
Entrenamiento con Toronto3D, Agrupación de etiquetas en categorías, Experimentos baseline con GOOSE
Esta semana he dedicado tiempo a comprobar el funcionamiento del modelo en tareas de segmentación con un dataset preparado como Toronto3D. También he empezado a pensar el agrupamiento en categorías de las etiquetas de GOOSE y he realizado los primeros experimentos baseline con el dataset completo.
Agrupacion en categorias (GOOSE)
Se han agrupado en 13 categorias, las propuestas por GOOSE en su apartado de documentación sobre las clases, pero diferenciando entre vegetación transitable y no transitable. Estas son:
- Vegetación no transitable
- Vegetación transitable
- Vehículos
- Construcciones
- Señales
- Objetos
- Caminos
- Terreno
- Void
- Humanos
- Animales
- Cielo
- Agua
Se ha realizado un estudio de la distrubución de etiquetas (categorías) en el conjunto de entrenamiento y validación tras redimensionar las nubes de puntos al shape de entrada al modelo. Estos son los resultados:
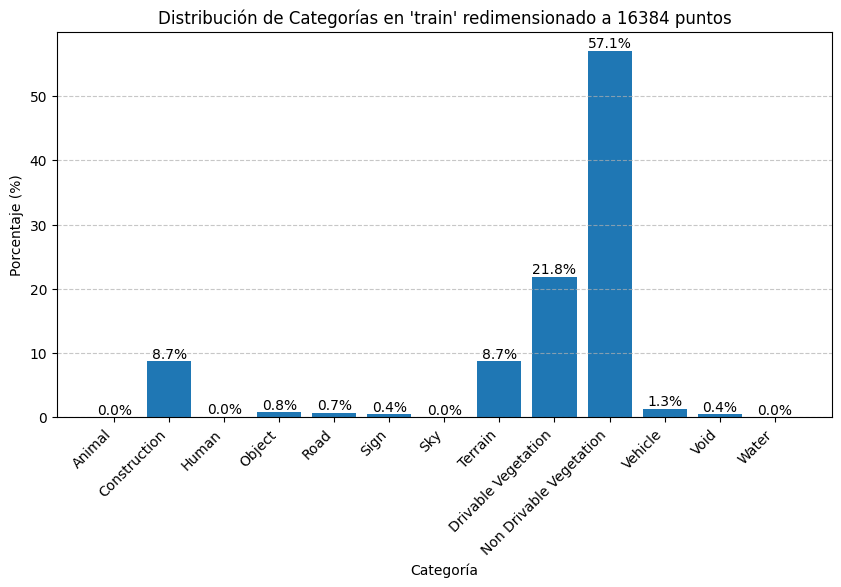
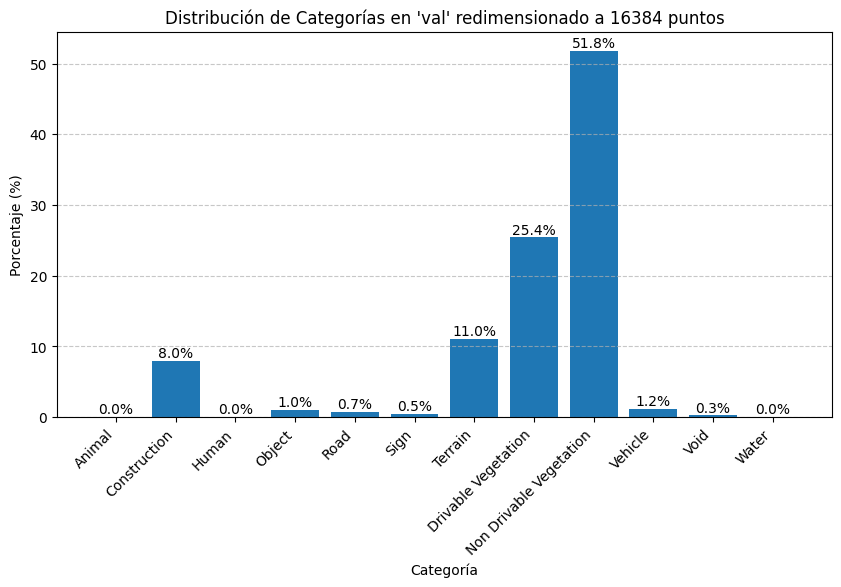
Algunas categorías como Agua, Cielo, Humanos y Animales tienen una representacion del 0% aproximadamente, por lo que se juntaron con el conjunto Void para los experimentos baseline
Entrenamiento Toronto3D
Se probó la capacidad de entrenamiento del modelo implementado la semana pasada con un dataset optimizado y preparado. Consiguiendo resultados decentes en la segmentación semántica de puntos
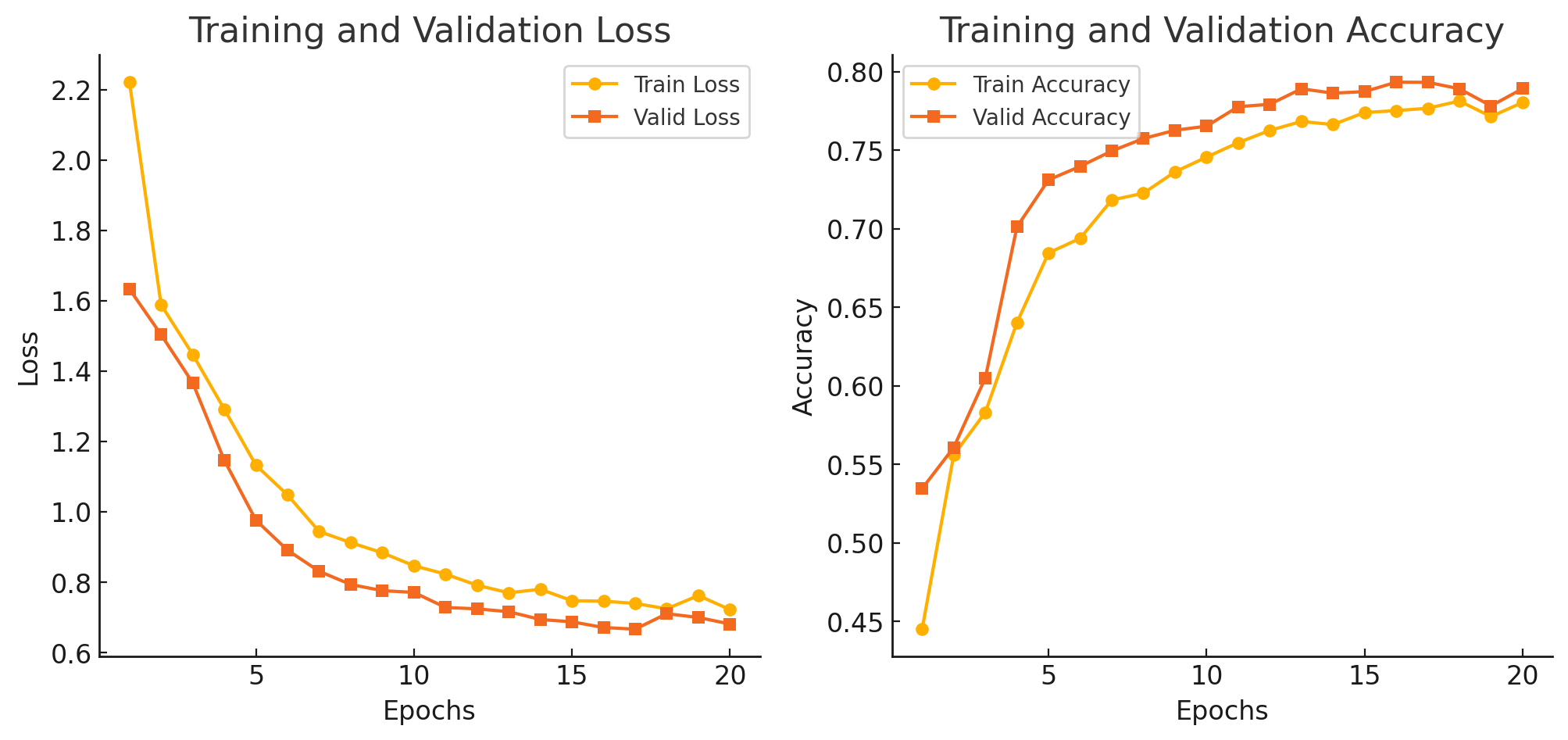
Las figuras de mérito en el último epoch son:
Epoch 20:
Train Loss: 0.7220 - Train Accuracy: 0.7804 - Train mIoU: 0.6399
Valid Loss: 0.6811 - Valid Accuracy: 0.7892 - Valid mIoU: 0.6517
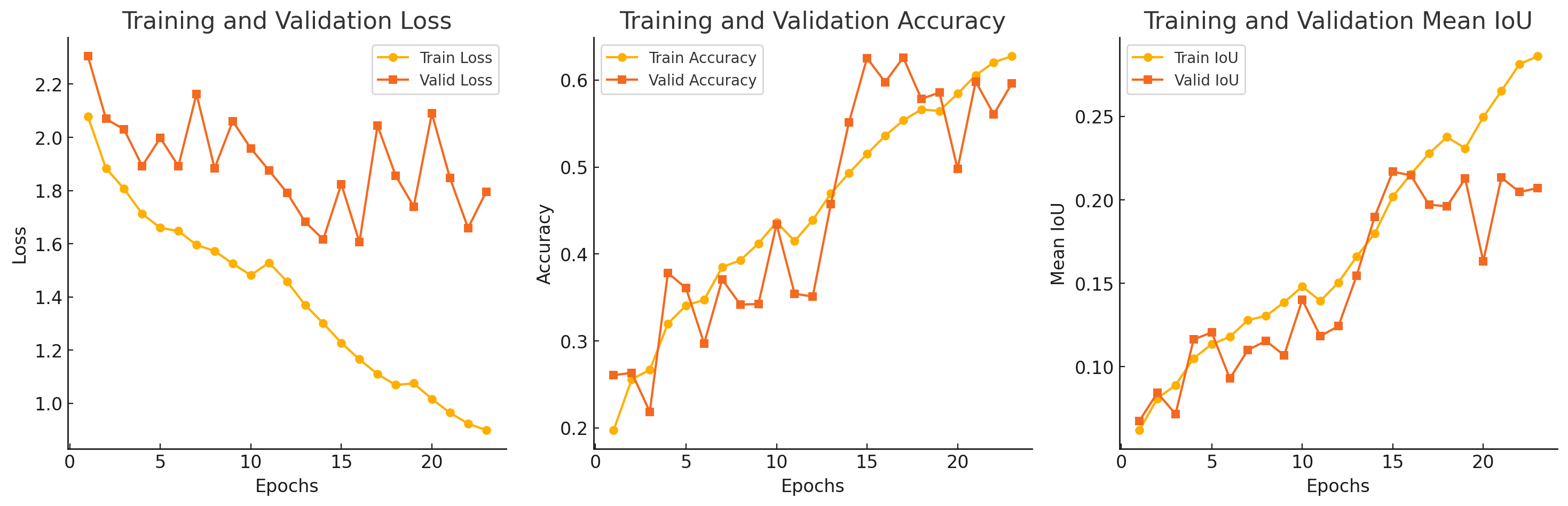
Experimentos baseline con GOOSE dataset
Se han realizado varios experimentos baseline principalmente para dos resoluciones de submuestreo (256 y 16486 puntos por nube). No se normalizaron las características geométricas entrantes.
