
Percepción
Índice
Clasificación vs detección vs segmentación
La clasificación implica asignar etiquetas o clases a imágenes o regiones específicas. Sin embargo, esta técnica no proporciona información sobre las ubicaciones de los objetos, simplemente responde a la pregunta de si un objeto específico está presente, por ejemplo: ¿hay un perro?

La detección es el proceso que nos permite identificar varios objetos, diferentes instancias de un mismo objeto y sus ubicaciones en una imagen, proporcionando sus bounding boxes. Responde a la pregunta: ¿qué hay en la imagen y dónde está?. Se suele utilizar para tareas en tiempo real, un ejemplo en conducción autónoma es la detección de peatones, pues nos basta con señalar y conocer su posición en la escena mediante un cuadro delimitador.

La segmentación consiste en dividir una imagen en regiones significativas con el objetivo de identificar objetos. Esta técnica abarca dos enfoques principales:
- La segmentación semántica asigna una clase a cada uno de los píxeles de la imagen, pero no distingue entre diferentes instancias de la misma clase.
- La segmentación de instancias identifica y delimita cada objeto individual en la imagen asignándole una etiqueta única, pero no las agrupa semánticamente. La combinación de ambas técnicas se conoce como segmentación panóptica.
La segmentación nos proporciona información detallada sobre los límites y regiones de cada objeto: ¿qué pixel corresponde a cada objeto? En conducción autónoma se suele utilizar para la detección de la calzada.

Deep learning
La Inteligencia Artificial es una técnica que permite a una máquina imitar comportamientos humanos. El Machine Learning, o aprendizaje automático, es el método para lograr IA a través de algoritmos entrenados con datos.
El deep learning es un tipo de machine learning inspirado por la estructura del cerebro humano, con las redes neuronales como base principal. Es capaz de reconocer patrones en los datos de entrada, a diferencia del machine learning, al cual hay que proporcionarle cuáles son las características distintivas, por ejemplo el color para distinguir entre tomates y limones. Los desafíos del deep learning son la gran cantidad de datos requerida, lo cual demanda potencia computacional elevada y conlleva procesos de entrenamiento largos.
Redes neuronales
El set de datos para el entrenamiento de una red neuronal se divide en tres bloques:
- Training data: entrenar el modelo.
- Validating data: evaluar el modelo durante el entrenamiento.
- Testing data: evaluar el rendimiento del modelo al finalizar el entrenamiento.
Las redes neuronales pueden resolver dos tipos de problemas: clasificación (salida finita) y regresión (salida continua). Una red neuronal se divide en tres bloques: la capa de entrada, las capas ocultas y la capa de salida, cuyo número de neuronas debe ser igual al número de salidas de la red. El número de neuronas de las capas ocultas se determina mediante experimentación.
En la siguiente imagen podemos ver un ejemplo de red neuronal, en el que cada neurona de una capa está conectada a todas las neuronas de la siguiente capa, esto se conoce como fully connected. Estos son algunos términos que debemos conocer para entender la estructura de una red neuronal:
- w: matriz de pesos
- b: matriz de término independiente
- d: número de características de entrada
- p: número de neuronas y salidas de una capa
- f: función de activación
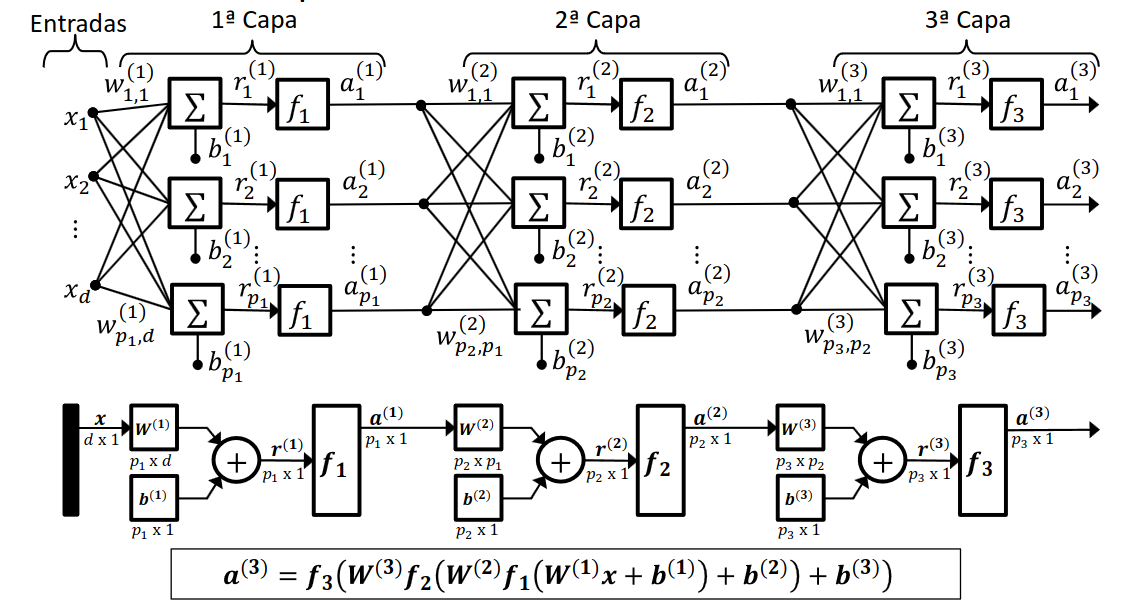
El proceso de entrenamiento se divide en dos etapas:
- Propagación hacia delante: de entrada a salida, cuyo objetivo es hacer una predicción.
