
Investigación de estrategias de submuestreo, Primera versión de PoinNet-Tnet funcional
Esta semana he investigado diversas técnicas utilizadas para inferir información a partir de la nube de puntos en los modelos implementados en los repositorios Open3D-ML y el repositorio oficial de PointNet de la Universidad de Stanford. También he realizado mejoras en el pipeline de PointNet, terminando la primera versión funcional de la arquitectura con la TNet de entrada y la TNet de alineación de características añadidas.
Técnicas de Submuestreo
Los modelos que están implementados en Open3D-ML como KPConv y RandLA-Net, utilizan técnicas de submuestreo por zonas, consiguiendo no redimensionar la nube de puntos ni a la salida en proceso de entrenamiento, ni en nuevas inferencias a este.
En PointNet, la estrategia es cortar las nubes de puntos en un número de puntos predefinido en los parámetros de lanzamiento del modelo. En la siguiente sección de código perteneciente al archivo pointnet/sem_seg/train.py del repositorio, se muestra como corta las nubes de puntos previamente cargadas de archivos .h5 y realiza un shuffle de los índices de las nubes de puntos para que el proceso de entrenamiento sea invariante al orden original de estas.
Redimensionado de puntos en PointNet (Stanford University)
def train_one_epoch(sess, ops, train_writer):
""" ops: dict mapping from string to tf ops """
is_training = True
log_string('----')
current_data, current_label, _ = provider.shuffle_data(train_data[:,0:NUM_POINT,:], train_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
. . .
Al tratarse de un modelo más sencillo, maneja la información redimensionando la nube de puntos a la salida.
Cambios de Submuestreo Propuestos
Dada la naturaleza de las nubes LiDAR que se manejará en el entrenamiento de este modelo (dimenisones variables, densidades variables, configuraciones variables según dataset), se propone redimensionar las nubes de puntos en el pipeline a un tamaño fijo, haciendo una permutación aleatoria de los índices de los puntos seleccionando los ‘n’ primeros. A ser preciso un valor de 16.384 puntos para simplificar las tareas en GPU. Todos los dataset tienen una resulución mínima superior a este umbral. En inferencia de nubes de otras fuentes, se podria densificar para cumplir con el shape de entrada.
Para recuperar la resolución original de la imagen he pensado en ejecutar el algoritmo KNN para la asignación semantica de los puntos restantes sin segmentar. El algoritmo KNN podría introducir ruido en las fornteras entre objetos, pero sería factible. Existen otros algoritmos más complejos que se podrían investigar para la recuperación de resolución.
Primera versión de PointNet-TNet
He conseguido implementar la mejora de las dos TNet en la versión anterior y la correcta compilación de este. La primera TNet aprende una matriz de transformación que alinea las nubes de puntos en un espacio canónico y la segunda alinea las caracteristicas extraidas de la primera capa MPL. Esta implementación solo es válida para caracteristicas geométricas, próximamente mejoraré el código para poder añadir al modelo características cualitativas de los puntos como las remisiones.
TNet Layers
inputs = tf.keras.Input(shape=(None, input_dim))
# Aplicar T-Net en la entrada para alinear puntos
x = tnet(inputs, input_dim)
# MLP Layers
x = layers.Conv1D(64, 1, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv1D(128, 1, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv1D(64, 1, activation='relu')(x)
x = layers.BatchNormalization()(x)
# Aplicar T-Net en caracteristicas
x = tnet(x, 64)
Realicé una prueba de validación funcional del pipeline de entrenamiento. Se empleó un subconjunto de 335 barridos LiDAR, en el cual no estaban representadas todas las clases del dataset completo. Sin embargo, el objetivo principal no era evaluar el rendimiento final del modelo, sino verificar la correcta ejecución del flujo de entrenamiento, asegurando que la implementación es funcional en su totalidad y capaz de procesar los datos correctamente.
Prueba de validación funcional del pipeline
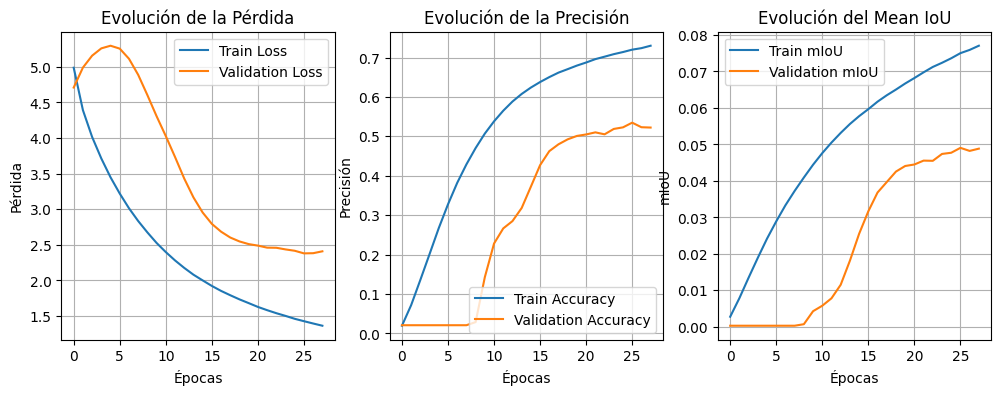
Para optimizar el desempeño del entrenamiento, se establecerá próximamente un pipeline que incorporará experimentos con datasets sintéticos básicos y con el GOOSE dataset, aplicando una agrupación de clases para ajustar con mayor precisión el problema a resolver.