
Week 19 - Neural Pilot 2.2
Progress This Week
Objective
The objective was to achieve a well-functioning neural pilot, this time with my own datasets.
Summary
With all the tests and improvements done in the last few weeks and more data for the training of the nets, I ran a final batch of Neural Pilots.
In order to be able to compare them, all of them were trained with the same data (15534 pairs of labels and images) and parameters:
- num_epochs = 100
- batch_size = 128
- learning_rate = 1e-3
- val_split = 0.1
- shuffle_dataset = True
- save_iter = 50
- random_seed = 471
The exception being the data processing.
Expert Pilot
The pilot which generated the datasets can be watched here: https://youtu.be/um7ybjK6Sj0
Without Processing
Training graph:
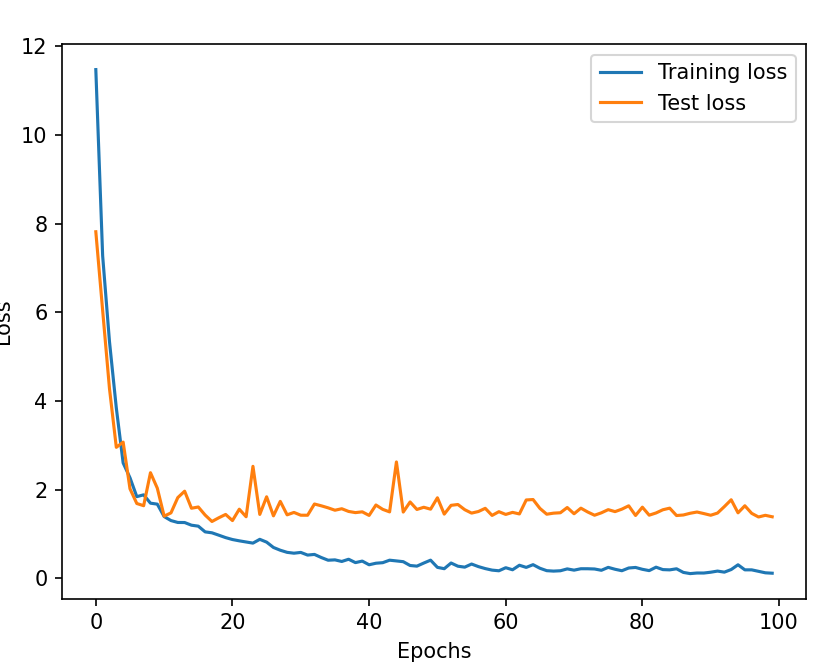
Offline test:
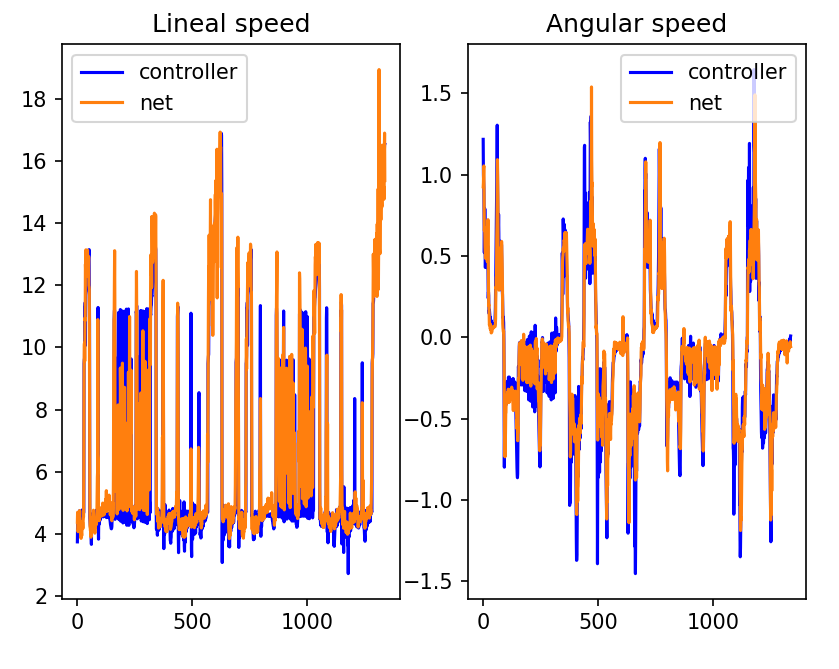
Result (https://youtu.be/voo4HVciFUY): It goes surprisingly smoothly, but when it gets a bit apart from the line, it stops knowing what to do. This proves the dataset doesn’t have enough data about these extreme cases. This surprised me a bit because one of the datasets, Montmelo, was generated in a run I thought was quite bad because the Expert Pilot kept stepping out of the line and having to find its way back. However, this is why I implemented the affine in my trainings, so let’s check it out.
