
Training semantic segmentation with simulated data
Simulated dataset
With our unstructured map built using properly categorized static meshes, we can now leverage CARLA’s semantic segmentation camera to create simulated datasets. For this purpose, we’ve utilized ROS bags. For example:
ros2 bag record -o gaia_sim_dataset_train /carla/hero/rgb_front/image /carla/hero/semantic_segmentation_front/image /segmentation/rgb/carla/hero/semantic_segmentation_front/image
To validate our complete pipeline, we’ve created a minimal dataset recorded at 20 fps, consisting of:
- Train: A jeep on autopilot traversing our unstructured map.
- Validation: The same jeep manually driven for a few seconds.
- Test: The same jeep on autopilot, traversing the map in the opposite direction.
We extracted all images and masks from the generated ROS bags using our rosbag_to_dataset.py script. After keeping only those timestamps with both RGB and semantic segmentation data available, we ended up with 1,886 samples for training, 405 for validation, and 1,827 for testing.
Fine-tuning ACF-Net
We adapted the Jupyter notebook previously built by Rebeca to fine-tune an ACF-Net with an EfficientNet backbone (pretrained on ImageNet) for 30 epochs. This configuration has performed best in the past when working with real datasets (more info). The complete code is available at Perception/3_SemanticSegmentation/CARLA/SEM_ACFNET_EFFNET_CARLA.ipynb.
Our newly trained model achieves an accuracy of 88% when evaluated against our test set, compared to 56% accuracy for the same model fine-tuned with Rellis3D. The following plots show a qualitative comparison between both approaches:

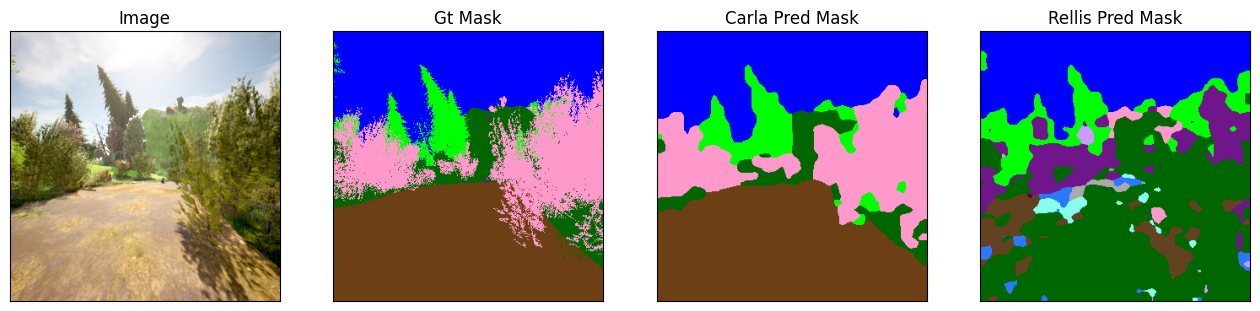
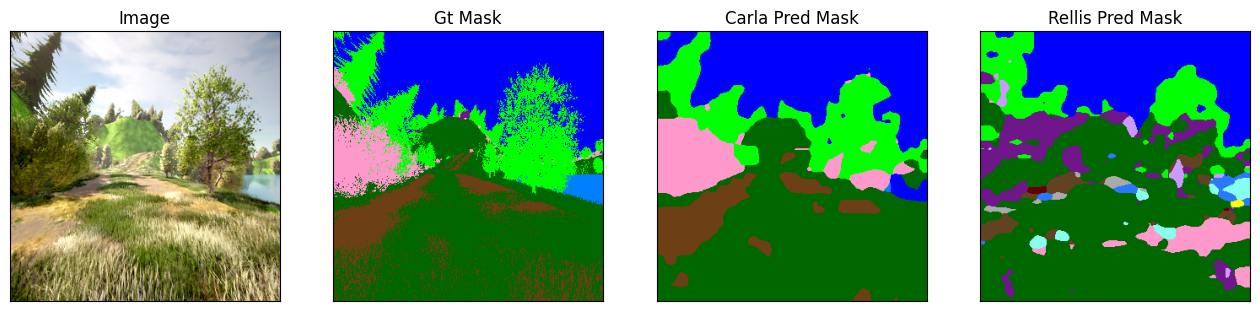

Validating our pipeline
While these results may not be particularly meaningful—given the similarity of objects and atmospheric conditions between our train and test datasets—they serve as a proof of concept, validating our entire pipeline for:
- Simulating unstructured outdoor environments
- Generating customized semantic segmentation ground truth data
- Building synthetic datasets using CARLA sensors data
- Training our own models using synthetic data
- Performing real-time inference over CARLA sensors
For this final step, we demonstrate in the following video an rviz dashboard featuring a third-person view, LiDAR, ego RGB image, and ego semantic segmentation ground truth and estimation.