- Combinación lineal: r = x * w + b.
- En el caso de ser una neurona y dos características de entrada: r = x1 * w1 + x2 * w2 + b.
- Las funciones de activación pretenden introducir no linealidad en la red, las más usadas son ReLu = max(r, 0) y softmax, usada para resolver problemas de clasificación multiclase. Se hace una predicción, que es el resultado al aplicar la función de activación: a = ŷ = f(r).
- Combinación lineal: r = x * w + b.
- Propagación hacia atrás: de salida a entrada, cuyo objetivo es actualizar los pesos y términos independientes.
- La función de pérdida evalúa el error al comparar la salida predicha con la salida real: L(y, ŷ). Existen múltiples métodos para calcularla, por ejemplo, está binary cross-entropy para clasificación binaria y sparse categorical cross-entropy para clasificación multiclase.
- Se emplea un algoritmo de optimización respecto a la función de pérdida para actualizar los pesos y términos independientes. Uno de estos métodos es el descenso por gradiente: w = w - α * ∇L(y, ŷ).
En la fase de actualización, se emplea un parámetro llamado tasa de aprendizaje (α) para controlar la magnitud de los ajustes realizados en los pesos de la red neuronal durante cada paso de entrenamiento. Una tasa de aprendizaje muy grande puede provocar oscilaciones y dificultar la convergencia al punto óptimo, mientras que una tasa muy pequeña puede prolongar significativamente el tiempo de entrenamiento y el consumo de recursos computacionales
El entrenamiento se detiene cuando:
- Se ha alcanzado el número máximo de épocas indicado por el usuario.
- Se ha alcanzado la precisión deseada.
- El error de validación diverge del error de entrenamiento, lo cual significa que estamos sobreajustando la red.

Redes neuronales convolucionales
Las redes neuronales convolucionales o CNN se usan para la clasificación de imágenes. Estas imágenes pueden tener dos dimensiones (filas x columnas), lo que corresponde a imágenes en escala de grises, o tres dimensiones (filas x columnas x color), correspondientes a imágenes en RGB.
En el siguiente ejemplo, podemos observar las diferentes capas que componen una CNN diseñada para un conjunto de datos en escala de grises (2D). Analizaremos cada una de estas capas:
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])

Capa de convolución
Se aplican kernels (o filtros) de dimensiones nxn para extraer características locales de la imagen. El kernel se va deslizando a lo largo de la imagen, calculando la suma ponderada de los píxeles en cada ubicación. Cada filtro produce un mapa de características que contiene las características relevantes de la imagen. En el ejemplo proporcionado, se aplican 32 filtros en la primera y cuarta capa de convolución y 64 en la segunda y tercera.
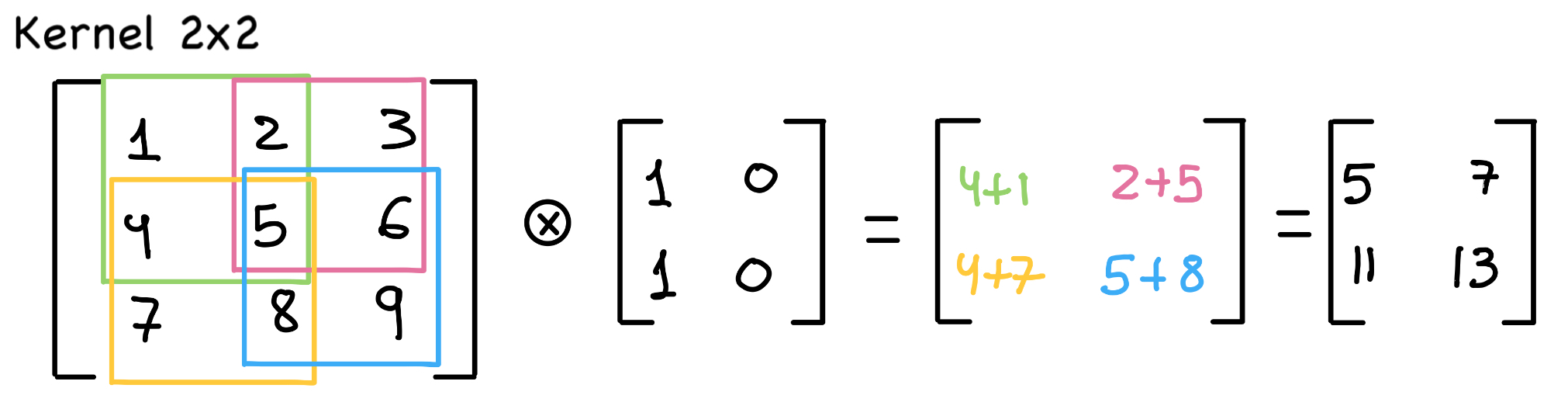
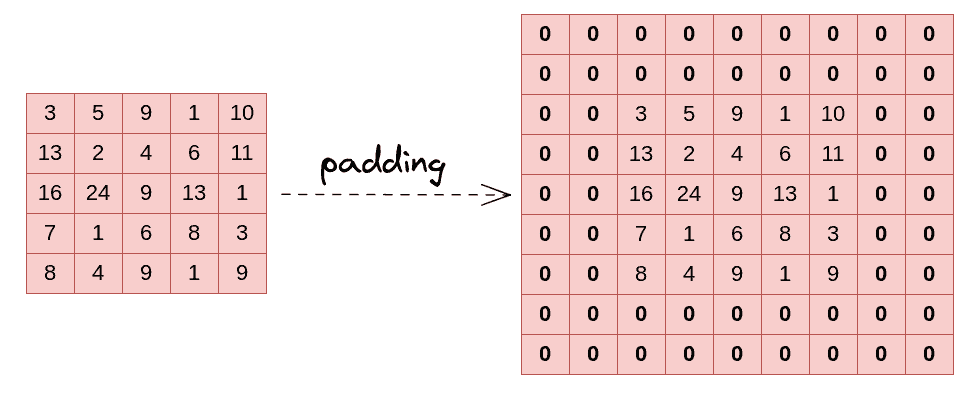
La operación de convolución reduce las dimensiones de la matriz de características. Para mantener las dimensiones constante o evitar que lleguen a cero, podemos aplicar la técnica de padding, que consiste en aumentar las dimensiones añadiendo ceros sin modificar la información original. El padding es un parámetro flexible que puede añadirse a lo largo de toda la imagen, solo en la parte superior o en cualquier combinación deseada.
