Fixing RLidar and final steps q-learning 1D
Index
Fixing RLidar
For the functioning of RLidar SMARTS generates a series of rays that will be translated in different iterations depending on where the origin is located, so it is much lighter computationally than generating all the rays each time. For some reason, if the origin does not vary between iterations, the origin itself is detected as an obstacle. This generated erratic and unexpected behaviour.
Once the error has been located, the simplest way to deal with it has been to generate a small noise that varies the origin, so that it will never be the same two iterations in a row.
1
2
3
4
def add_origin_perturbation(origin, magnitude=0.001):
"""Add noise to origin"""
perturbation = np.random.uniform(-magnitude, magnitude, size=2)
return origin + np.array([perturbation[0], perturbation[1], 0])
Created test for inference phase
In this phase several programs have been created, one saves the q-table generated in the previous section by saving it in a file q_table.py that will be used as the basis for the test. Once the table has been generated after training, in this phase a test episode will be generated from the desired position in which the decisions taken will be based on the table obtained.
Random starting positions
This part was quite complicated, as it was not possible to modify the scenario to be able to start in random positions. A functionality has been added that generates a random number within a range, in this case -3,3 and adds it to the current pose generating a target. With a small algorithm the agent approaches that position and when it reaches or has passed the maximum number of episodes destined for that phase, the agent stops.
