en la misma dirección a lo largo de varios fotogramas.
Variación de PilotNet
En “From pixels to actions: Learning to drive a car with deep neural networks” se estudia la inclusión de capas recurrentes; se añaden capas LSTM que permiten información temporal en entradas consecutivas. Todos los experimentos realizados con estas redes demostraron que la incorporación de estas capas no aumentó ni redujo el rendimiento de la red.
LeNet5
Consta de 3 capas convolucionales. Entre estas capas se aplica una capa de submuestreo (pooling) que es igual a 2 capas de pooling, 1 capa fully connected y una capa de salida. El mayor problema de este modelo es que es demasiado simple y no es suficiente para la conducción autónoma.
SmallerVGGNet
Tenemos una capa convolucional de 32 filtros con activación ReLU, seguida de una capa de normalización, una capa de submuestreo y una capa de dropout del 25%. A continuación, hay dos bloques compuestos por una capa convolucional seguida de una capa BatchNormalization, una capa convolucional, una capa BatchNormalization, una capa de pooling y una capa de dropout del 25%. Al final de la red, tenemos un bloque de capas Fully Connected donde la última capa de activación es sigmoidal para la clasificación de múltiples etiquetas.
Definiciones
Mapas de características: En las capas convolucionales, las neuronas se distribuyen en diversas capas paralelas (Mapas de características) donde cada neurona se conecta a un campo receptivo local. Todas las neuronas comparten el mismo parámetro de peso conocido como kernel.
Objetivos salientes: Elementos de la imagen que influyen más en la decisión de dirección en PilotNet.
Stacked frames: Se concatenan varias imágenes de entrada consecutivas para crear una imagen ampliada. Meter imágenes concatenadas, como hablamos en apartados anteriores, pero se especifica que suponiendo que la red promedie la información, aumentar el número de imágenes podría hacer perder capacidad de respuesta.
Batch size: Número de muestras que serán evaluadas antes de actualizar los pesos.
Accuracy: Número de predicciones correctas realizadas por el modelo sobre el tipo de predicciones realizadas.
Precision: Relación entre positivos verdaderos (TP) y el número total de positivos predichos por un modelo (TP y FP), donde TP es el número de verdaderos positivos para una clase y FP es el número de falsos positivos para la clase X.
Recall: Relación entre positivos verdaderos (TP) y el número total de positivos que se producen.
Imagge cropping: Se extrae una zona concreta de la imagen donde se considera que se almacena la parte relevante de información.
Imagen diferencia: img(t) - img(t - 1). Tras realizar pruebas con imágenes diferencia como entrada se ve que aporta mas información temporal imágenes concatenadas que imagen de diferencia en un periodo de t = 10 por ejemplo.
Métricas de evaluación
-
Mean Absolute Error: Promedio de la diferencia entre los valores reales y los valores predichos por la red. Nos da una idea de cuán lejos están las predicciones de los valores reales, pero no aporta la dirección del error.
-
Mean Squared Error: Es similar, pero es más fácil calcular el gradiente que con MAE.
Aspectos a destacar
- La red funciona mejor con imágenes de eventos correspondientes a 50 ms.
- El rendimiento se degrada con imágenes en escala de grises, ya que a altas velocidades estas se difuminan.
- Tras varias pruebas, se obtienen mejores resultados con imágenes de grano grueso.
- Dataset de velocidades guardado en un archivo .json.
- Ejecución del programa dividida en hilos de percepción y control, hilo de interfaz gráfica de usuario e hilo de la red neuronal.
- Redimensión de imágenes para aliviar la carga de entrenamiento.
-
División de las velocidades en clases.
Aerostack2
Se consiguió resolver los fallos en la plataforma, ya que había conflictos en las versiones y algún fallo en los launchers de ejemplo (en este (enlace)[https://github.com/aerostack2/aerostack2/issues/347] se pueden ver los fallos que fueron surgiendo en el proceso). Después de esto, se planteó desarrollar el launcher de tal forma que cada componente de AeroStack2 se inicie en una terminal distinta con tmux para facilitar la depuración.