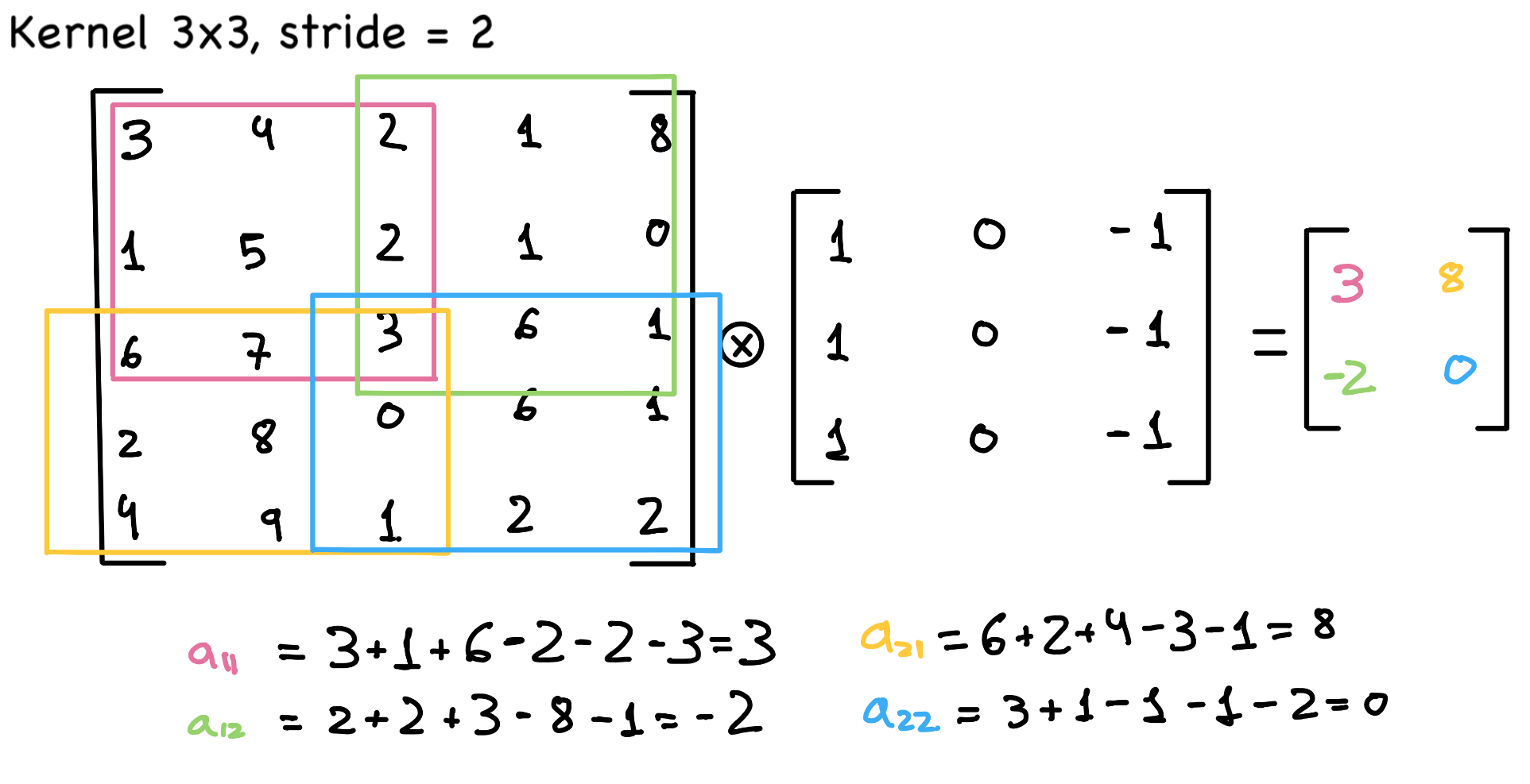
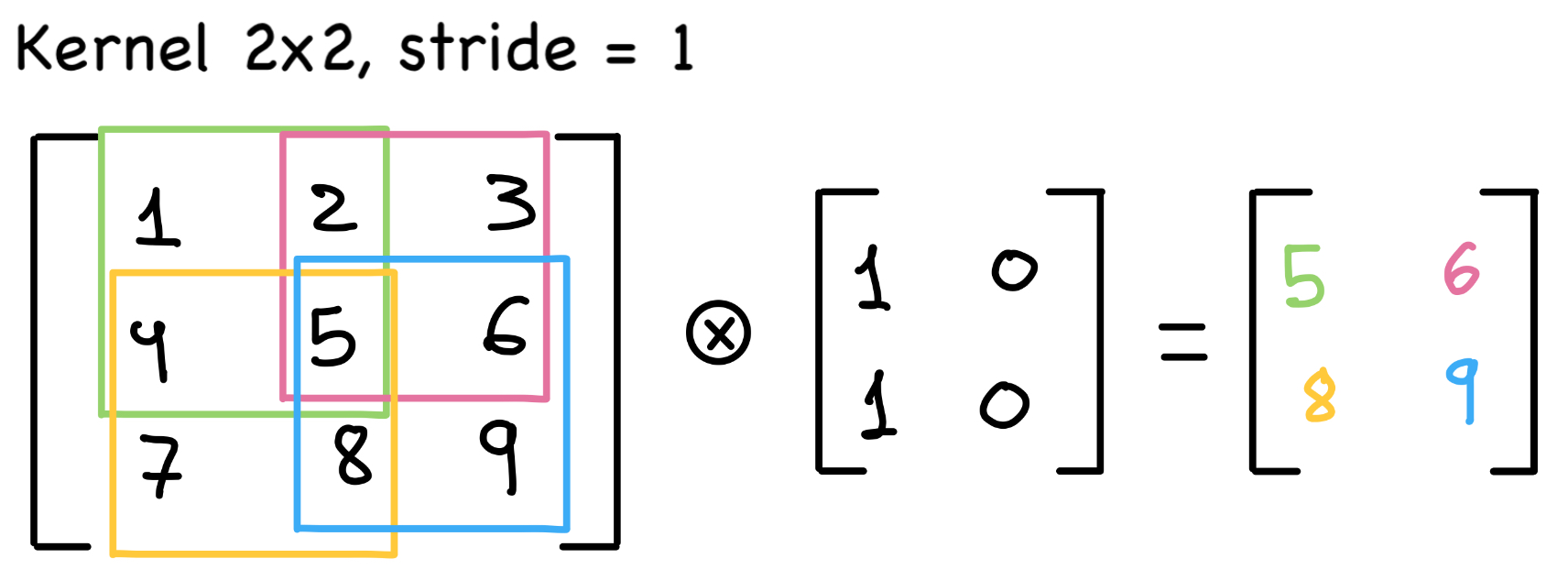
Otro parámetro importante es el stride, que determina el número de píxeles que el kernel se desplaza dentro de la imagen. Este desplazamiento se aplica tanto en filas como en columnas. En el ejemplo anterior, el stride es uno, ahora consideremos un caso donde sea igual a dos:
Capa Pooling
Estas capas reducen las dimensiones del mapa de características preservando la información más importante. Al igual que en la convolución, se desliza un kernel sobre la imagen. Aunque el método más común es el max pooling, también existe el average pooling.
Capa Flatten
Convierte los datos de entrada tridimensionales a un vector unidimensional.
Capa fully connected
Se corresponde con la capa dense del ejemplo.
Capa de salida o clasificación
Como ya mencionamos anteriormente, el número de neuronas es igual al número de posibles clases de salida. Usamos la función de activación softmax, la cual calcula la probabilidad de una entrada pertenezca a cada una de las posibles clases.
Redes neuronales recurrentes
Las redes neuronales recurrentes o RNN buscan solucionar problemas en los que existen dependencias temporales entre características; las redes neuronales convencionales no son capaces de resolverlos de forma eficiente. La aplicación principal es el procesamiento del lenguaje natural, lo cual nos sirve para hacer traducciones, interpretar discursos o generar texto. Un ejemplo real es reconocer emociones en reseñas sobre películas, analizando si los adjetivos son positivos o negativos.
Necesitamos transformar una frase de un máximo de p palabras en una entrada compatible para una red neuronal. Para lograrlo, necesitamos un diccionario que traduzca el texto a tokens según su índice. Este proceso se conoce como language processing problem.
