
Preprocesamiento del dataset GOOSE, Mejoras en la implementación de PointNet
Esta semana me he dedicado a estudiar mejor la naturaleza de los datos LiDAR (nubes de puntos) y las técnicas de normalización que más se adecuan a cada tipo de característica. Además, diseñé una herramienta para redimensionar las nubes de puntos a un shape fijo durante el preprocesado del dataset bruto en el caso de que esto sea necesario a la entrada al modelo. Por último, mejoré el entendimiento interno del modelo PointNet y realicé mejoras en la implementación en Tensorflow.
Preprocesado del Dataset Bruto (GOOSE)
Estructura del Dataset Procesado
El dataset LiDAR de GOOSE está estructurado en tres subconjuntos principales: train (27 GB), val (3.3 GB) y test (3.3 GB). Cada uno de estos subconjuntos se encuentra organizado en múltiples escenarios, donde los barridos LiDAR y sus respectivas etiquetas semánticas están almacenados en carpetas paralelas.
Para el entrenamiento, se se deben combinar los escenarios presentes en el conjunto de train, unificando la información. En cambio, los conjuntos de val y test mantendrán la organización por escenarios, permitiendo evaluar el rendimiento del modelo en entornos específicos y asegurando una evaluación más representativa de su capacidad de generalización.
Normalización de Características
Se aplicará una estrategia diferenciada en función de la naturaleza de cada atributo. Para las características intrínsecas geométricas [ x y z ], la normalización se realizará considerando la estructura y el origen de cada barrido LiDAR de manera independiente. En cambio, para las características cualitativas como la remission, se aplicará un enfoque distinto en la normalización. En este caso, los valores serán ajustados en referencia a los estadísticos obtenidas a partir del conjunto de train.
Esta estrategia de normalización de las características geométicas mantendrá la relación espacial original entre puntos y la naturaleza del contexto de la captura de los barridos LiDAR independientemente del subconjunto al que pertenezcan.
for i, df in enumerate(X):
# Calcular la distancia máxima euclidiana para cada nube
d_max = np.sqrt((df[['x', 'y', 'z']] ** 2).sum(axis=1)).max()
# Normalizar x, y, z dividiendo por la distancia máxima
df[['x', 'y', 'z']] = df[['x', 'y', 'z']] / d_max
# Reasignar el dataframe normalizado a la lista X_train
X[i] = df
Redimensionado