Estos resultados para la primera configuración (256) en 60 épocas de entrenamiento:
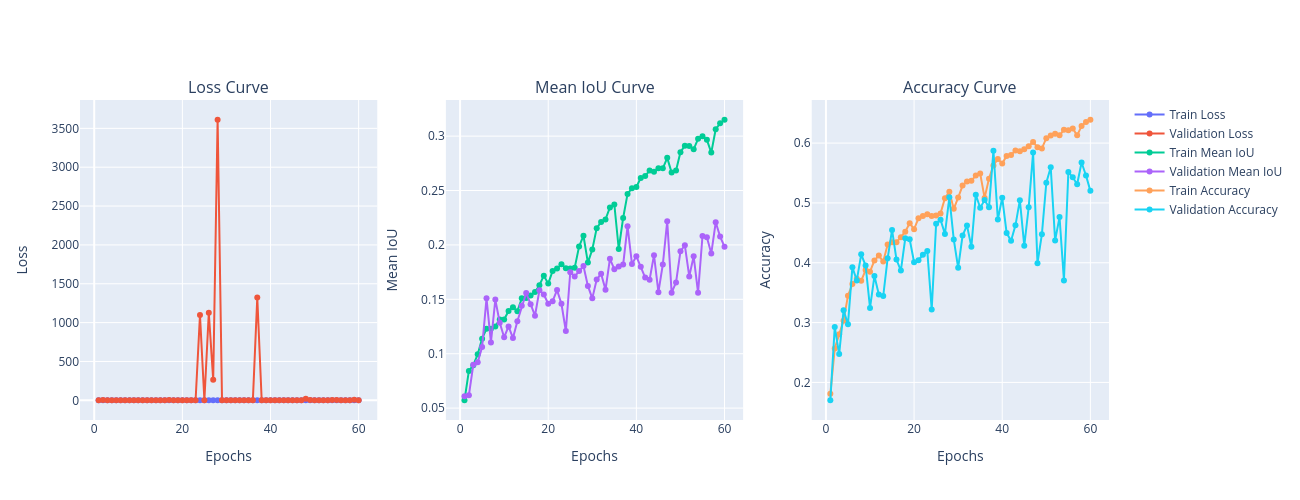
Estos son los resultados de la segunda configuración (16384) en 24 épocas de entrenamiento:
Mejoras propuestas
Debido al bajo rendimiento, se compararon las diferencias con la configuración realizada en Toronto3D según sus características. Para este dataset se tenia un conjunto global de puntos que recorría 1km de una calle en Toronto. Se dividieron en nubes de 4092 contiguas y se descartaron los puntos restantes a la división. De esta manera se obtiene mucha resolución espacial y el modelo aprende mejor.
Se propone:
- Recortar las nubes a un rango cercano al sensor LiDAR para reducir el ruido en entrenamiento por puntos extremadamente alejados y sin relevancia para el problema.
- Concatenar todos los puntos de todas las nubes y subdividir en nubes más pequeñas, como para Toronto3D.
- Normalizar las caracteristicas espaciales para optimizar el entrenamiento