Testing DQN
Index
Fixing Reference System
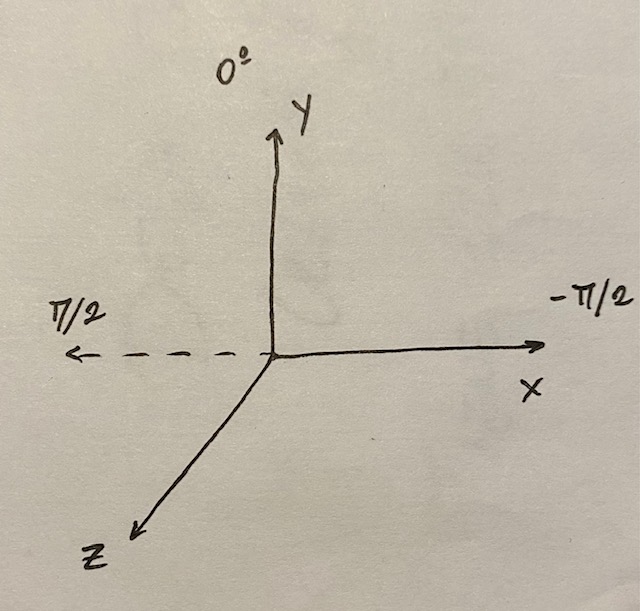
Before we could do all this we had to fix the way of using the coordinates in SMARTS, as we were interested in a reference system relative to the vehicle regardless of the orientation of the road, and as SMARTS uses this reference system, it had to be rotated to make it easy to interpret:
 aerial view
aerial view
Working DQN
The problem with Q-Learning is based on the fact that the Q-table (which is a dictionary) now contained more than 10000 states, which slowed down the execution and made learning impossible. For this reason, it was decided to upgrade to DQN.
Network Architecture (DQN)
The neural network used is a DQN (Deep Q-Network), which combines a deep neural network with the Q-learning algorithm. The architecture consists of the following layers:
Input layer: receives the current state of the environment.
Hidden layers: Two fully connected layers (fc1 and fc2) with 128 and 64 neurons respectively. These layers use the ReLU activation function to introduce non-linearities (ReLU (Rectified Linear Unit) is an activation function).
Output layer: Provides the Q values for each possible action. The number of neurons in this layer is equal to the number of available actions.
Layer normalisation (LayerNorm) is a technique that normalises the activations of a layer to have a mean of 0 and a standard deviation of 1.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class DQN(nn.Module):
def __init__(self, state_size, action_size):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_size, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, action_size)
self.layer_norm1 = nn.LayerNorm(128)
self.layer_norm2 = nn.LayerNorm(64)
def forward(self, x):
x = torch.relu(self.layer_norm1(self.fc1(x)))
x = torch.relu(self.layer_norm2(self.fc2(x)))
return self.fc3(x)
Hyperparameters
Hyperparameters are settings that control the behaviour of the neural network and the training process. The most important are:
state_size: Size of the state vector (network input).
action_size: Number of possible actions (network output).
gamma: Discount factor (between 0 and 1). It controls the importance of future rewards.
alpha: Learning rate. Determines how much the network weights adjust at each training step.
epsilon: Exploration probability. Controls when the network chooses a random action (exploration) instead of the optimal action (exploitation).
min_epsilon: Minimum epsilon value. Ensures minimum exploration even after many iterations.
decay_rate: Decay rate of epsilon. Reduces epsilon over time to move from exploration to exploitation.
batch_size: Number of samples used in each training step. A larger batch size provides a more stable estimate of the gradient.
memory: Experience buffer. Stores the transitions (state, action, reward, next state, finished) for training.
Double DQN
To improve the stability of the training, Double DQN is used. Instead of using the same network to select and evaluate actions, two networks are used:
Main network (model): selects the best action for the next state.
Target network (target_model): Evaluates the Q-value of that action.
This avoids overestimation of Q-values, which is a common problem in traditional Q-learning.
