Entrenamiento afinado de PointNet++, Prueba de modelo con Rellis3D
Esta semana me he dedicado a ajustar el entrenamiento de PointNet++ para mejorar el resultado de la segmentación en la medida de lo posible. Para ello he ajustado varios hiperparámetros referentes a la propia arquitectura y proceso de entrenamiento. También he probado el modelo con nubes de puntos del dataset Rellis3D. El modelo tiene problemas con Rellis ya que la característica remission que se utilizó para entrenar con GOOSE dataset varía significativamente en media y varianza con Rellis3D. Aun no he podido investigar la causa de esto a fondo, pero tendrá que ver con las características de los sensores utilizados o las configuraciones de estos.
Entrenamiento PointNet++
Para afinar los resultados del entrenamiento de PointNet++ he modificado el tamaño de las Query Balls (Ventanas 3D de tres tamaños que componen la estructura jerárquica) adaptándolas al entorno espacial realista de GOOSE dataset o cualquier nube de puntos con tamaños absolutos. He elegido los tamaños de 1, 2.5 y 5 metros de radio. La estructura jerárquica consigue recoger características de relaciones espaciales mucho más complejas.
También he añadido un learning rate dinámico para ajustarlo a cada época y así ayudar a converger de manera más estable.
Composición del de PointNet++ ajustado
class PointNet2SemSeg(nn.Module):
def __init__(self, num_classes=9, normal_channel=False):
super(PointNet2SemSeg, self).__init__()
in_channel = 6 if normal_channel else 3
# Set Abstraction layers (encoder)
self.sa1 = PointNetSetAbstraction(npoint=1024, radius=1, nsample=32, in_channel=in_channel, mlp=[32, 32, 64], group_all=False)
self.sa2 = PointNetSetAbstraction(npoint=256, radius=2.5, nsample=64, in_channel=64 + 3, mlp=[64, 64, 128], group_all=False)
self.sa3 = PointNetSetAbstraction(npoint=64, radius=5, nsample=256, in_channel=128 + 3, mlp=[128, 128, 256], group_all=False)
# Feature Propagation layers (decoder)
self.fp3 = PointNetFeaturePropagation(in_channel=256 + 128, mlp=[256, 256])
self.fp2 = PointNetFeaturePropagation(in_channel=256 + 64, mlp=[256, 128])
self.fp1 = PointNetFeaturePropagation(in_channel=128, mlp=[128, 128, 128])
# MLP profundo para segmentación con remission (entrada: 128+1=129 canales)
self.conv1 = nn.Conv1d(129, 128, 1)
self.bn1 = nn.BatchNorm1d(128)
self.drop1 = nn.Dropout(0.5)
self.conv2 = nn.Conv1d(128, 64, 1)
self.bn2 = nn.BatchNorm1d(64)
self.drop2 = nn.Dropout(0.3)
self.conv3 = nn.Conv1d(64, 32, 1)
self.bn3 = nn.BatchNorm1d(32)
self.drop3 = nn.Dropout(0.3)
self.conv4 = nn.Conv1d(32, num_classes, 1)
def forward(self, x, remission):
"""
x: (B, 3, N) -> Coordenadas
remission: (B, 1, N) -> Remission
"""
B, _, N = x.shape
l0_xyz = x
l0_points = None # No usamos características adicionales al inicio
# Encoder
l1_xyz, l1_points = self.sa1(l0_xyz, l0_points)
l2_xyz, l2_points = self.sa2(l1_xyz, l1_points)
l3_xyz, l3_points = self.sa3(l2_xyz, l2_points)
# Decoder
l2_points = self.fp3(l2_xyz, l3_xyz, l2_points, l3_points)
l1_points = self.fp2(l1_xyz, l2_xyz, l1_points, l2_points)
l0_points = self.fp1(l0_xyz, l1_xyz, l0_points, l1_points)
# Concatenar remission antes del MLP final
l0_points = torch.cat([l0_points, remission], dim=1)
# MLP profundo para clasificación por punto
x = F.relu(self.bn1(self.conv1(l0_points)))
x = self.drop1(x)
x = F.relu(self.bn2(self.conv2(x)))
x = self.drop2(x)
x = F.relu(self.bn3(self.conv3(x)))
x = self.drop3(x)
x = self.conv4(x)
x = F.log_softmax(x, dim=1)
return x
Configuración del Optimizador Adam
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import ReduceLROnPlateau
# Pesos para la función de pérdida
# [1.36, 11.63, 14.13, 18.82, 1.09, 0.49, 0.20, 6.70, 20.54] ideales
alpha = torch.tensor([0.8, 1, 2, 1, 0.85, 0.5, 0.3, 1, 1], dtype=torch.float32).to('cuda')
alpha = alpha / alpha.sum()
criterion = nn.NLLLoss(weight=alpha)
# criterion = PointNetSegLoss(alpha=alpha, gamma=2, size_average=True, dice=False) Focal Loss (no funcional)
optimizer = optim.Adam(model.parameters(), lr=0.01)
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=5, verbose=True, min_lr=1e-6)
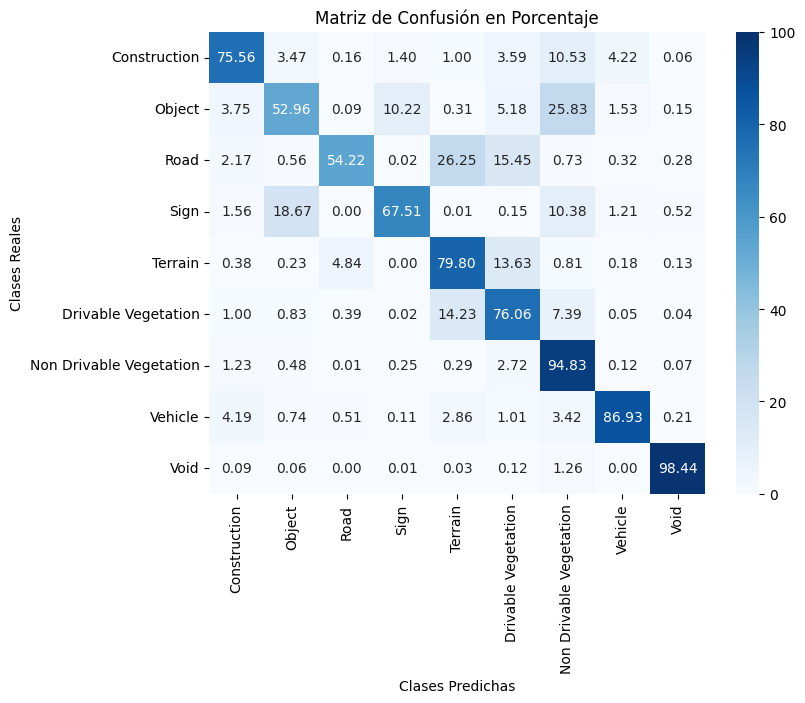
Resultados del Entrenamiento
Los resultados mejoraron tanto en métricas como en interpretación visual. En 8 épocas de entrenamiento se obtuvo un 83 % de Accuracy y un 42.8 % de mIoU.
Matriz de confusión
Prueba del modelo con Rellis3D
Desarrollé un pipeline para realizar la inferencia de nubes de puntos del dataset Rellis3D utilizando el modelo y visualizar los resultados. No hice agrupaciones de etiquetas para evaluar numericamente la precisión, únicamente me dio tiempo a viualizar los resultados con las 9 clases con las que está entrenado el modelo. Los resultados fueron malos porque la característica remission no es de la misma naturaleza. Se investigará la naturaleza de los datos de Rellis3D para encontrar la causa exacta de este problema. Seguramente las características adicionales a la geometría (x,y,z) varían su contenido dependiendo de las configuraciones de los sensores o sus propias características.
Se puede apreciar como la caracteristica remission confunde al modelo y en los puntos más cercanos tiende a segmentar como ‘Sign’ (señal, con superficie reflectante).
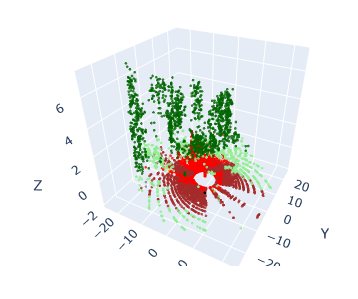
Nube con mapa de color (Remission)
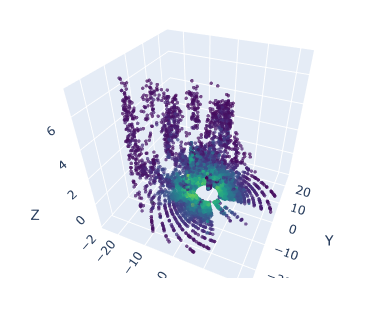
Nube de Etiquetas Predichas