
Primera Implementación del modelo PointNet
Estas semanas me he dedicado a investigar el funcionamiento de la arquitectura PointNet para la segmentación semántica en nubes de puntos. También preparé un pequeño conjunto de entrenamiento para probar la implementación que hice en Tensorflow (Keras) de esta. He utilizado 150 muestras, de 14000 puntos por muestra del dataset GOOSE para optimizar el tiempo de computación y comprobar su funcionamiento, sin esperar grandes resultados.
Arquitectura PointNet
PointNet es una arquitectura de red neuronal diseñada para procesar directamente nubes de puntos en 3D, una representación común en tareas como clasificación, segmentación y estimación de poses en visión por computadora. Su diseño aborda el desafío de trabajar con datos no estructurados y desordenados, características intrínsecas de las nubes de puntos.
Input Layer
La entrada al modelo es un tensor con dimensiones (batchsize, 14000, 4). El batchsize se escogerá dependiendo de la memoria disponible.
Primeras Capas Convolucionales 1D
En la primeras capas convolucionales, el objetivo principal es aprender características locales de cada punto de la nube de puntos. Cada punto se procesa de manera independiente para extraer patrones relevantes, sin considerar aún la relación entre los demás puntos. Esta fase incluye las siguientes capas convolucionales:
- Conv1D (Input: 4 → Output: 64): Aprende patrones iniciales de las características de entrada (
x, y, z, remisión). - Conv1D (Input: 64 → Output: 128): Extrae características más complejas a partir de las salidas de la primera capa.
- Conv1D (Input: 128 → Output: 1024): Aprende características avanzadas por punto a partir de las anteriores.
Global MaxPooling
El Max Pooling Global tiene como propósito resumir toda la información de la nube de puntos en un único vector global. Este vector captura las características más representativas de la nube completa, asegurando invarianza al orden de los puntos dentro de la nube, lo que es crucial dado que las nubes de puntos no tienen una estructura fija.
Segundas Capas Convolucionales 1D
Finalmente, en las segundas capas convolucionales, el objetivo es combinar la información local de cada punto con la información global de la nube. Esto permite refinar las características aprendidas y realizar predicciones precisas para cada punto de la nube, utilizando tanto la perspectiva global como la local. Esta fase incluye las siguientes capas convolucionales:
- Conv1D (Input: 2048 → Output: 512): Reduce la dimensión combinada de las características locales y globales.
- Conv1D (Input: 512 → Output: 256): Refina las características aprendidas de los puntos.
- Conv1D (Input: 256 → Output: 64): Compacta las características de cada punto en una representación más reducida.
Output Layer
Conv1D (Input: 64 → Output: num_classes): Genera las predicciones de clase para cada punto
Implementación del Modelo en Keras

Código
# Dividimos en entrenamiento y validación
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(points, labels, test_size=0.2, random_state=42)
# -----------------------------
# DEFINICIÓN DEL MODELO POINTNET
# -----------------------------
def build_pointnet(num_classes, input_dim=4):
"""
Modelo PointNet para clasificación punto a punto.
"""
inputs = tf.keras.Input(shape=(None, input_dim)) # Entrada: N puntos con D características
# MLP Layers
x = layers.Conv1D(64, 1, activation='relu')(inputs)
x = layers.Conv1D(128, 1, activation='relu')(x)
x = layers.Conv1D(1024, 1, activation='relu')(x)
# Global Feature Aggregation
global_features = layers.GlobalMaxPooling1D()(x)
global_features = layers.RepeatVector(MAX_POINTS)(global_features) # Repetir para cada punto
global_features = layers.Conv1D(1024, 1, activation='relu')(global_features)
# Concatenar características globales y locales
x = layers.concatenate([x, global_features])
# MLP final para clasificación
x = layers.Conv1D(512, 1, activation='relu')(x)
x = layers.Conv1D(256, 1, activation='relu')(x)
outputs = layers.Conv1D(num_classes, 1, activation='softmax')(x) # Clasificación por punto
return tf.keras.Model(inputs, outputs)
# Construir y compilar el modelo
pointnet_model = build_pointnet(num_classes=64, input_dim=4)
pointnet_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Resumen del modelo
pointnet_model.summary()
# -----------------------------
# ENTRENAMIENTO DEL MODELO
# -----------------------------
history = pointnet_model.fit(
x_train, y_train,
validation_data=(x_val, y_val),
epochs=10, # Ajustar según los recursos
batch_size=8, # Ajustar según la memoria disponible
verbose=1
)
# -----------------------------
# EVALUACIÓN
# -----------------------------
loss, accuracy = pointnet_model.evaluate(x_val, y_val)
print(f"Loss: {loss}, Accuracy: {accuracy}")
# -----------------------------
# PREDICCIONES
# -----------------------------
# Predicciones punto a punto
predictions = pointnet_model.predict(x_val)
predicted_labels = np.argmax(predictions, axis=-1) # Etiquetas por punto
print("Predicciones para la primera nube:", predicted_labels[0])
print("Etiquetas reales para la primera nube:", y_val[0])
Resultados
Los resultados en segmentación no son buenos por el tamaño reducido del conjunto de datos, sin embargo prueban el funcionamiento de la arquitectura. Hay que tener en cuenta que no buscaba obtener una precisión y exactitud elevadas en los resultados, solo probar la implementación sin sobrecargar computacionalmente el proceso.