1
2
self.target_model = DQN(state_size, action_size).to(self.device)
self.target_model.load_state_dict(self.model.state_dict())
SoftMax Update
Instead of copying the weights from the main grid to the target grid all at once, a soft update is performed. This means that the weights of the target network are updated gradually at each step, using a tau mixing factor.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def act(self, state):
if np.random.rand() < self.epsilon:
return random.choice(self.actions)
state_tensor = torch.FloatTensor(state).unsqueeze(0).to(self.device)
with torch.no_grad():
q_values = self.model(state_tensor)
try:
tau = 0.5
probs = torch.nn.functional.softmax(q_values / tau, dim=1) # Q - probs
action_index = torch.multinomial(probs, num_samples=1).item()
return self.actions[action_index]
except IndexError:
return random.choice(self.actions) # error - random
Tests
Before this more or less solid network was in place, the first tests were disastrous:
By gradually adjusting parameters it seemed to learn, although the loss did not stabilise and started to converge to a local minimum.
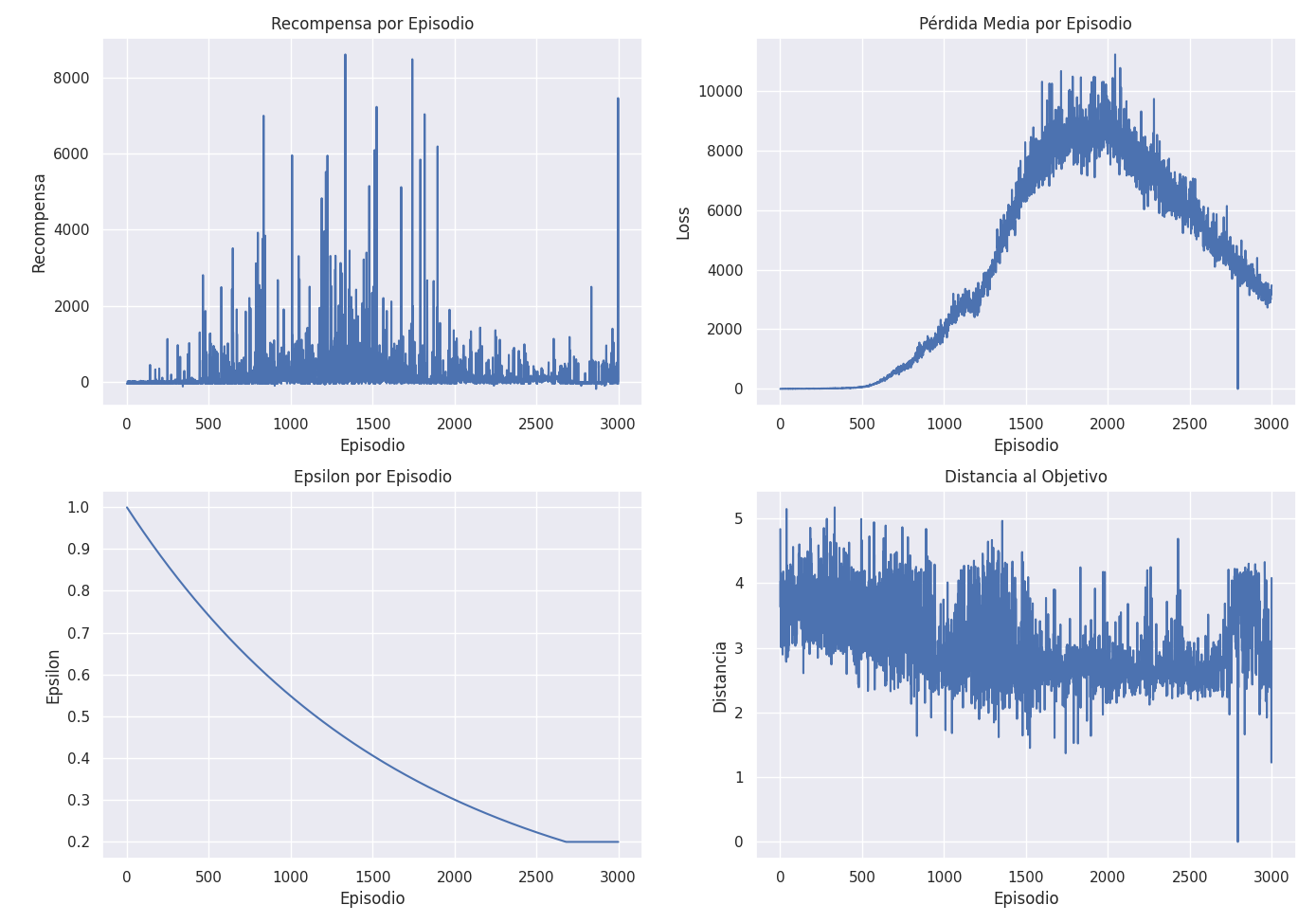
After further tests the improvement was astonishing, he managed to learn to park, but he was still very unstable and the loss was not stabilised.
