Previous weeks - New linear motion
New data type
After making a learning with simpler data and see that the performance is good we decided to complicate things to the network. For this I have established a new type of movements in space for the white point of the frames: linear movement which will combine with the URM movement in time.
In the following link you can find a description of this new type of images.
The way to obtain these new frames is the same as before, we set the position in x by means of a URM movement but this time, instead of maintaining the height of the object (position y) constant, we will modify it according to a function.
The problem that we can find in this type of samples is that we are modifying the height, a value that must be integer, by means of a function that accepts decimal values, which causes a rounding to be necessary. Depending on the sample, this rounding can make the movement not seem as natural as it would be because it is possible that the height does not change from one instant to the next.
Non Recurrent Neural Networks
First we do the training of non-recucurrent networks with the new type of data to check the scope they give us.
As in the URM case, I started training a 2D convolutional network whose structure can be seen in the following figure:
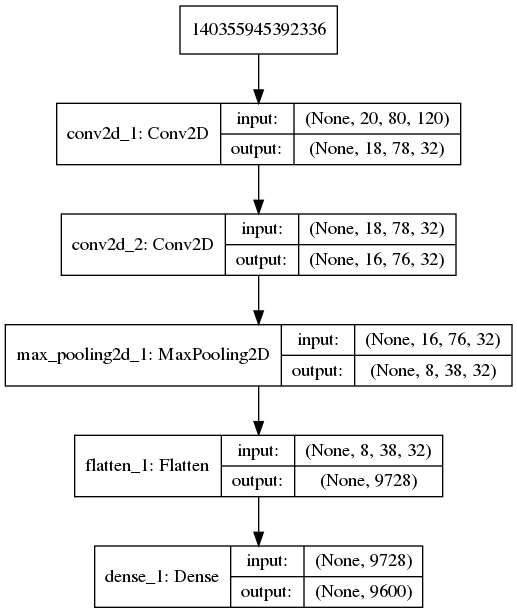
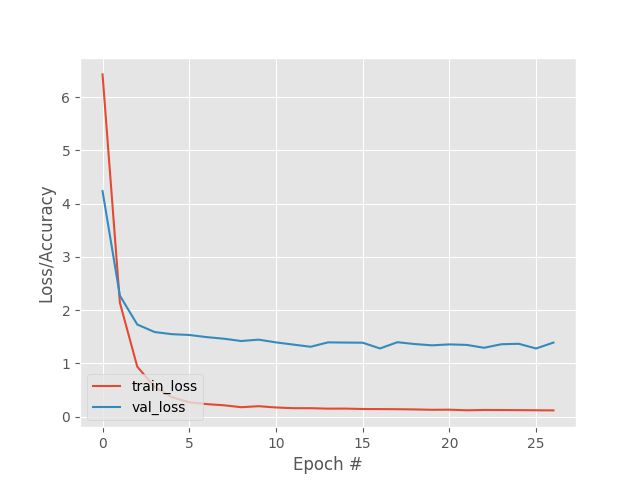
As in the two previous cases, the network manages to reduce and stabilize the loss function in only a few epochs but, because the sequences begin to get more complicated, this network is not able to capture 100% of the different movements.
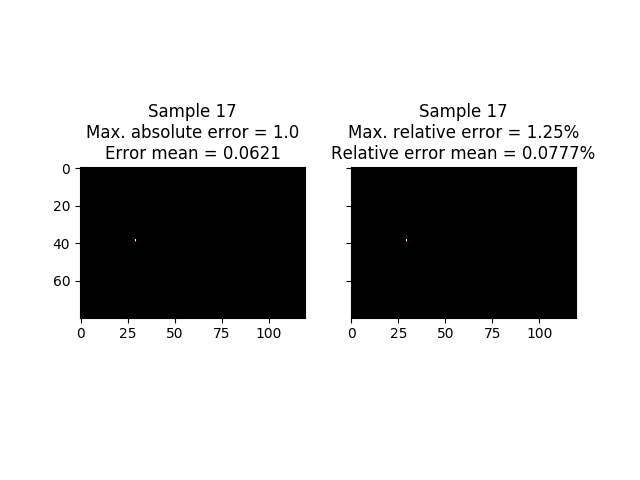
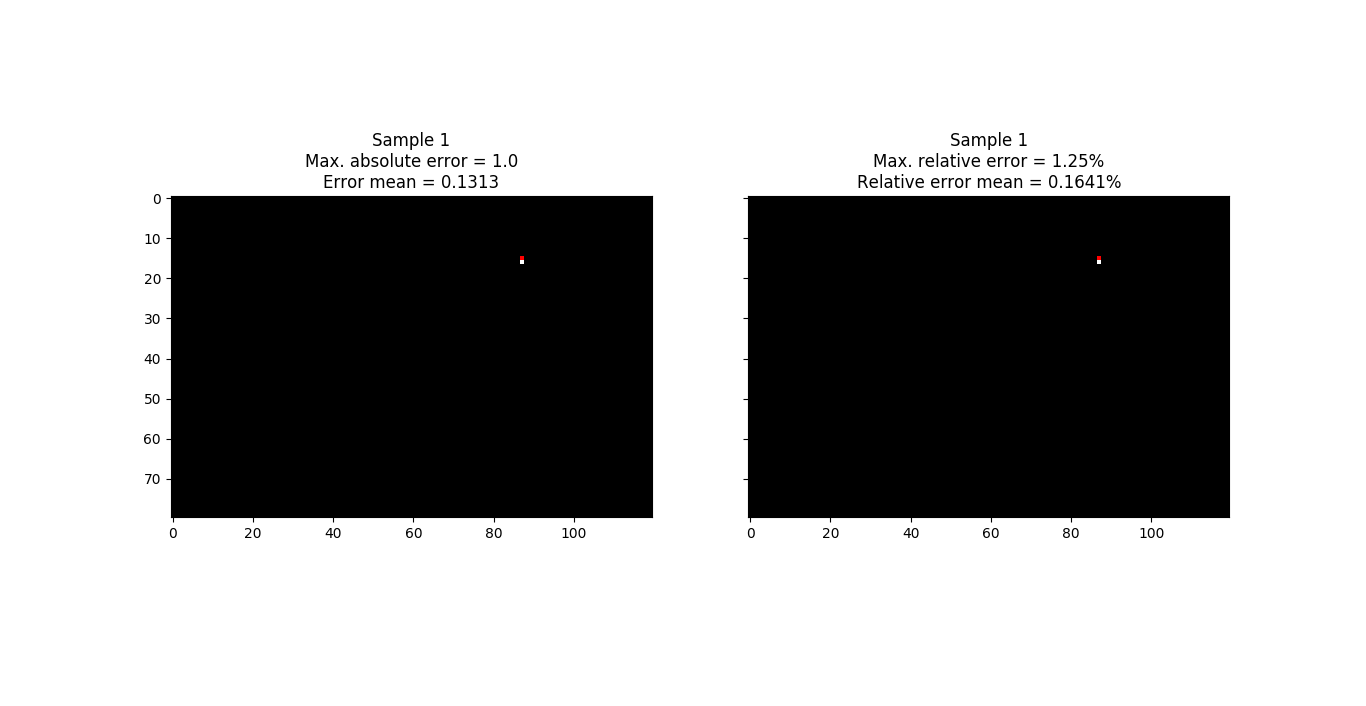
In the next image you can see target frame in the samples where the errors (absolute and relative) are maximum. As we commented previously, the error committed is not null, although the maximum error committed is quite small.
More samples
To try to improve performance we tried to increase the number of samples, according to the complexity of the data, to be able to cover more examples and get the network to improve its learning. I used 5000 samples instead of 1000 and the same structure.
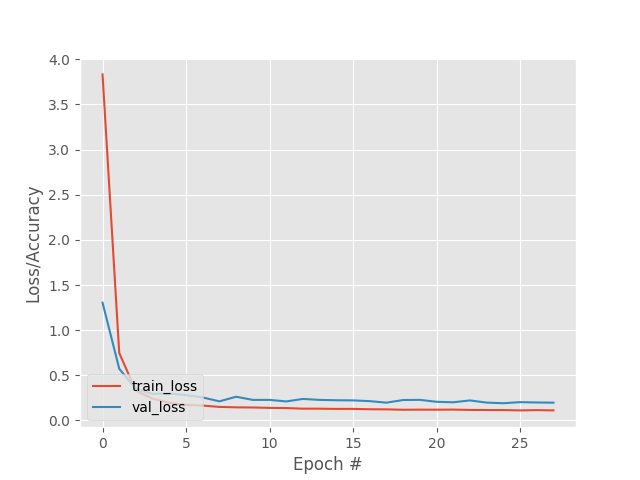
As the number of samples increases, the performance of the network improves and a greater stabilization of the same is achieved in the training.
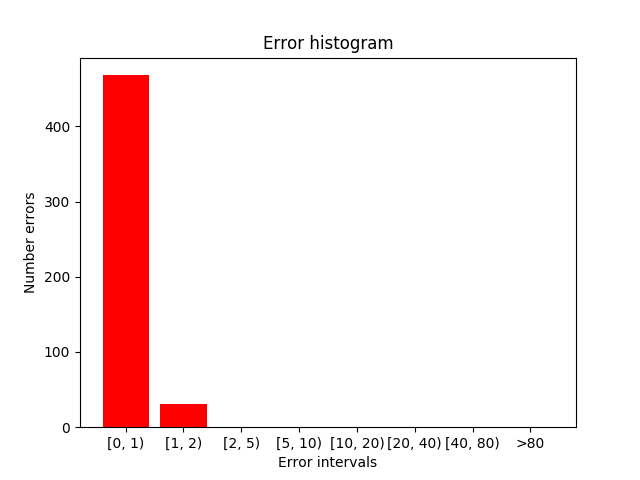
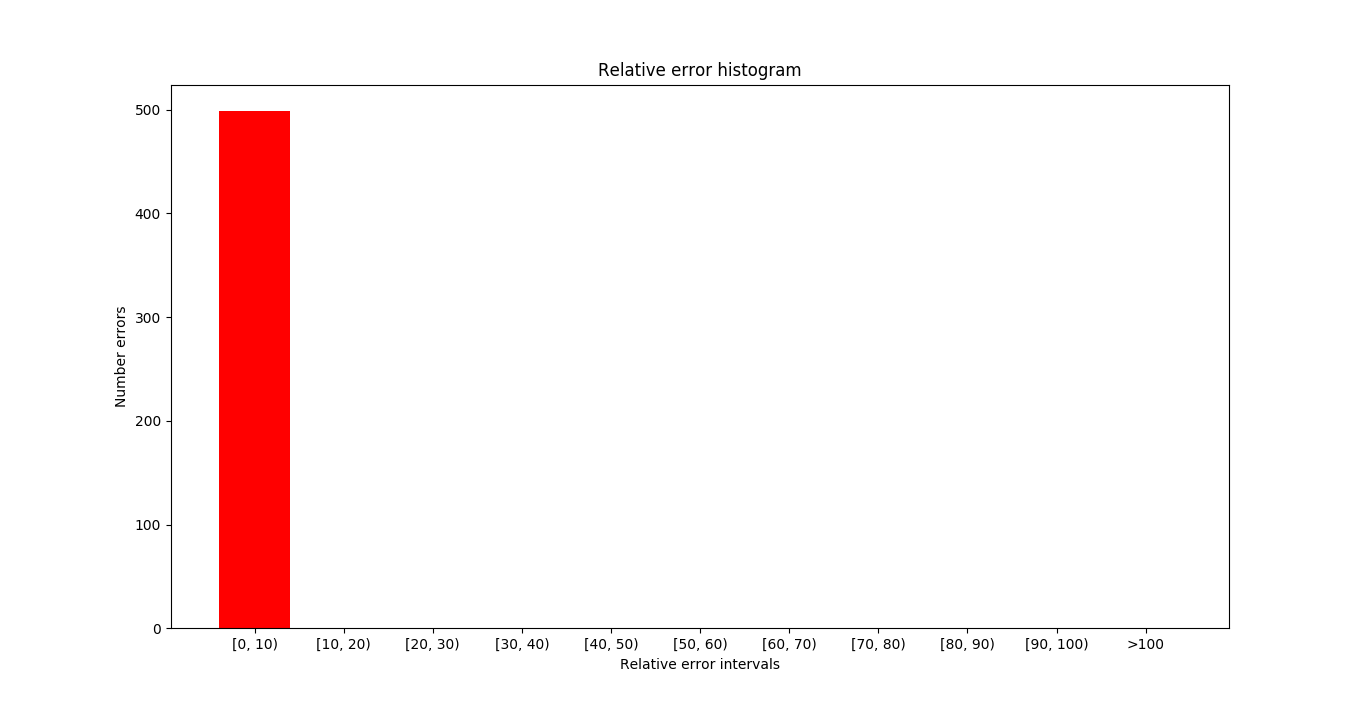
In the next image you can see target frame in the samples where the errors (absolute and relative) are maximum. As in the case with less samples, the error committed is not null, although the maximum error committed is quite small. In