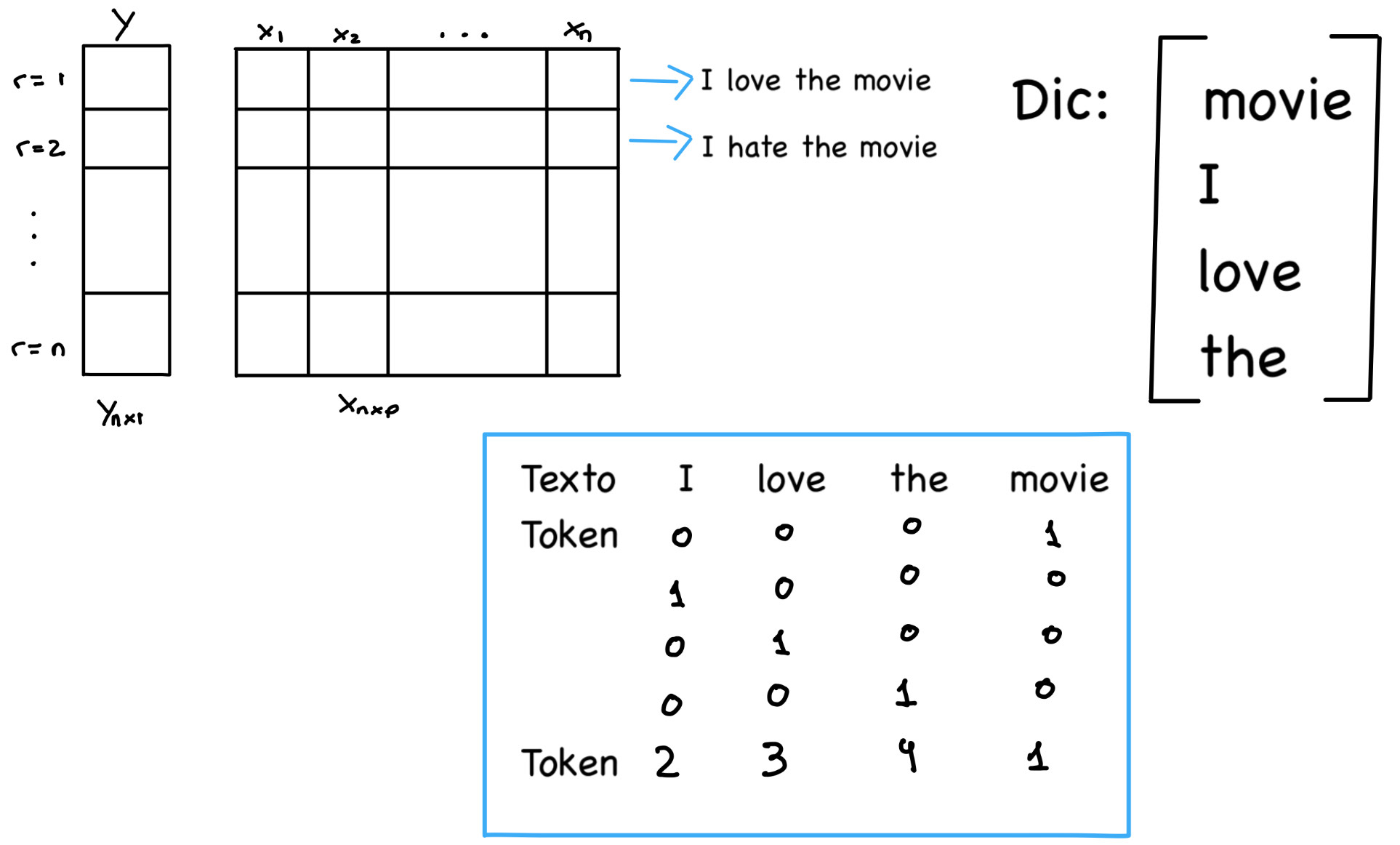
Las RNN incorporan marcas de tiempo, timestamps, para abordar la importancia del orden en la secuencia de datos. Por ejemplo, para los humanos la frase ‘I love cats’ es comprensible, mientras que ‘I cats love’ no lo es.
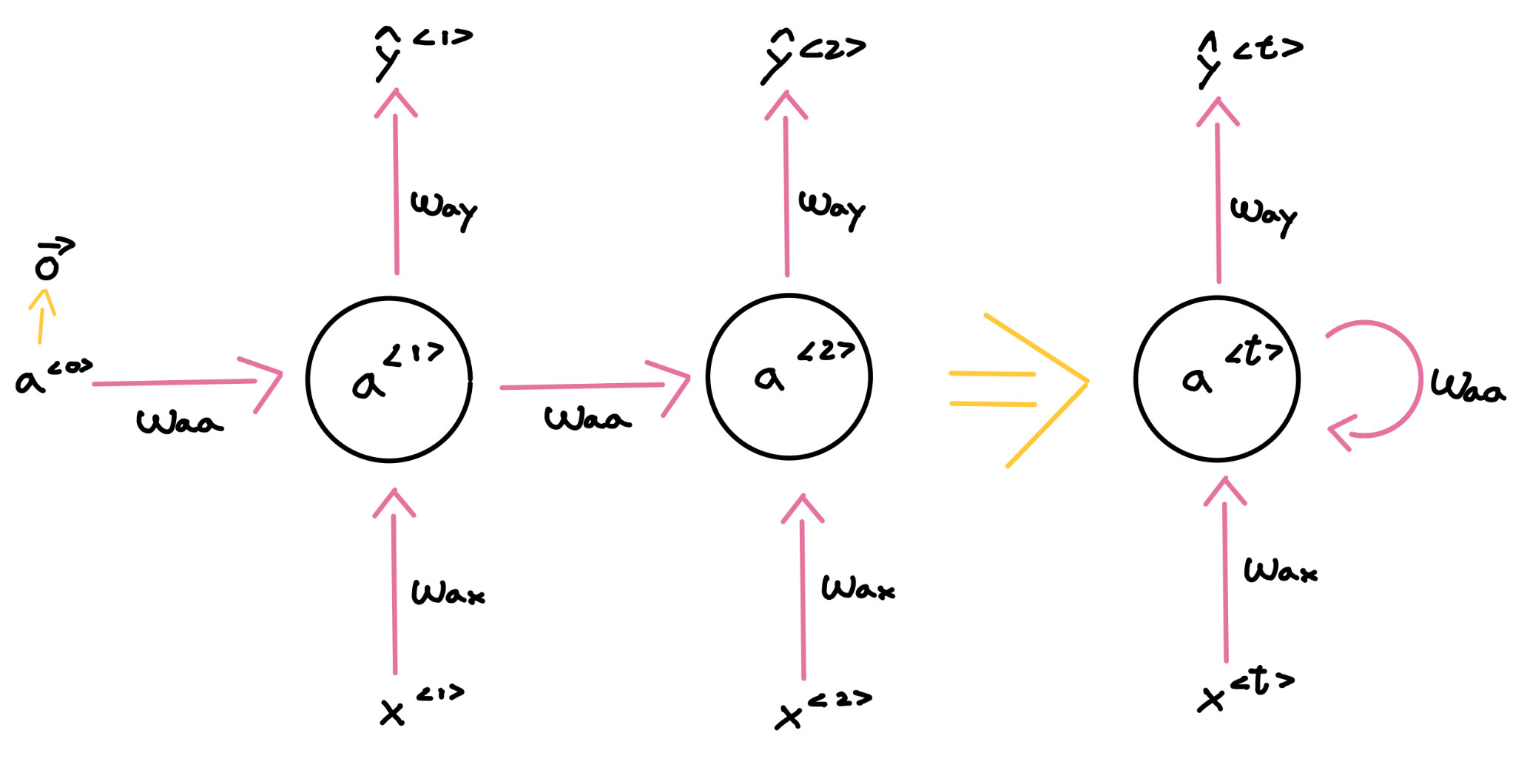
- Propagación hacia delante:
- a<0> = vec(0)
- a<t> = f(waa * a<t-1> + wax * x<t> + b)
- y<t> = f(way * a<t> + b)
- Propagación hacia atrás:
- L(y, ŷ) = ∑L<t>(y<t>, ŷ<t>)
- waa = waa - αaa * ∇aaL(y, ŷ)
- way = way - αay * ∇ayL(y, ŷ)
- wax = wax - αax * ∇axL(y, ŷ)
Existen diversas estructuras de RNN que podemos seleccionar según el tipo de dataset:
- GRU (Gated Recurrent Unit): recomendada para casos donde se requiere más memoria. Por ejemplo, en la frase “My dad, who works a lot of hours