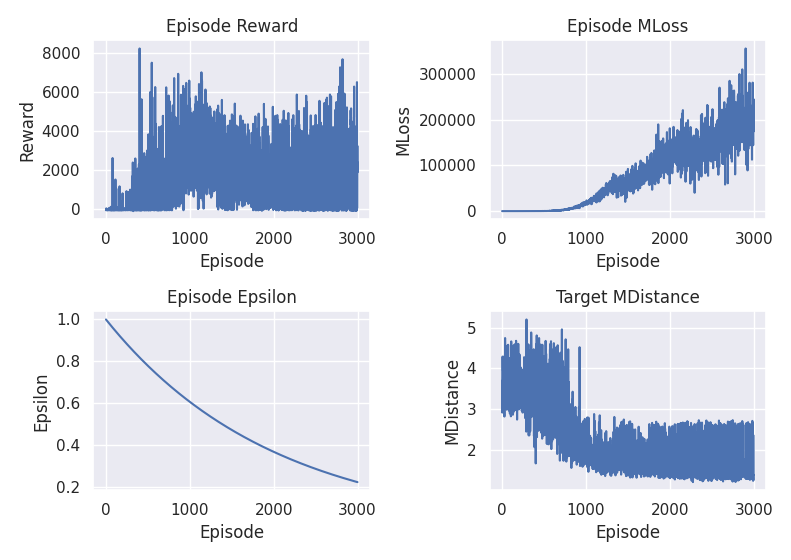
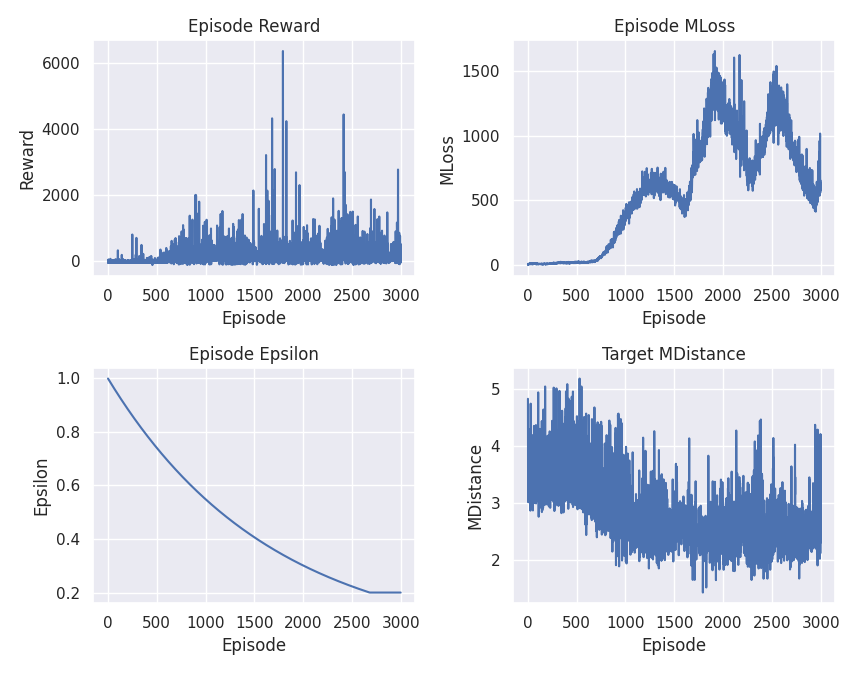
In the last tests it seemed to ‘park’ without perfect orientation and speed, which is already a big step forward, but the loss was still not stabilised.