addition, despite the fact that the maximum error is the same, the average error has decreased with increasing number of samples.
Recurrent Neural Networks
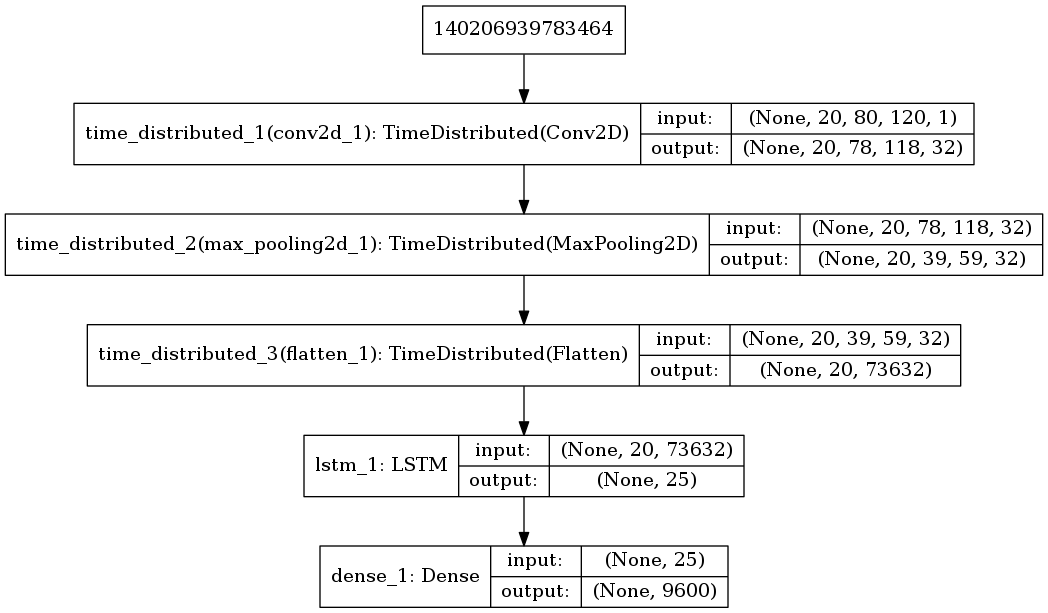
The performance obtained with the previous network can still be improved improved, so we chose to include the recurrent networks to try to improve it. I have used the following structure:
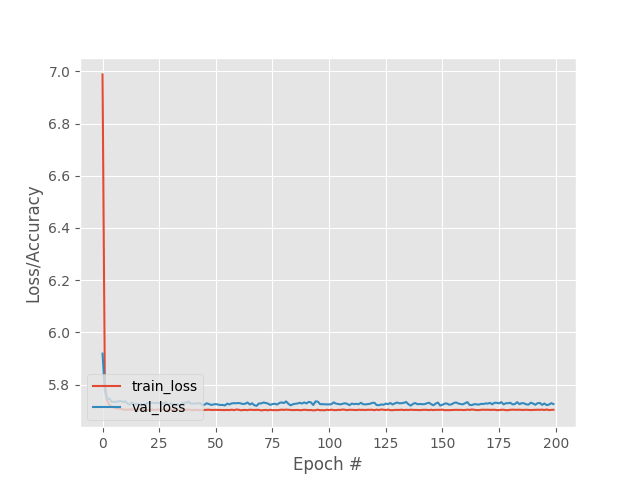
With the proposed structure the performance is not good and the error is very high.
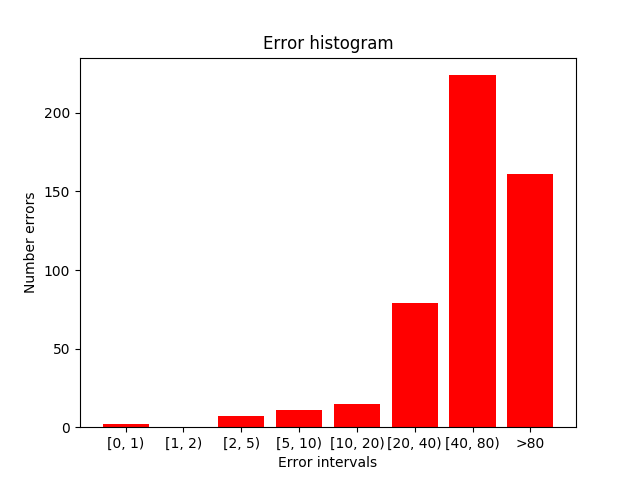
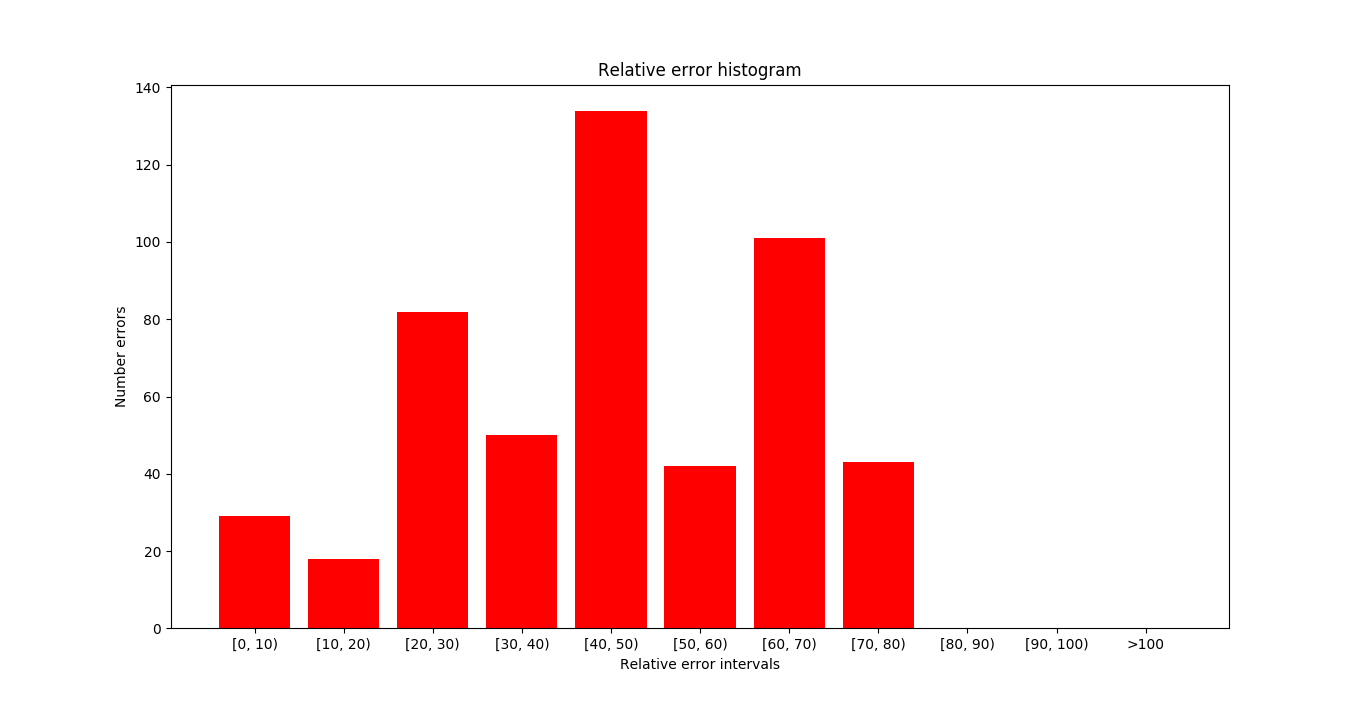
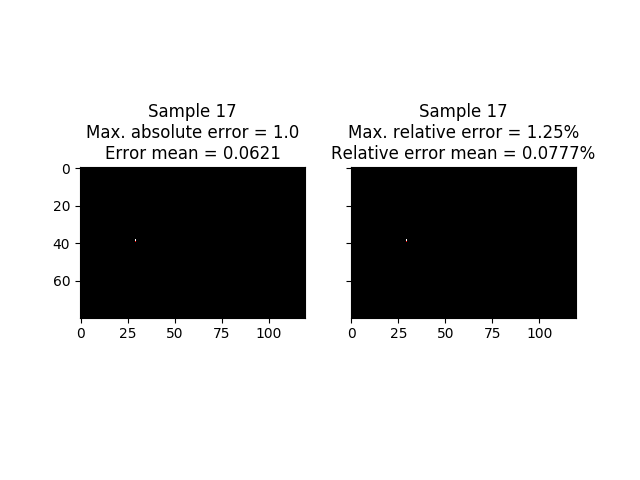
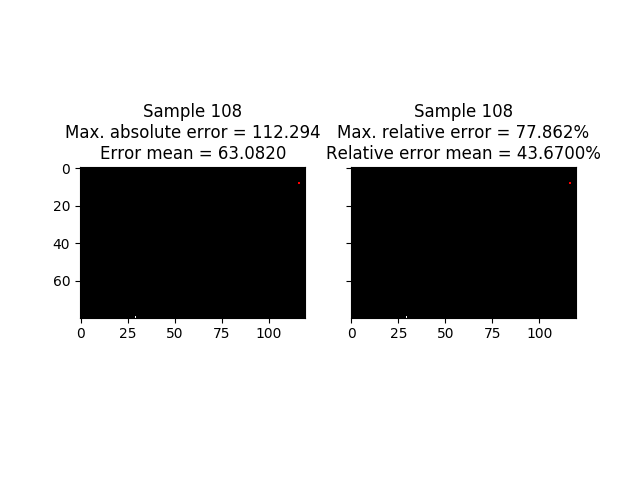
In the next image you can see target frame in the samples where the errors (absolute and relative) are maximum. As I mentioned earlier, the error made with this network is excessively high.