in a factory and …, was hungry.”, la red debe ser capaz de reconocer que “was” se refiere al sustantivo “dad”, mencionado bastantes palabras antes.
- Bi-Directional RNN: son útiles en casos donde el contexto es relevante. Por ejemplo: “Tim is high on drags” / “Tim is high in the sky”; en el primer caso, Tim se refiere a una persona, mientras que en el segundo, se refiere a un pájaro. Es necesario reescribir la fórmula de combinación lineal: y<t> = f(way * [af<t>, ab<t>] + b), donde af representa la propagación desde a0 hasta aT, y ab representa la propagación desde aT hasta a0.
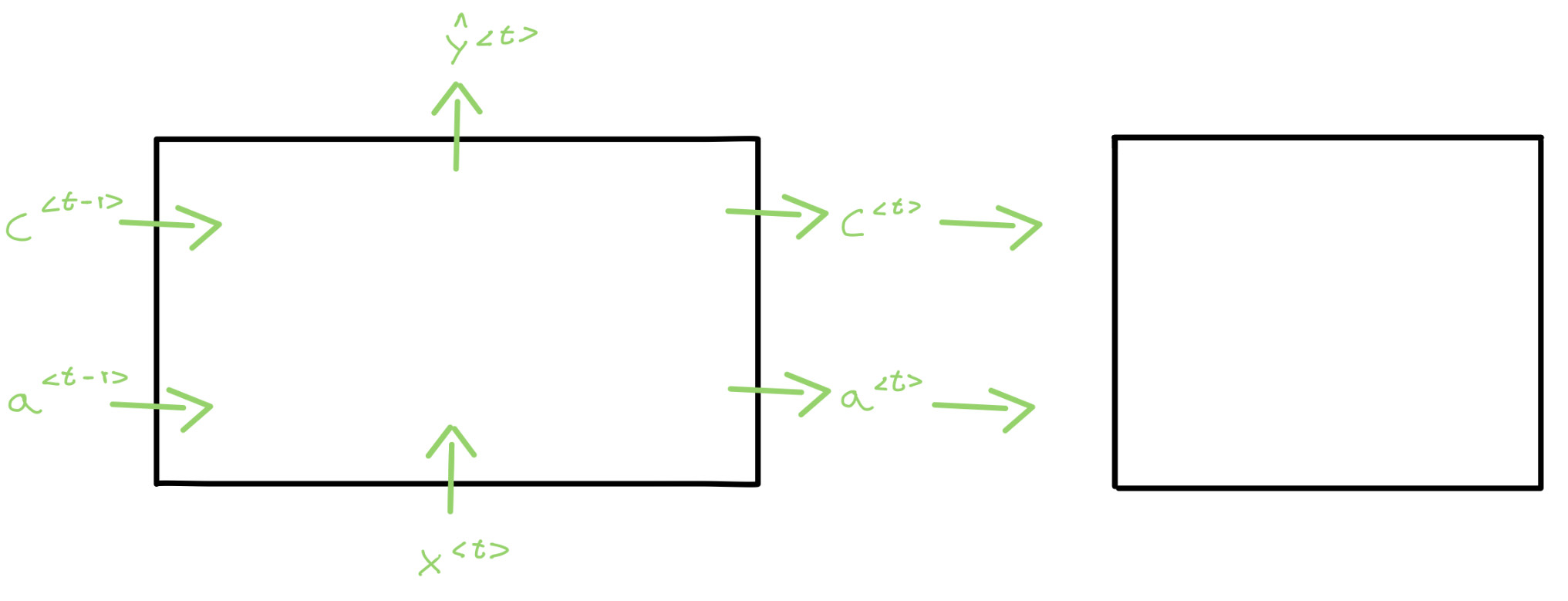
- LSTM (Long Short-Term Memory): adecuada para procesar frases muy extensas e incluso párrafos. Se añade una nueva salida c a la estructura convencional de las RNNs.
SAM
Un proyecto de SA, Segmentation Anything, está compuesto por: tarea o task, SAM (model) y data (dataset + data engine). Es capaz de segmentar cualquier objeto, pero no de categorizar lo que detecta.
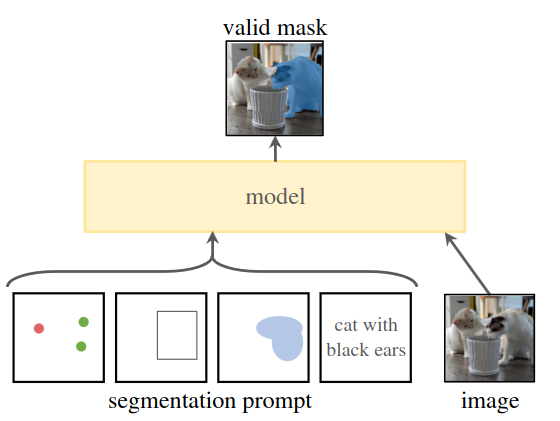
Task
Las tasks se basan en el prompt engineering, el usuario puede proporcionar especificaciones para orientar al modelo, es decir, indicándole qué segmentar en la imagen. El hecho de ser prompting permite su aplicación en una variedad de escenarios, incluyendo tareas con múltiples indicaciones. Para lograrlo, existen diversos tipos de segmentación: semántica, de instancia, detección de bordes, panorámica… El objetivo es obtener al menos una máscara de segmentación válida para cualquier prompt, incluso si la tarea es ambigua. Se considera una máscara válida aquella que al menos detecta uno o parte de los objetos solicitados.

El proceso de entrenamiento es similar a cómo se pre-entrenan los modelos de procesamiento del lenguaje natural (NLP). El modelo se entrena con una gran variedad de tareas que fomentan la generalización, con el objetivo de lograr ser zero-shot. Un modelo zero-shot es capaz de realizar una tarea sin haber sido explícitamente entrenado para ella y sin necesidad de entrenamiento adicional con nuevos datos. El fine-tuning consiste en entrenar un modelo ya pre-entrenado para tareas específicas, lo que suele requerir pocos datos nuevos (few-shot).
Model
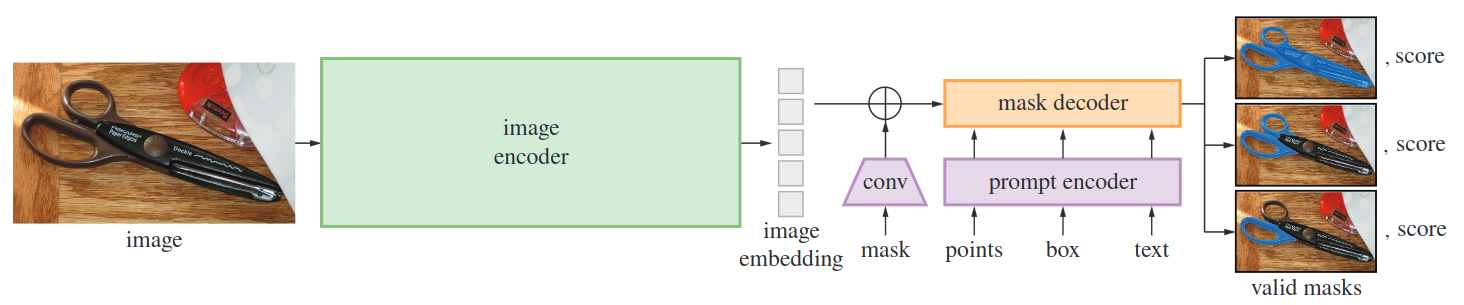
Un SAM, Segemnet Anything model, tiene tres componentes: image endocer, promt encoder y mask decoder.
-
Image encoder: convierte las imágenes de entrada en representaciones numéricas a través de un proceso que incluye rescalado, convoluciones y finalmente normalización. Este proceso reduce las dimensiones de la imagen a 64x64, generando lo que se conoce como image embedding.
-
Prompt encoder: es flexible ante diversos tipos de promt: NLP(texto) o imágenes(puntos, bounding boxes, máscaras), los cuales transforma a representaciones numéricas.
