
Fine-tuning RandLA-Net with Rellis3D
Last week, we created a toy example that fine-tuned RandLa-Net with the validation scene from the SemanticKitti dataset using Open3D-ML. You can explore results in this post. Building on this experience, we are now ready to work with our selected datasets for self-driving perception in unstructured environments: Rellis3D and GOOSE.
Getting ready for fine-tuning
Our first experiment involved fine-tuning RandLa-Net (pre-trained on SemanticKitti) with Rellis3D. We implemented a custom Open3D-ML dataset to read Rellis3D data. Fortunately, Rellis3D provides their Ouster LiDAR data in SemanticKitti format, which simplified the process. The dataset definition is available in proyecto-GAIA/Perception/lidar/rellis3d.py.
After setting up the dataset, fine-tuning the model was straightforward. The training script is available in Perception/scripts/train_rellis3d_lidar.py, and the configuration file defining all dataset, model, and training hyperparameters can be found in Perception/lidar/cfgs/randlanet_rellis3d.yml. For further validation of the current approach, we have both trained the model from scratch and fine-tuned a model already pre-trained with SemanticKITTI.
Training
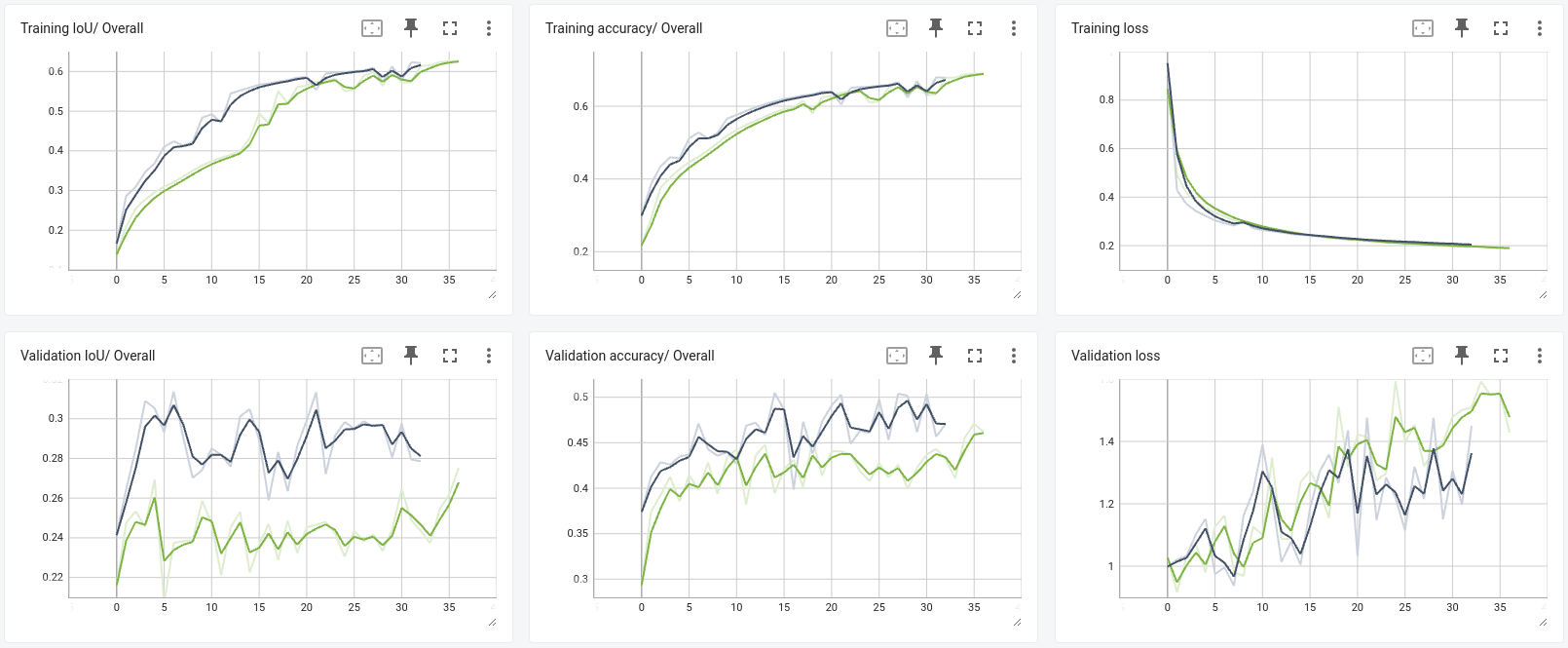
The following figures show the training and validation IoU, accuracy, and loss curves (trained from scratch in green, and fine-tuned in blue). The model begins overfitting early, with validation results plateauing after approximately 5 epochs. This behavior likely stems from the limited training data (7,800 frames) and the lack of data augmentation or regularization techniques. We can also see a very significant improvement in the validation stage performance when fine-tuning versus training from scratch.
Quantitative results
The table below presents the mean IoU achieved in the test set, alongside results reported for other models by Rellis3D authors (SalsaNext and KPConv). While our numbers appear low, they align with those reported in the original dataset paper.
| Model | mIoU (%) | sky | grass | tree | bush | concrete | mud | person | puddle | rubble | barrier | log | fence | vehicle | object | pole | water | asphalt | building |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SalsaNext | 43.07 | - | 64.74 | 79.04 | 72.90 | 75.27 | 9.58 | 83.17 | 23.20 | 5.01 | 75.89 | 18.76 | 16.13 | 23.12 | - | 56.26 | 0.00 | - | - |
| KPConv | 19.97 | - | 56.41 | 49.25 | 58.45 | 33.91 | 0.00 | 81.20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.40 | 0.00 | - | 0.00 | 0.00 | - | - |
| RandLA-Net | 31.70 | - | 63.15 | 72.08 | 74.15 | 1.02 | 8.89 | 83.65 | 0.38 | 25.22 | 0.02 | 0.00 | 54.52 | 10.98 | - | 0.04 | 0.00 | - | - |
Qualitative results
When visually inspecting a sequence from the test set with the predicted segmentation, we can see that the qualitative results are quite satisfying, although the quantitative numbers seem low. This is explained by the very low accuracy and IoU that the model shows when dealing with the less represented classes in the dataset (e.g., pole, puddle, vehicle, etc.). Additionally, the difference between classes such as tree/bush or mud/dirt is not always clear, and the model’s interpretation, although reasonable, does not always conform to the dataset labeling. In the next image, extracted from the Rellis3D paper, we show the label distribution:
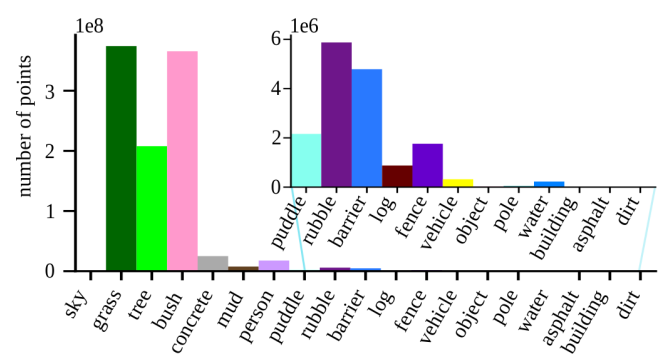
In the following video, we show, for the same sequence from the test set, the ground truth, estimation before fine-tuning (i.e., model pre-trained with SemanticKITTI), and estimation after fine-tuning. It is worth mentioning that there are points in the ground-truth not labeled (black) that the fine-tuned model correctly classifies as humans.