Recurrent Neural Networks - New structure
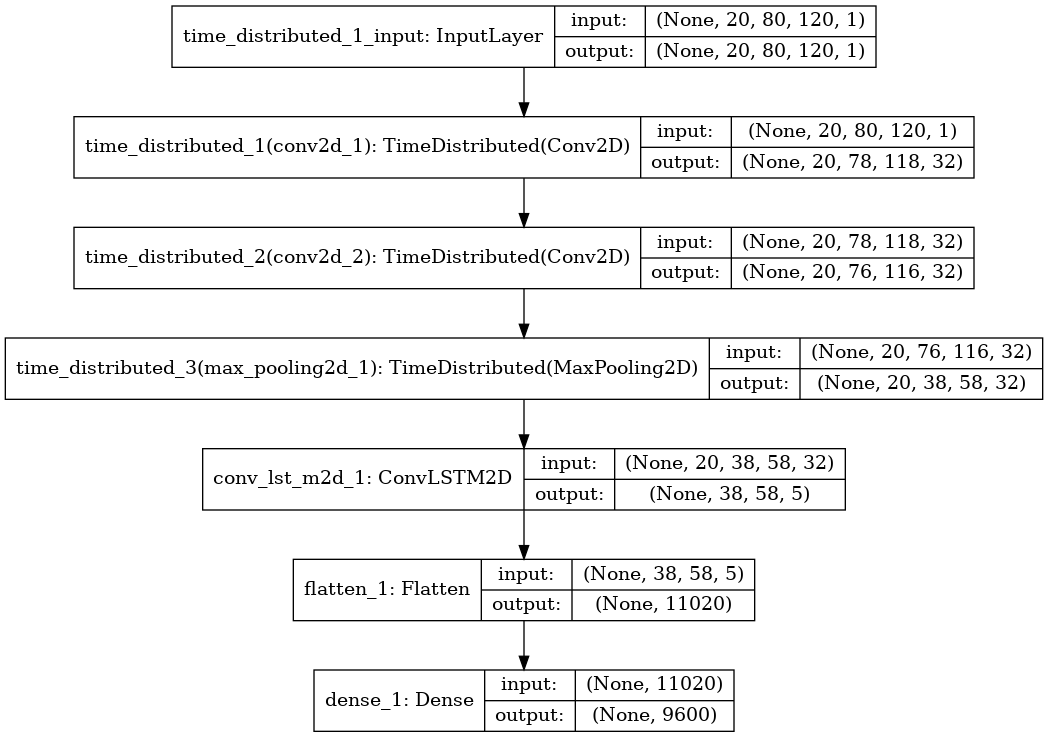
In view of the results obtained previously I have replaced the simple LSTM layer with a ConvLSTM which computes convolutional operations in both the input and the recurrent transformations. The new structure is as follows:
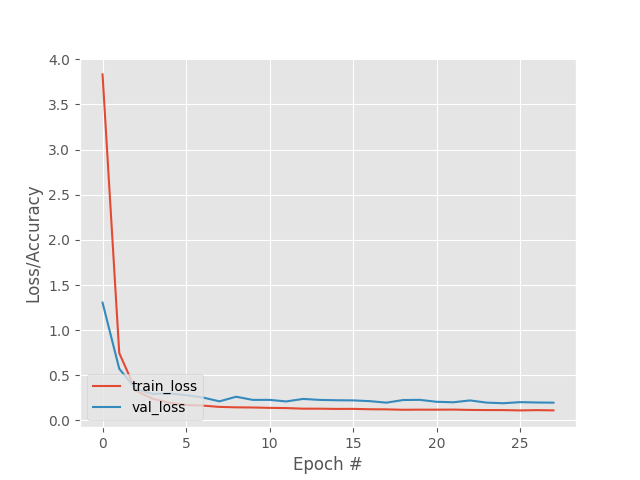
With the new structure the performance of the network is improved and the results are practically the same as in the non-recurrent case that were pretty good
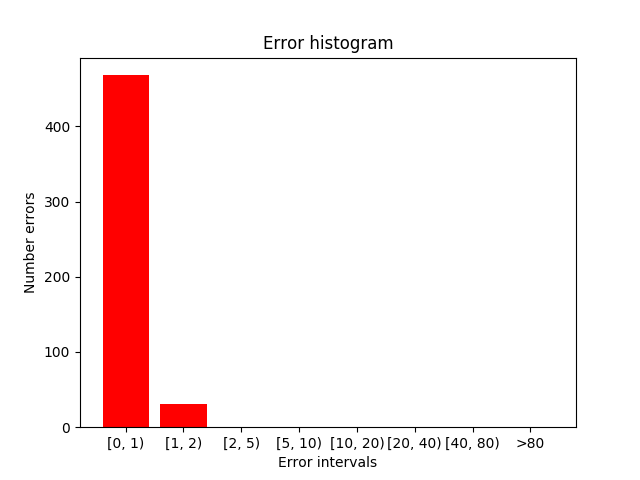
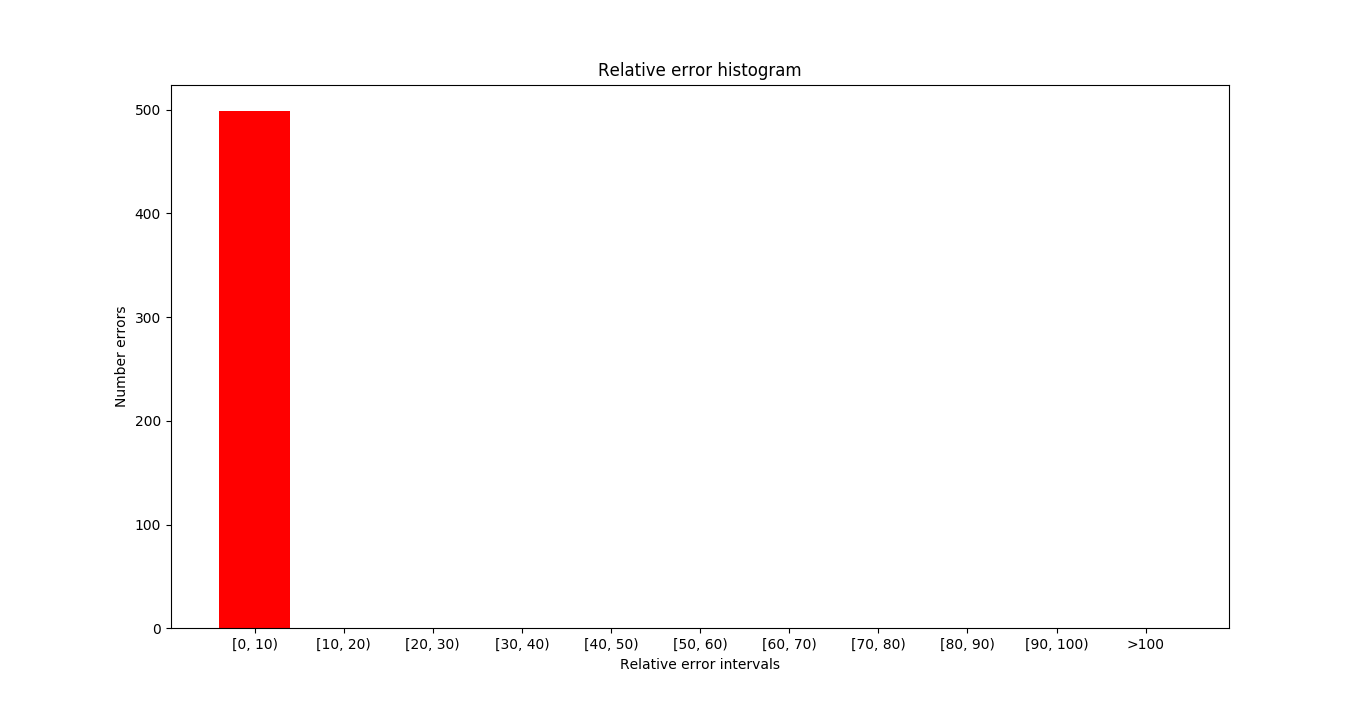
In the next image you can see target frame in the samples where the errors (absolute and relative) are maximum. The maximum error committed coincides with the non-recurrent case and in terms of the average a very similar result is obtained.