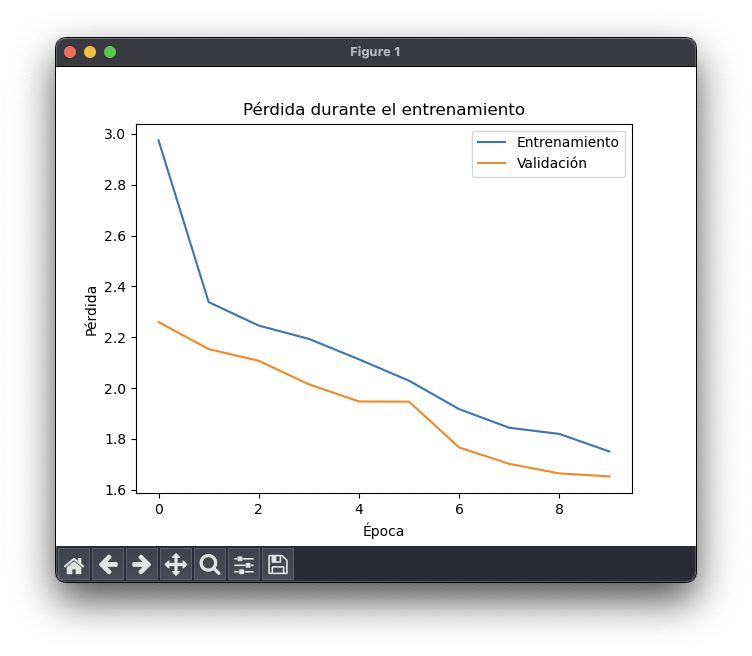
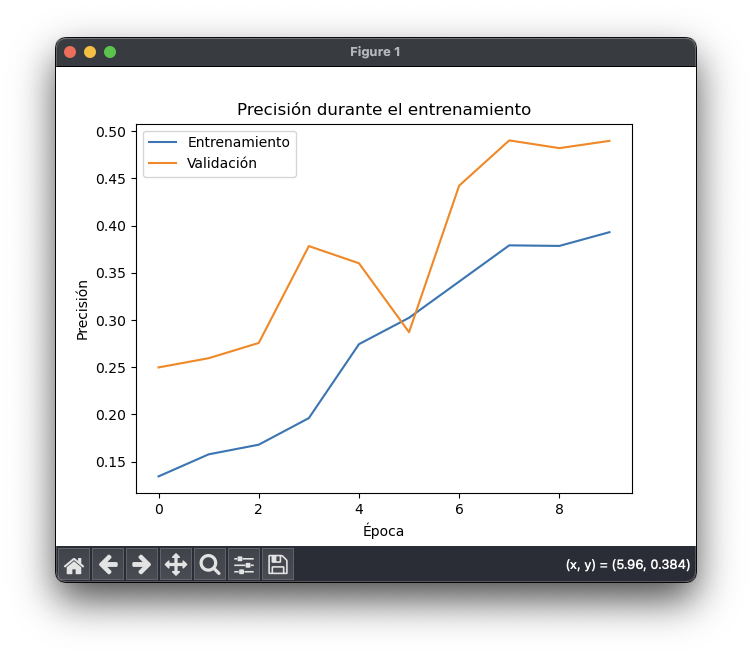
Los resultados muestran como se reduce la pérdida (loss) y aumenta la exactitud (accuracy) durante las 10 épocas (epochs) del entrenamiento de prueba. Esto demuestra que el modelo entrena correctamente y se puede entrenar con el conjunto de datos de entrenamiento completo.