
Intro to LiDAR semantic segmentation
LiDAR plays a crucial role in autonomous driving by providing detailed 3D maps of surroundings through laser-based distance measurements. It enhances scene understanding beyond 2D imaging by reducing the inherent ambiguity of flat images. This is particularly important when working with unstructured outdoor environments where 2D semantics show extreme variability (e.g., distinguishing mud from dirt, or bushes from grass).
Semantic LiDAR Datasets
LiDAR’s importance in autonomous driving for unstructured outdoor environments is demonstrated by its central role in datasets like Rellis-3D and GOOSE. Meanwhile, larger urban driving datasets like SemanticKITTI and Waymo specifically target LiDAR semantic segmentation. The following table summarizes key characteristics of these datasets:
| Dataset | Environment | LiDAR | Classes | Instance? | Registered images | Number of sequences | Number of scans |
|---|---|---|---|---|---|---|---|
| Rellis-3D [1] | Unstructured | Ouster OS1 | 20 | No | Yes | 5 | 13,556 |
| GOOSE [2] | Unstructured | Ouster VLS 128 | 64 | Yes | Yes | 356 | 15,000 |
| SemanticKITTI [3] | Urban | Velodyne HDL-64E | 28 | No | No | 22 | 43,552 (23,201 annotated) |
| Waymo [4] | Urban | Multiple LiDARs | 23 | Yes | Yes | 1,150 | 230,000 (? ) |
LiDAR Semantic Segmentation Models
Several deep learning architectures have emerged as popular choices for LiDAR semantic segmentation:
- RandLA-Net [5] introduces an efficient random point sampling strategy combined with local feature aggregation, making it particularly suitable for large-scale point clouds.
- KPConv (Kernel Point Convolution) [6] defines a point-based convolution operator that processes 3D points directly without voxelization.
-
Point Transformers adapt the transformer architecture to point cloud processing:
- Point Transformer v1 [7] introduces vectorized self-attention for local geometric relationships.
- Point Transformer v2 [8] improves efficiency with vector attention and better positional encoding.
- Point Transformer v3 [9] further enhances performance with adaptive grouping and hierarchical feature learning.
Several open-source frameworks facilitate the implementation of these models:
- Open3D provides efficient data structures and algorithms for 3D data processing, while its machine learning extension Open3D-ML includes pre-trained models and training pipelines specifically for semantic segmentation and object detection. Besides, it allows using as backend either Tensorflow or Pytorch.
- Pointcept offers a comprehensive collection of point cloud perception models. It is built and maintained by the authors of Point Transformers.
Open3D-ML + SemanticKitti + RandLA-Net
We chose to experiment with a simple example using Open3D-ML’s implementation for fine-tuning RandLA-Net on the SemanticKITTI dataset, selected for its ease of use, popularity, and reasonable computational requirements. Our approach involved two steps: first, evaluating a pre-trained RandLA-Net model against a SemanticKITTI validation scene, then fine-tuning this model to overfit the same scene and evaluating it again. This toy experiment serves three purposes:
- Understanding SemanticKITTI, the leading LiDAR semantic segmentation dataset, including its data format and characteristics. This knowledge will help us format our own simulated datasets.
- Understanding how to build a typical deep learning pipeline for point cloud processing, including point subsampling and batching techniques.
- Gaining insight into the computational demands of training LiDAR-based models.
Point cloud processing (RandLA-Net example)
Before carrying out our little experiment, we have examined each step of the point cloud data processing pipeline, from initial data reading through final semantic segmentation prediction. Below is a detailed breakdown of the process:
-
Preprocess point cloud data and create cache files. This step takes points, labels, and optional features as input:
- Subsample the raw point cloud by building a 3D grid and keeping a single point from each cube where LiDAR data is present.
- Construct a KDTree and store each point’s nearest neighbor.
- Store the extracted data as a NumPy array per frame in a dictionary, containing:
data['point'] = sub_points -> subsampled points data['feat'] = sub_feat -> subsampled features (if they exist) data['label'] = sub_labels -> sumsampled labels data['search_tree'] = search_tree -> KDTree data['proj_inds'] = proj_inds -> nearest neighbors -
Transform cached point cloud data to be used as input for the RandLA-Net model:
-
(IF TEST / INFERENCE STAGE) → Spatially regular sampling:
- Assign random probabilities to each point in the cloud.
- Find the point with the lowest probability and its k nearest neighbors using the previously built KDTree. This will be our center point.
- Shuffle these indices and compute normalized, inverted distances from each point to the center point.
- Add these distances to the probability vector to reduce the likelihood of resampling the same region.
(IF TRAIN / VALIDATION STAGE) → Random sampling:
- Select a random center point.
- Sample its k nearest neighbors.
- Shuffle.
- Recenter the resulting point cloud.
- If features are missing, use points as features.
- Now, for each layer in the model, we take the input point cloud and:
- Use kNN to find k nearest neighbors →
neighbour_idx - Select first N points (N = number of points / specific layer subsampling ratio) →
sub_points,pool_i - Find the nearest neighbor for each of the sampled points →
up_i - Use the subsampled cloud as the new input cloud.