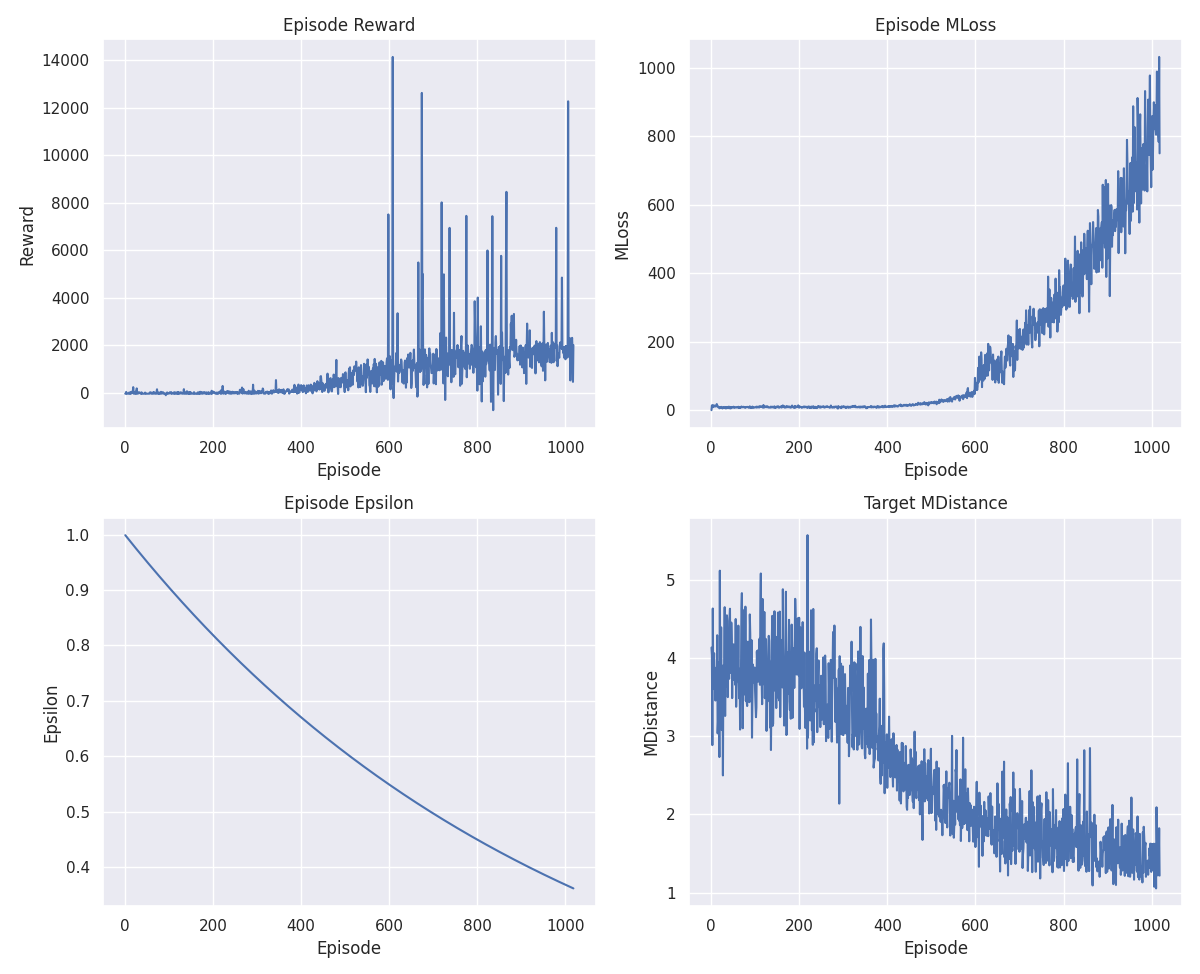
That the loss does not stabilise after so many tests and parameter changes may mean that the rewards are too variable. It was something I hadn’t given much thought to until now, one way to fix it and add very little variability is to normalise the rewards, but it doesn’t seem to have solved the problem: