Mountain car and testing DQN
Index
Mountain car
The most common neural network, with two hidden layers.
1
2
3
4
5
6
7
8
9
10
11
class DQN(nn.Module):
def __init__(self, state_size, action_size):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_size, 32)
self.fc2 = nn.Linear(32, 32)
self.fc3 = nn.Linear(32, action_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
The hyperparameters used were achieved through testing, it is possible that the current solution can be further refined.
1
2
3
4
5
6
7
self.gamma = 0.99
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.99
self.learning_rate = 3e-3
self.batch_size = 512
self.memory = ReplayBuffer(10000)
To avoid the typical overfitting in dqn, double dqn was used. Only 500 episodes with 200 steps per episode are used for learning.
Working DQN
An apparently stable solution was reached, but in practice the agent had fallen into a local minimum, because the horizontal and vertical distance to the car park were not taken into account separately.
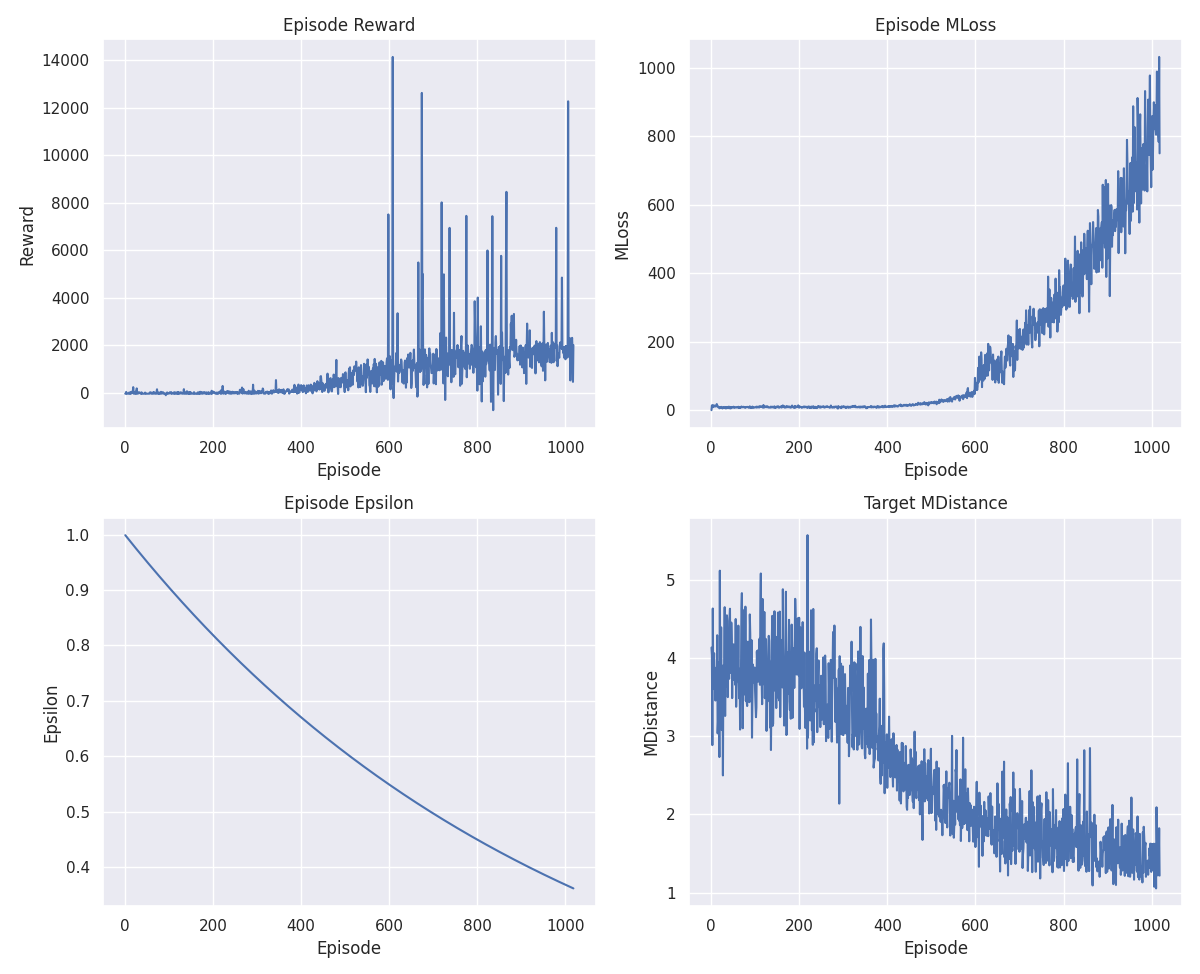
In a conventional car park the vehicle may not be perfectly centred vertically, but the horizontal centring is key to keeping the vehicle in the car park. With this in mind, the rewards were modified accordingly. The reward system is now much more complex.
