
DataLoader de subnubes aleatorias en entrenamiento, Separacción sistemática en subnubes de todo el Dataset, Entrenamiento de PointNet
Esta semana me he dedicado a intentar mejorar el rendimiento del entrenamiento aplicando dos enfoques distintos. El primero, desarrollar un DataLoader en Tensorflow Keras para cargar dinámicamente la información de interés, el cual empeoró el rendimiento del entrenamiento. También se realizó un pipeline para dividir todas las nubes originales en subnubes de tamaño fijo sin sacrificar prácticamente la densidad original de la nube. Este proceso es sistemático. El resultado del entrenamiento con esta división sistemática de las nubes originales no mejoró tampoco el entrenamiento realizado con el submuestreo aleatorio de las nubes.
DataLoader (Subnubes aleatorias)
Para cada nube original (previamente recortada radialmente al espacio cercano al sensor, 25m) se selecciona un punto aleatorio (centroide) y se calculan mediante KDTree los N-1 puntos más cercanos. Se carga esta subnube extraida al batch de datos. Si el batch se constituye de 16 subnubes, se realiza este proceso en 16 nubes originales del conjunto de entrenamiento. Cada batch se eligen las 16 siguientes nubes originales.
El DataLoader diferencia si es para entrenamiento o validación. En validación, divide cada nube en subnubes del mismo tamaño pero sin sacrificar información.
class PointCloudGenerator(Sequence):
def __init__(self, bin_files, label_files, num_points, mode='train', batch_size=32):
self.bin_files = bin_files
self.label_files = label_files
self.num_points = num_points
self.batch_size = batch_size
self.mode = mode # 'train' o 'val'
def __len__(self):
"""Número total de batches por epoch"""
return len(self.bin_files) // self.batch_size
def __getitem__(self, idx):
"""Genera un batch de datos dinámicamente"""
batch_bin_files = self.bin_files[idx * self.batch_size : (idx + 1) * self.batch_size]
batch_label_files = self.label_files[idx * self.batch_size : (idx + 1) * self.batch_size]
x_batch, y_batch = [], []
for bin_file, label_file in zip(batch_bin_files, batch_label_files):
points, indices = load_bin_file(bin_file)
labels = load_label_file(label_file, indices)
# Filtrar los puntos dentro del rango de (-25, 25)
mask = (points[:, 0] >= -25) & (points[:, 0] <= 25) & \
(points[:, 1] >= -25) & (points[:, 1] <= 25) & \
(points[:, 2] >= -25) & (points[:, 2] <= 25)
points, labels = points[mask], labels[mask]
if len(points) < self.num_points:
continue
if self.mode == 'train':
# Construir el KDTree dinámicamente solo para esta nube
tree = cKDTree(points)
sub_points, sub_labels = self._get_train_sample(points, labels, tree)
x_batch.append(sub_points)
y_batch.append(sub_labels)
else:
sub_points_list, sub_labels_list = self._get_val_samples(points, labels)
x_batch.extend(sub_points_list)
y_batch.extend(sub_labels_list)
return np.array(x_batch, dtype=np.float32), np.array(y_batch, dtype=np.uint8)
def _get_train_sample(self, points, labels, tree):
"""Obtiene una subnube de entrenamiento con N vecinos más cercanos"""
center_idx = np.random.randint(len(points)) # Selecciona un punto aleatorio
_, neighbor_indices = tree.query(points[center_idx], k=self.num_points) # Obtiene los N vecinos más cercanos
return points[neighbor_indices], labels[neighbor_indices]
def _get_val_samples(self, points, labels):
"""Divide la nube preprocesada en subnubes de N puntos para validación"""
num_full_batches = len(points) // self.num_points
indices = np.random.choice(len(points), num_full_batches * self.num_points, replace=False)
subclouds = points[indices].reshape(num_full_batches, self.num_points, 3)
sublabels = labels[indices].reshape(num_full_batches, self.num_points)
return [subclouds[i] for i in range(num_full_batches)], [sublabels[i] for i in range(num_full_batches)]
Ventana Aleatoria (Centroide aleatorio)
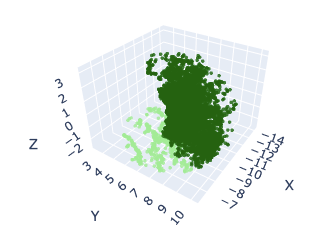
Sin embargo esta estrategia no funcionó bien. Cada época de entrenamiento dura 30 min y se evaluó en 2 épocas con learning rate decreciente a la mitad. El accuracy y MIoU se mantuvo constante practicamente durante las 2 épocas en 0.105 y 0.0375 respectivamente. Estos resultados son muy malos y reflejan que la estrategia no es buena o no está bien formulada del todo.
Una posible solución es seleccionar varios centroides aleatorios por nube original hasta recorrer toda la información disponible en esta o casi toda la información, de esta forma el entrenamiento podría ser más eficiente en tiempo y resultados.
Separación sistemática en subnubes
Se divide sistemáticamente cada nube del dataset en varias subnubes de tamaño fijo (N) sacrificando como máximo N-1 puntos, manteniendo así la densidad original y la forma de la nube original. La idea es entrenar con todas las subnubes y asi recorrer si o si toda la información del conjunto de entrenamiento en cada época.
NUM_POINTS = 4096 # Tamaño de subnube fijo
# Mapeo de categorías
category_mapping = {
0: [43, 38, 58, 29, 41, 42, 44, 39, 55], # Construction
1: [4, 45, 6, 40, 60, 61, 33, 32, 14], # Object
2: [7, 22, 9, 26, 11, 21], # Road
3: [48, 47, 1, 19, 46, 10, 25], # Sign
4: [23, 3, 24, 31, 2], # Terrain
5: [51, 50, 5, 18], # Drivable Vegetation
6: [28, 27, 62, 52, 16, 30, 59, 17], # Non Drivable Vegetation
7: [13, 15, 12, 36, 57, 49, 20, 35, 37, 34, 63], # Vehicle
8: [8, 56, 0, 53, 54], # Void
}
label_to_category = {label: cat for cat, labels in category_mapping.items() for label in labels}
def map_labels(labels: np.ndarray) -> np.ndarray:
"""Convierte etiquetas en categorías"""
return np.array([label_to_category.get(label, 8) for label in labels], dtype=np.uint8)
def load_bin_file(bin_path: str, num_points: int = NUM_POINTS, radius: float = 25.0) -> List[Tuple[np.ndarray, np.ndarray]]:
"""Carga una nube de puntos y la divide en subnubes de tamaño fijo `num_points`"""
# Cargar la nube de puntos
points = np.fromfile(bin_path, dtype=np.float32).reshape(-1, 4)[:, :3]
# Filtrar puntos dentro del radio dado
distances = np.linalg.norm(points, axis=1)
mask = distances <= radius
indices = np.arange(len(points))[mask]
points = points[mask]
num_available = points.shape[0]
if num_available < num_points:
return [] # Si no hay suficientes puntos, se descarta la nube
# Ajustar el número de puntos a un múltiplo exacto de `num_points`
num_valid = num_available - (num_available % num_points)
# Seleccionar los primeros `num_valid` puntos
points = points[:num_valid]
indices = indices[:num_valid]
# Dividir en subnubes de `num_points`
num_subnubes = num_valid // num_points
subnubes = [
(points[i * num_points: (i + 1) * num_points], indices[i * num_points: (i + 1) * num_points])
for i in range(num_subnubes)
]
return subnubes
def load_label_file(label_path: str, indices: np.ndarray) -> np.ndarray:
"""Carga las etiquetas y las mapea a las categorías correspondientes"""
labels = np.fromfile(label_path, dtype=np.uint32) & 0xFFFF
return map_labels(labels[indices])
def load_dataset(bin_files: List[str], label_files: List[str], num_points: int = NUM_POINTS) -> Tuple[np.ndarray, np.ndarray]:
"""Carga el conjunto de datos dividiendo las nubes grandes en subnubes de tamaño `num_points`"""
x_data, y_data = [], []
for bin_f, label_f in tqdm(zip(bin_files, label_files), total=len(bin_files), desc="Cargando datos"):
subnubes = load_bin_file(bin_f, num_points)
for points, indices in subnubes:
labels = load_label_file(label_f, indices)
x_data.append(points)
y_data.append(labels)
return np.array(x_data, dtype=np.float32), np.array(y_data, dtype=np.uint8)
def get_file_paths(data_dir: str) -> List[str]:
"""Obtiene rutas de archivos en un directorio."""