En el pipeline de procesamiento, he incorporado una etapa para redimensionar las nubes de puntos que superen un umbral predefinido, ajustándolas a esa cantidad. Esto se debe a que la versión actual de PointNet que he implementado no admite tamaños de entrada variables en los barridos LiDAR. Próximamente buscaré gestionar un shape variable a la entrada del modelo.
X_redim = []
Y_redim = []
for i in range(len(X)):
# Permutación aleatoria de los indices de la nube de puntos
perm_indices = np.random.choice(len(X[i]), 10000, replace=False)
# Copia de los df originales para no modificar la información original
df_x = X[i].copy()
df_y = Y[i].copy()
# Aplicar permutación a los puntos y etiquetas
df_x = df_x.iloc[perm_indices].reset_index(drop=True)
df_y = df_y.iloc[perm_indices].reset_index(drop=True)
X_redim.append(df_x)
Y_redim.append(df_y)
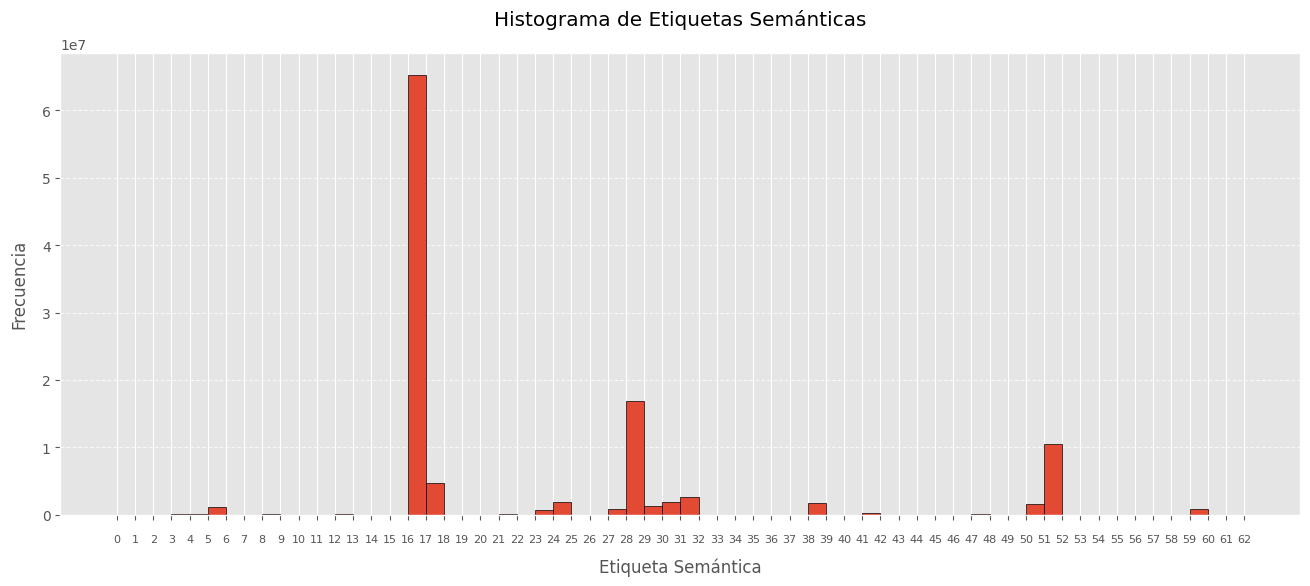
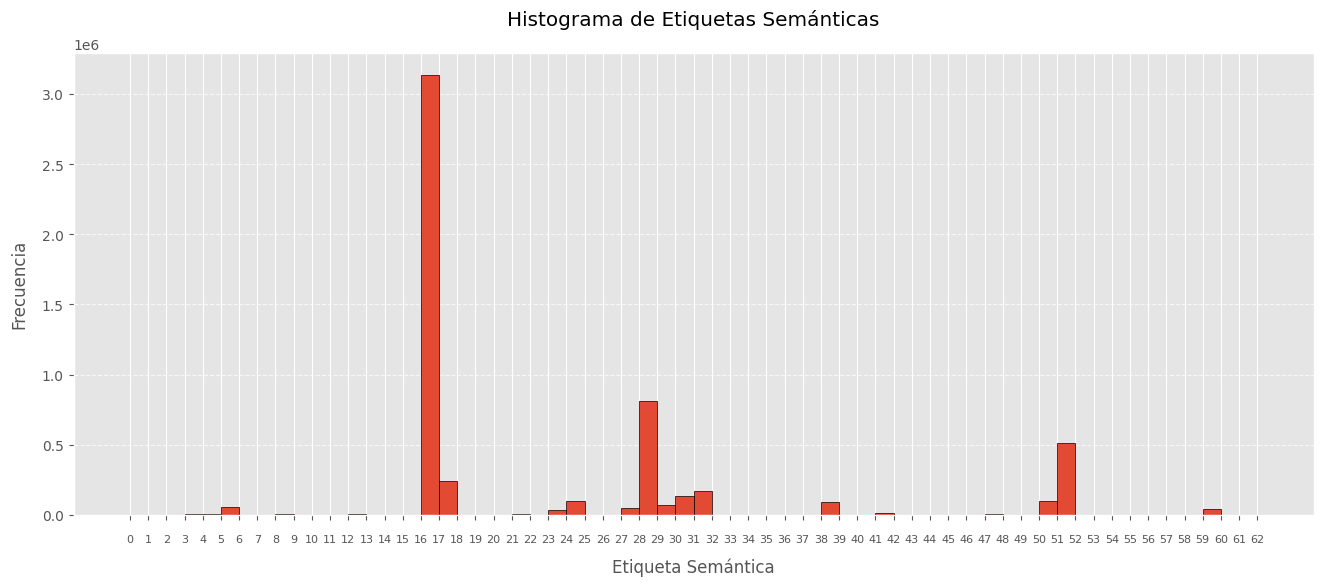
Aplicando este redimensionamiento con un factor de 0.1 sobre todos los barridos de un escenario específico, se logra una reducción significativa en el número de puntos, preservando la disposición original de las etiquetas dentro del escenario. A continuación, se presentan los histogramas de etiquetas correspondientes a la concatenación de todas las nubes de puntos originales y sus versiones redimensionadas en el escenario ‘2022-07-22_flight’ del conjunto train del dataset GOOSE. Se puede obeservar como se reduce 10 veces el tamaño en puntos del escenario pero mantiene la disposición exacta de las etiquetas.
Mejoras en la implementación de PointNet
He incorporado varias mejoras en la estructura del modelo como la inclusión de BatchNormalization y la inclusión de la T-Net para la transformación de entrada y la optimización de la estructura general de la red.
La T-Net es una subred que aprende matrices de transformación que pueden corregir deformaciones espaciales en los datos de entrada. Su objetivo es mejorar la invariancia geométrica de la red, asegurando que las coordenadas de los puntos se alineen de manera más consistente antes de ser procesadas por las capas convolucionales.
def tnet(inputs, k):
x = layers.Conv1D(64, kernel_size=1, activation='relu')(inputs)
x = layers.BatchNormalization()(x)
x = layers.Conv1D(128, kernel_size=1, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv1D(1024, kernel_size=1, activation='relu')(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dense(512, activation='relu')(x)
x = layers.Dense(256, activation='relu')(x)
x = layers.Dense(k * k, kernel_initializer=tf.keras.initializers.GlorotUniform())(x)
return layers.Reshape((k, k))(x)