Due to these changes the scenario has been simplified a little, leaving only 3 different starting positions (previously 5). The overfitting was still growing as the rewards were not well distributed, to solve it or rather, to improve it, the rewards were normalised.
With these improvements the agent no longer falls into local minima, but there is still a phase of testing and improvement as the solution is not completely stable.
V1
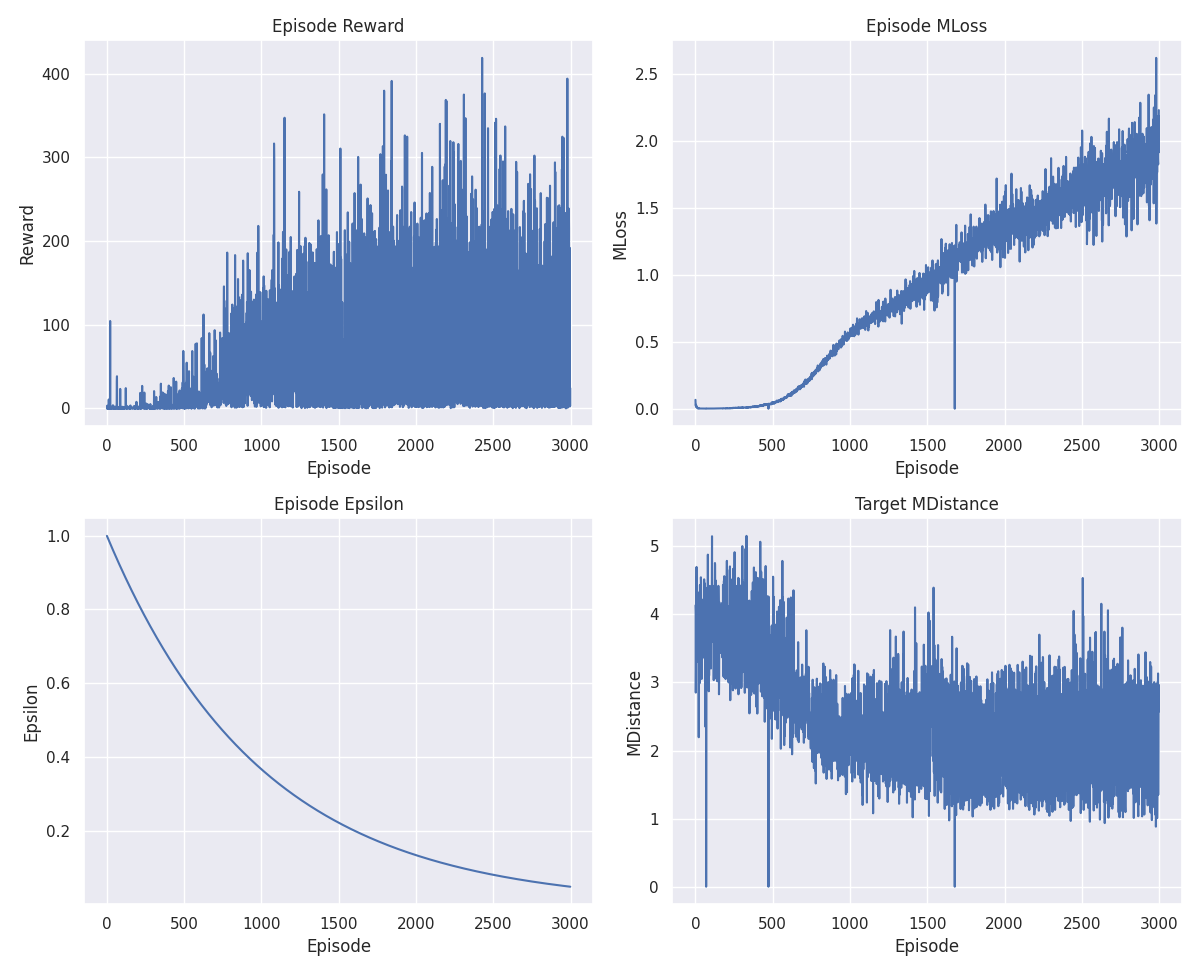
V2
By polishing the hyperparameters a little, we have been able to improve the learning process and achieve a much more solid network, although we have not yet found the most optimal solution.