-
Mask decoder: permite la síntesis entre image embedding, promt embedding y el token de salida (mask). Para asegurar la eficiencia y precisión, el modelo propone tres posibles máscaras de salida ante un único promt. Asimismo, para garantizar rapidez y capacidad de interacción en tiempo real, el modelo debe ser capaz de decodificar en aproximadamente 50ms en una CPU.
Data
Nuestro dataset, SA-1B, consta de 11M de imágenes bajo licencia, diversas y de alta resolución (3300x4950 píxeles de media), lo que plantea desafíos en cuanto a accesibilidad y almacenamiento. Además, incluye 1.1B de máscaras de alta calidad generadas automáticamente, data engine.
Se trata de un entrenamiento supervisado, donde las máscaras ya están creadas y son específicas para detectar la salida deseada ante una entrada determinada. Por ejemplo, en el caso de las tijeras que aparecen en la imagen anterior, una máscara ground-truth contendría un valor de 1 en los píxeles donde hay tijeras y un valor de 0 donde no las hay.
RAI
La responsabilidad en la inteligencia artificial es crucial. Nuestro conjunto de datos garantiza equidad geográfica y de ingresos, todas las regiones cuentan con al menos 28 millones de máscaras, a diferencia de otros conjuntos de datos donde, por ejemplo, África tiene menos peso que continentes como Asia o Europa. Además, asegura imparcialidad en el tratamiento de personas, independientemente de su género, edad o color de piel.
Conclusión
SAM es un modelo zero-shot, pues evaluamos su rendimiento con 23 datasets y tareas nuevas que no formaron parte de su entrenamiento original, mostrando resultados prometedores en el mundo de la segmentación de imágenes. Aunque presenta algunas limitaciones, como la omisión de estructuras finas, se espera que su utilidad se demuestre al integrarlo en aplicaciones del mundo real.
Para valorar la calidad de la máscara de segmentación establecemos una puntuación del 1-10:





EfficientVit
EfficientVit es un nuevo módulo de atención lineal multi-escala para predicciones densas de alta resolución, lo cual requiere la captura de detalles finos y la extracción de información contextual significativa. Se puede ver como una extensión de la clasificación de imágenes, pasando de predicciones por imagen a predicciones por píxel. Este modelo se basa en modelos previos de predicción densos de alta resolución SOTA (State of the Art), aprovechando:
- Aprendizaje a múltiples escalas: el modelo puede capturar tanto detalles finos como características más grandes y globales en la imagen.
- Campo receptivo global: comprender el contexto y las relaciones entre diferentes partes de la imagen.
El principal desafío es que los modelos SOTA utilizan operaciones de hardware ineficientes, lo que limita su viabilidad en aplicaciones del mundo real. EfficientViT aborda este problema reemplazando estas operaciones con otras más livianas y eficientes en hardware, lo que permite una ejecución más rápida y su uso en aplicaciones en tiempo real. El cambio clave es sustituir la función softmax por ReLU, lo que reduce la complejidad computacional de cuadrática a lineal sin comprometer funcionalidad. No obstante, debido a que ReLU por sí sola tiene una capacidad limitada para extraer información local, se complementa con convoluciones en capas FFN (FeedForward Network, capa usada en CNN y RNN) a diferentes profundidades (FFN + DWConv), y aprender a múltiples escalas, se incorporan DWConv separables de kernel pequeño para solventarlo.

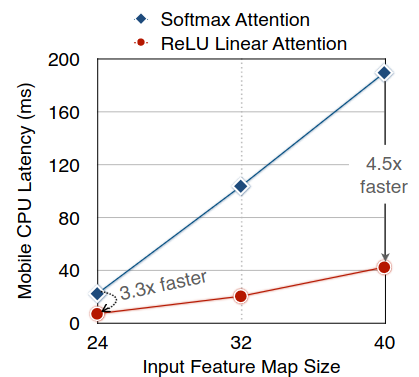
EfficientViT es evaluado en tres tareas principales: segmentación semántica, súper resolución y SA. En todas estas áreas, EfficientViT ofrece mejoras significativas en términos de latencia y eficiencia sin comprometer el rendimiento.
Aplicación
Se han implementado algunas mejoras en la interfaz gráfica, incluyendo la visualización del número de frames por segundo a los que itera nuestro programa, así como la velocidad del vehículo principal.
Además, hemos integrado la red de segmentación semántica EfficientViT en nuestro código para comprender mejor el entorno. Para ello, se han añadido nuevos atributos a la clase CameraRGB y parámetros adicionales a la función correspondiente a la cámara en la clase Vehicle_sensors. La flag seg indica si se debe aplicar la segmentación semántica a la imagen captada por la cámara. En caso afirmativo, la imagen segmentada se mostrará en la posición init_extra de la pantalla, mientras que en la posición init se mostrará la imagen sin procesar.
def add_camera_rgb(self, size:tuple[int, int]=None, init:tuple[int, int]=None, seg:bool=False, text:str=None
transform:carla.Transform=carla.Transform(), init_extra:tuple[int, int]=None)
La red neuronal recibe como entrada una imagen en RGB con dimensiones de 512x512 píxeles, por tanto, es fundamental garantizar que la imagen esté en dicho formato. Para asegurar las dimensiones, configuramos directamente la cámara en Carla a 512x512, ya que realizar un reescalado podría deformar los objetos, lo que afectaría negativamente al rendimiento de la red neuronal.