Affine
In my previous attempt with someone else’s data, the affine did not help much and ended up being detrimental. However, after a few adjustments, we got a useful tool.
Training graph:
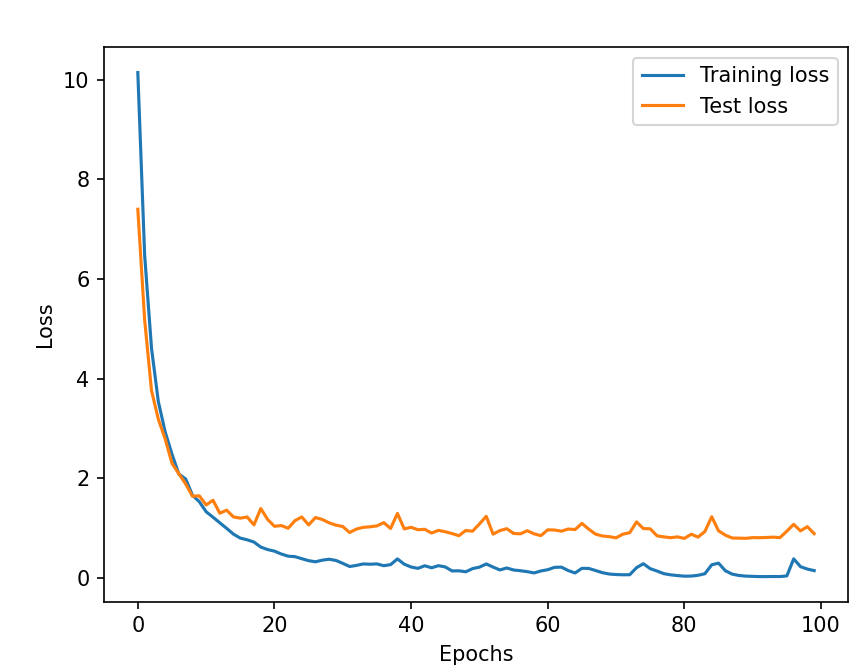
Offline test:
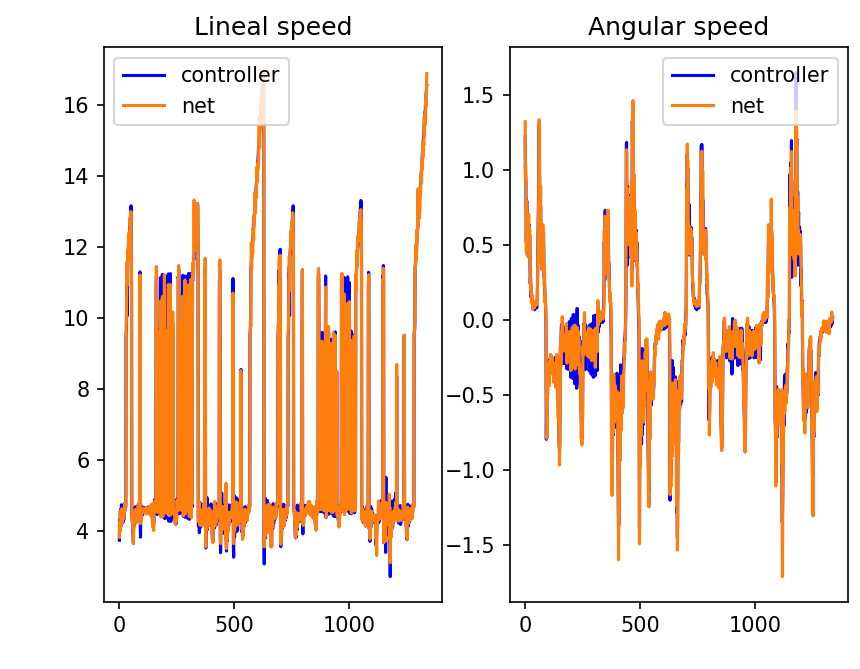
Result (https://youtu.be/oLDNV-7qnoc): With this, I finally achieved a pilot generated completely by myself (in this second round of code; I had working ones before) that worked quite well.
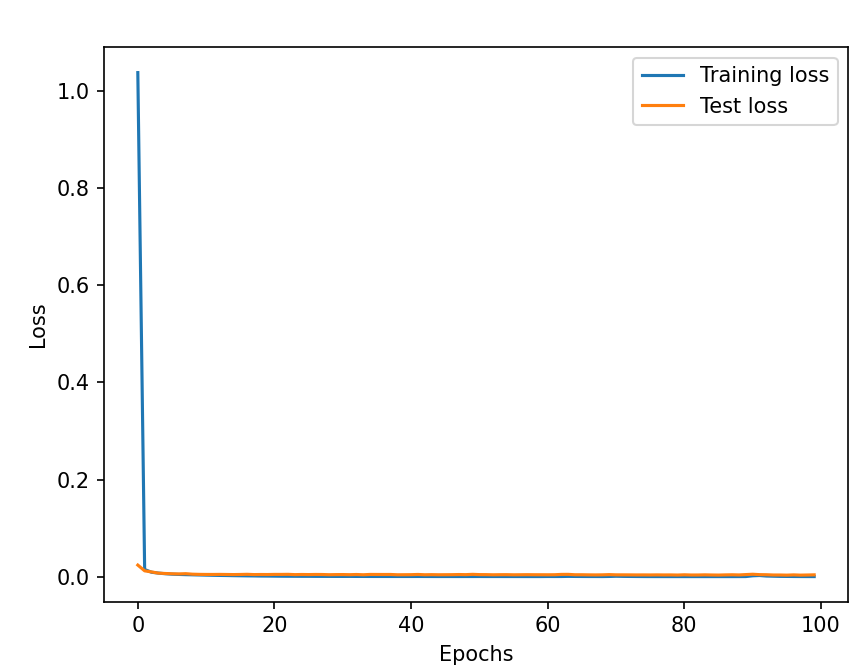
Normalization
Training graph:
Offline test:
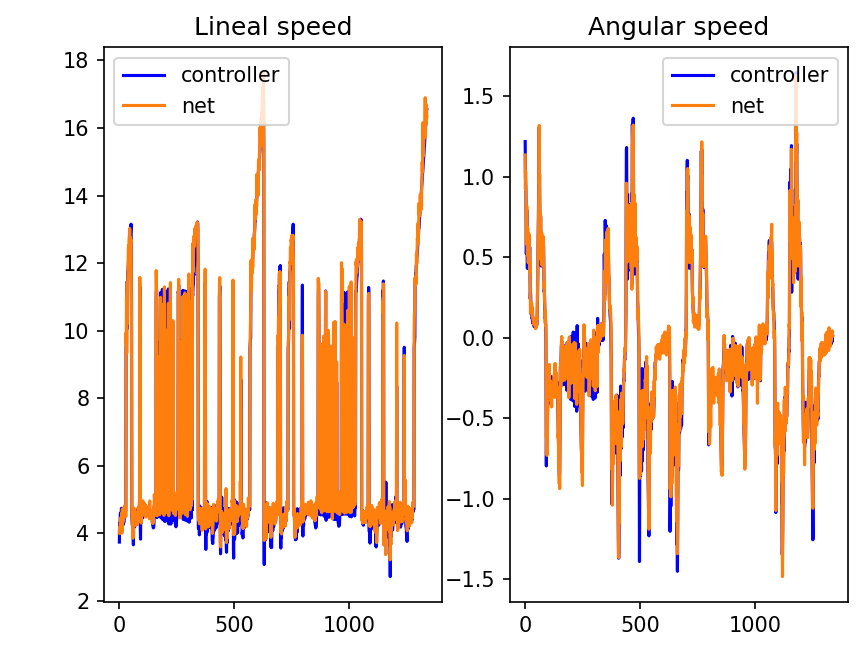
Result (https://youtu.be/2d9Fo25WvdE): As it could be expected, it accelerated the training, but ended up with a similar behavior to the neural pilot without processing.