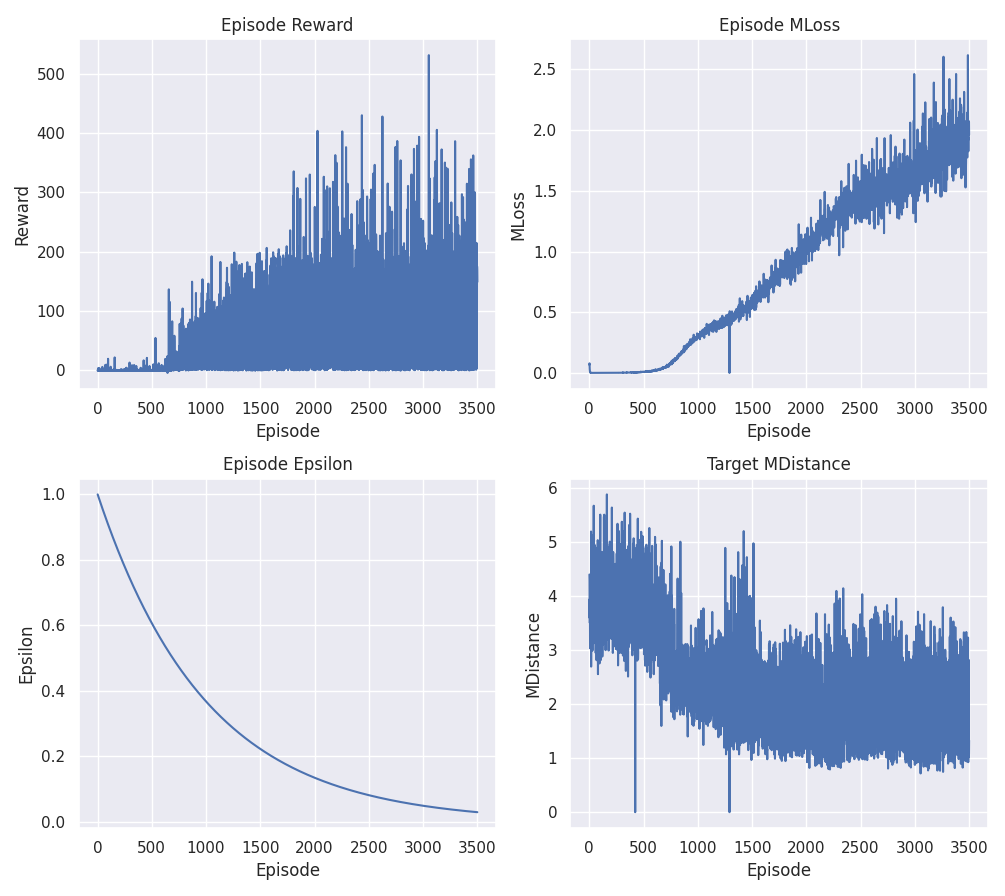
V3
As the optimal solution has not yet been found, the reward system has been modified again, imitating the mountain_car exercise, so that once the goal, a near-perfect parking, is achieved, the episode ends with a big bonus and is also rewarded for the time it took to achieve it.
The parameters have not yet been sufficiently refined, training sessions still have too variable rewards, so the warm-up phase will be used instead. This way the agent should be able to start learning to park and then the initial position will be randomly modified to avoid over-adjustment.