Code for this process:
for i in range(cfg.num_layers): # TODO: Replace with Open3D KNN neighbour_idx = DataProcessing.knn_search(pc, pc, cfg.num_neighbors) sub_points = pc[:pc.shape[0] // cfg.sub_sampling_ratio[i], :] pool_i = neighbour_idx[:pc.shape[0] // cfg.sub_sampling_ratio[i], :] up_i = DataProcessing.knn_search(sub_points, pc, 1) input_points.append(pc) input_neighbors.append(neighbour_idx.astype(np.int64)) input_pools.append(pool_i.astype(np.int64)) input_up_samples.append(up_i.astype(np.int64)) pc = sub_points inputs['coords'] = input_points inputs['neighbor_indices'] = input_neighbors inputs['sub_idx'] = input_pools inputs['interp_idx'] = input_up_samples inputs['features'] = feat inputs['point_inds'] = selected_idxs inputs['labels'] = label.astype(np.int64) - Use kNN to find k nearest neighbors →
-
(IF TEST / INFERENCE STAGE) → Spatially regular sampling:
- Feed the RandLA-Net model with the transformed data described above and retrieve resulting class probabilities.
-
Final steps:
(IF TRAIN) → compute loss, backpropagate, and go on with the training process.
(IF VALIDATION) → compute loss and metrics and store results.
(IF TEST / INFERENCE)
- Accumulate class probabilities from the subsampled point cloud into a full-sized point cloud probability array, using weighted average for smooth transitions between patches. Repeat the process until the point cloud has been fully traversed.
- Propagate the estimated labels from subsampled to full-sized point cloud using the previously built KDTree.
Results
We fine-tuned the RandLA-Net model for 20 epochs using the SemanticKITTI validation scene (08). This scene contains 4,071 frames and the training process took around 5h with a batch size of 6 using an NVIDIA GeForce GTX 1080 Ti. It is worth noting that I haven’t profiled the training step, so it is possible that most of this training time is spent in CPU operations for data preprocessing. A screenshot showing training progress in Tensorboard:
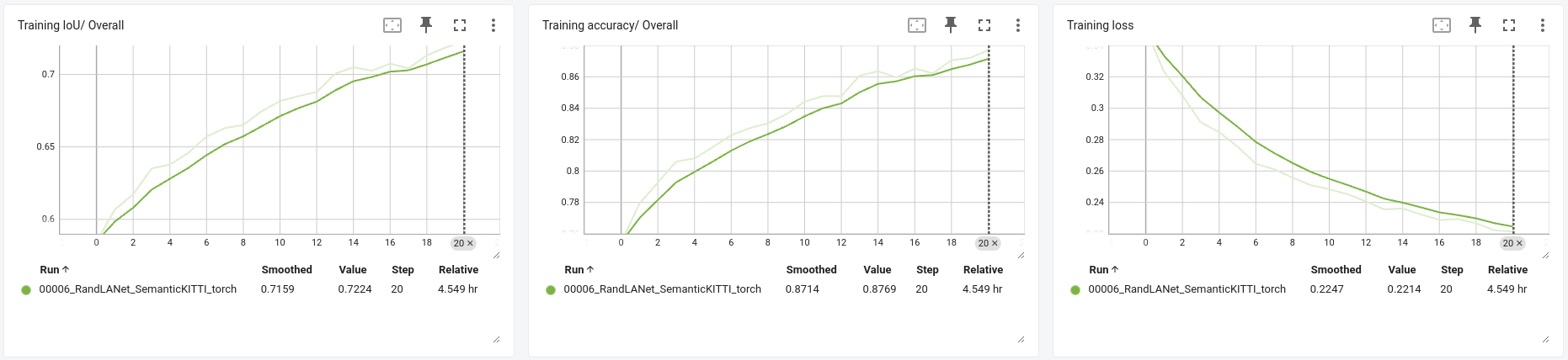
In the following table we show the resulting accuracy and intersection over union (IoU), before and after overfitting to the SemanticKITTI validation scene for 20 epochs:
| Accuracy | IoU | |
|---|---|---|
| Pre-trained | 0.58 | 0.46 |
| Overfitted | 0.89 | 0.79 |
Finally, here are some qualitative results comparing the ground truth annotations with both the pre-trained and overfitted model predictions for a small segment of the validation scene.
References
-
Jiang, P., Osteen, P., Wigness, M., & Saripalli, S. (2021). Rellis-3d dataset: Data, benchmarks and analysis. In 2021 IEEE international conference on robotics and automation (ICRA) (pp. 1110–1116). Project page.
-
Mortimer, P., Hagmanns, R., Granero, M., Luettel, T., Petereit, J., & Wuensche, H.J. (2024). The goose dataset for perception in unstructured environments. In 2024 IEEE International Conference on Robotics and Automation (ICRA) (pp. 14838–14844). Project page.
-
Behley, J., Garbade, M., Milioto, A., Quenzel, J., Behnke, S., Stachniss, C., & Gall, J. (2019). Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 9297-9307). Project page.
-
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., & others (2020). Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 2446–2454). Project page.
-
Hu, Q., Yang, B., Xie, L., Rosa, S., Guo, Y., Wang, Z., … & Markham, A. (2020). Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 11108-11117). Project page
-
Thomas, H., Qi, C. R., Deschaud, J. E., Marcotegui, B., Goulette, F., & Guibas, L. J. (2019). Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 6411-6420).
-
Zhao, H., Jiang, L., Jia, J., Torr, P. H., & Koltun, V. (2021). Point transformer. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 16259-16268).
-
Wu, X., Lao, Y., Jiang, L., Liu, X., & Zhao, H. (2022). Point transformer v2: Grouped vector attention and partition-based pooling. Advances in Neural Information Processing Systems, 35, 33330-33342.
-
Wu, X., Jiang, L., Wang, P. S., Liu, Z., Liu, X., Qiao, Y., … & Zhao, H. (2024). Point Transformer V3: Simpler Faster Stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4840-4851).