return sorted([str(f) for f in Path(data_dir).glob("*.*")])
def load_all_data(x_train_dir: str, y_train_dir: str, x_val_dir: str, y_val_dir: str) -> Tuple[np.ndarray, np.ndarray, np.ndarray, np.ndarray]:
"""Carga los datos de entrenamiento y validación en subnubes de tamaño fijo"""
x_train_files = get_file_paths(x_train_dir)
y_train_files = get_file_paths(y_train_dir)
x_val_files = get_file_paths(x_val_dir)
y_val_files = get_file_paths(y_val_dir)
assert len(x_train_files) == len(y_train_files), "Número de archivos x_train y y_train no coincide"
assert len(x_val_files) == len(y_val_files), "Número de archivos x_val y y_val no coincide"
print("Cargando datos de entrenamiento...")
x_train, y_train = load_dataset(x_train_files, y_train_files)
print("Cargando datos de validación...")
x_val, y_val = load_dataset(x_val_files, y_val_files)
return x_train, y_train, x_val, y_val
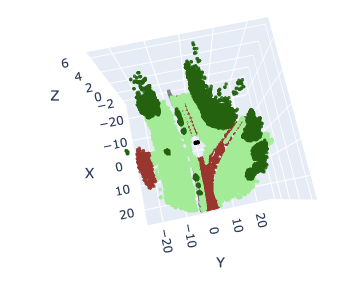
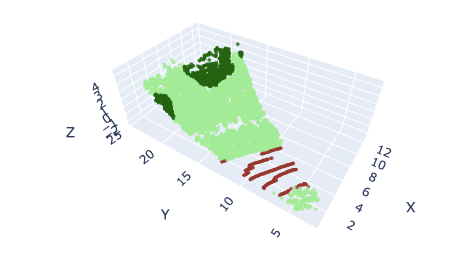
Los sensores LiDAR guardan la información de manera ordenada. El sensor va tomando muestras verticalmente y cuando acaba de mapear el angulo completo, gira horizontalmente. Esta división en subnubes al ser respecto a los índices de los puntos, generará subnubes con un aspecto de sección triangular (en planta), y dependiendo del tamaño de subnube seleccionado, la sección sera mas ancha o más fina.
Nube original
Subnube de 16384 puntos
Subnube de 4086 puntos
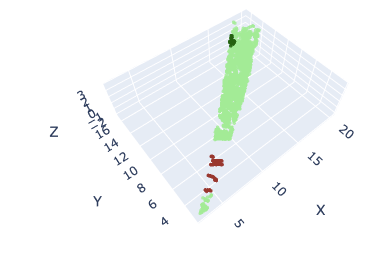
Los resultados del entrenamiento para esta estrategia no mejoran tampoco al entrenamiento con el submuestreo en las nubes originales y cada época también tarda unos 30 minutos. En 2 épocas se obtuvo un 0.7426 de accuracy (train) y un 0.26 de MIoU (train), 0.56 de accuracy (val) y 0.16 de MIoU (val).
Conclusión
Los resultados para los dos experimentos son malos, el primero no aprende correctamente y el segundo sobreajusta demasiado muy rápido. Este modelo funcionó bien para entrenar con Toronto3D, un dataset LiDAR en entorno de ciudad (estructurado), con resultados de 80% en acuraccy y 63,5% en MIoU. Puede ser que al ser entornos no estructurados el modelo no responda de la misma manera y la tarea se dificulte. Se deben buscar alternativas para un nuevo DataLoader o cambiar la estrategia a un Sliding Window con el bloque clasificador, incluso sacrificar algo de eficiencia computacionale en inferencia y cambiar a un modelo más potente de segmentación semántica.