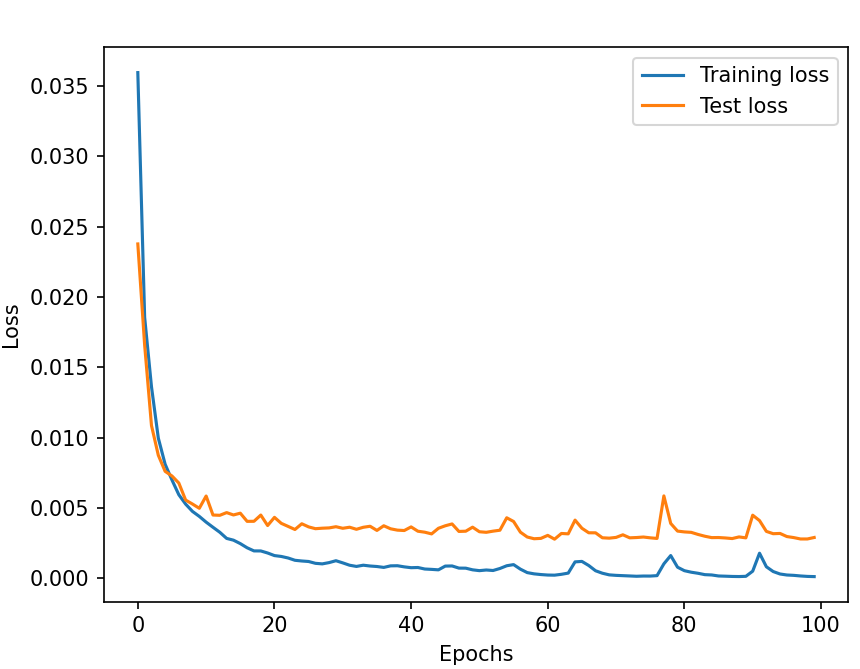
Affine + Normalization
Training graph:
Offline test:
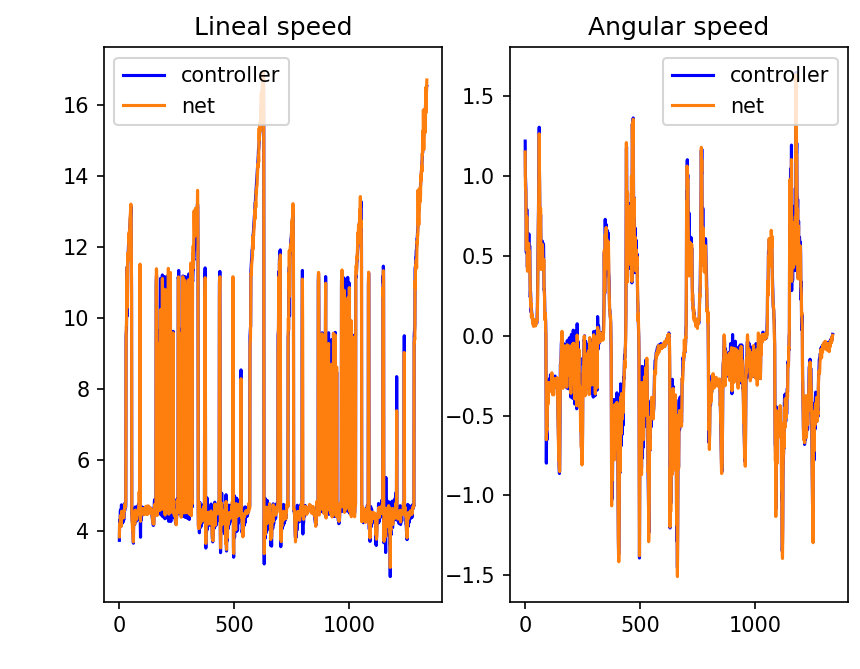
Result (https://youtu.be/4V87uoV7UQI): The training was really similar to the affine one, but the result was worse, although better than without it. It may be that compressing the data makes the net make more mistakes and being not that a big range (-1.5 to 1.5) in angular velocity those little mistakes end up being big ones.
Conclusion
Given the great results the affine has brought, I should keep using it. On the other hand, having a powerful computer has helped the trainings be done in more or less half an hour, which means accelerating them with normalization is not necessary and has proved detrimental with the results, so I will park it for now unless given other instructions.