In this way we lose some episodes, but we make sure that we always start in random positions.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
def move_to_random_position(self, current_position, target_position, accelerate, steps, first_act):
"""Mueve el vehículo a una posición (target)."""
distance = target_position - current_position
action = 0
# Determinar si avanzar o retroceder
if accelerate == True:
action = 8 if distance > 0 else -8
# Paramos si estamos cerca o si llegamos a las maximas steps
if abs(distance) < 0.25 or steps == MAX_ALIGN_STEPS:
# print(f"finished, current pose: {current_position}")
action = -first_act
return np.array([action, 0.0])
##################................###########################
while not terminated:
# Mover a posicion aleatoria
if not moved:
# Indice 0 es el que se usa en nuestro escenario
action = agent.move_to_random_position(observation["ego_vehicle_state"]["position"][0], target, accelerate, n_steps, first_action[0])
accelerate = False
if action[0] + first_action[0] == 0:
moved = True
if n_steps == 0:
first_action = action
observation, _, _, _, _ = env.step((action[0],action[1]))
n_steps = n_steps + 1
# print(observation['ego_vehicle_state']['speed'])
# Tenemos que asegurarnos que SIEMPRE gastamos MAX_ALIGN_STEPS steps, así no modificamos el entrenamiento
elif n_steps <= MAX_ALIGN_STEPS:
# print(observation['ego_vehicle_state']['speed'])
observation, _, _, _, _ = env.step((0.0,0.0))
n_steps = n_steps + 1
##################................###########################
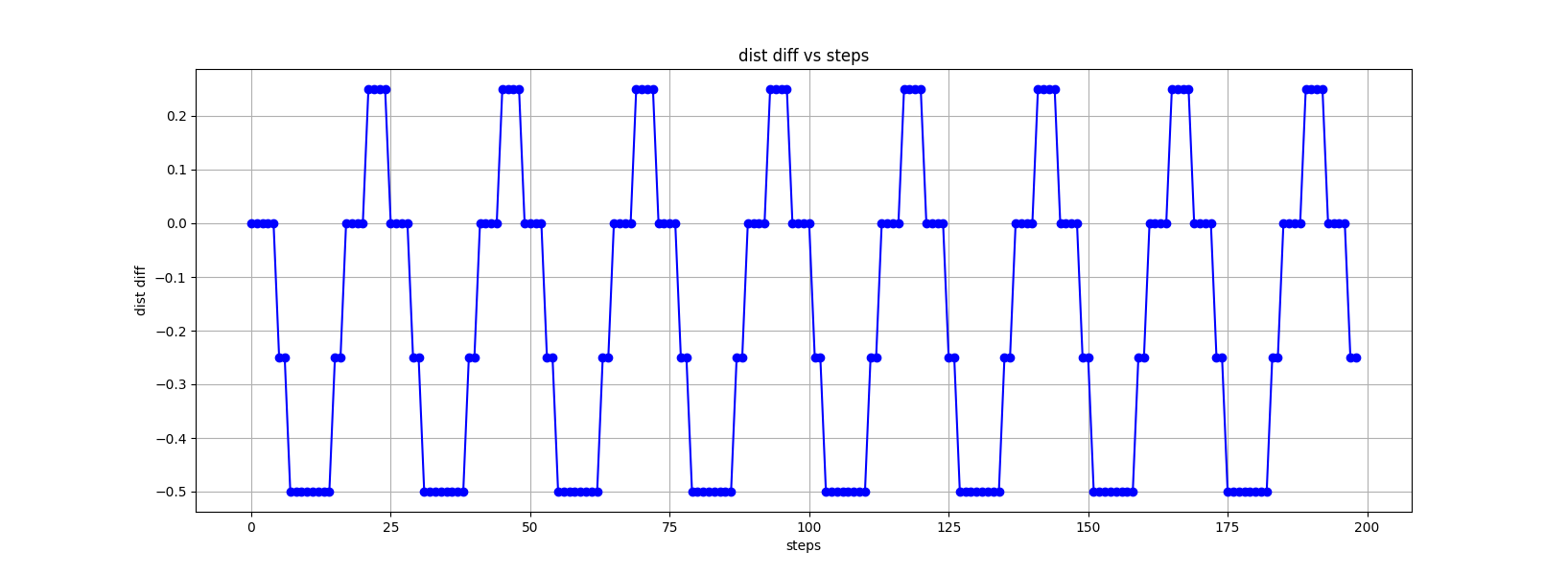
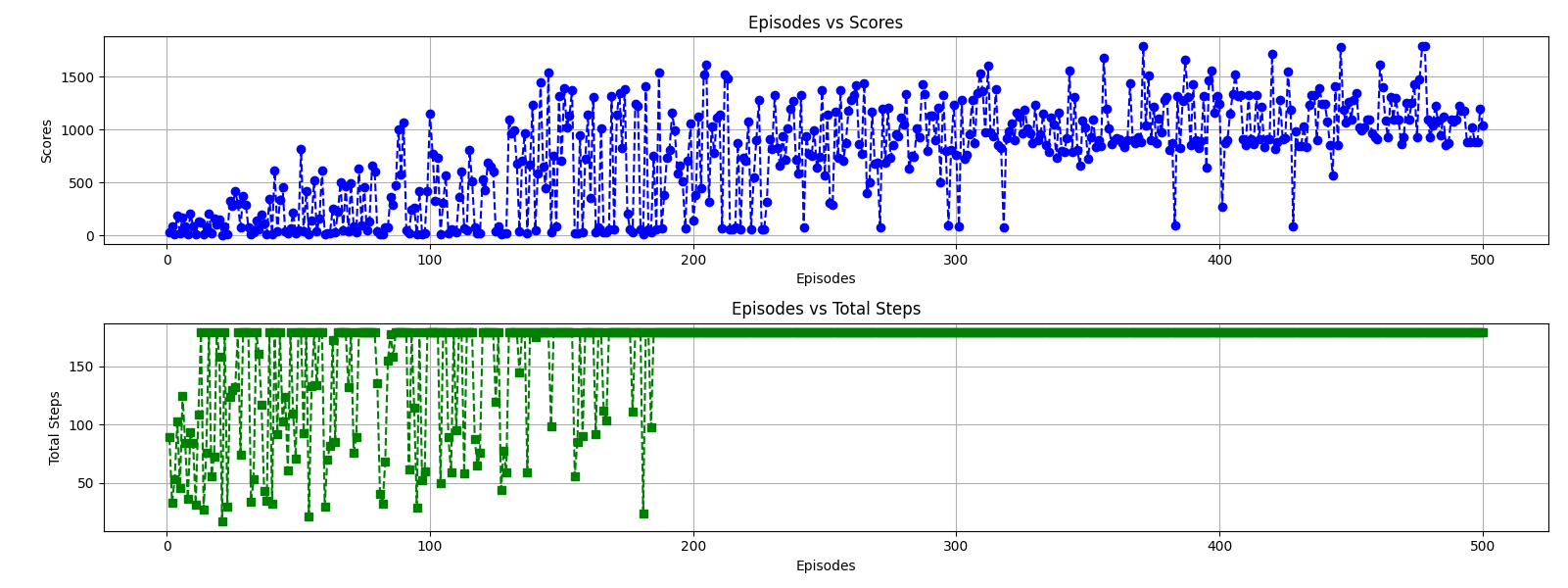
Example and data analysis
Here is the graph of the distance difference when the agent starts centred: