Merging SD-SLAM and Rosify Difodo III
Lets continue with the integration or DIDODO with SD-SLAM.
Integration
First of all I removed all the ros related code and unnecesary code from rosify_difodo.
Use the depth image from SD-SLAM
SD-SLAM do get a depth image from a ros topic when using the rosified version of SD-SLAM, but can be from other sources like a file. Difodo on his rosified version was able to subscribe to a topic but that would be doubling the work since SD-SLAM has already done it. Now instead, DIFODO will receive the depth image from SD-SLAM as a opencv mat of 32bit, a float matrix. So the first thing that I did was to parse the opencv mat to mrpt mat in order to use DIFODO from mrpt.
Choose where DIFODO enters in play
Another key point is where DIFODO is needed. We will start adding it in the Tracking module from SD-SLAM, in the Track() method. Here we can know when SD-SLAM fails due to not having enough matching points from the ORB extraction and matching. When this happens and relocalization also fails is the moment where SD-SLAM has failed to give a pose estimation and DIFODO will come in scene. DIFODO will keep updating the pose of the last frame with his odometry until SD-SLAM can find a significant number of points and reinitialized again.
Adding the pose from DIFODO to SD-SLAM
Another key point is how to add the estimated pose from the odometry of DIFODO into SD-SLAM. Since each algorithm has his own coordinate system and there is not a world coordinate that connects them.
NOTE: In this step a lot of transformations between coordinates systems are made. For a quick reminder on this subject:
- This is a good video -> https://es.coursera.org/lecture/robotics-perception/rotations-and-translations-eTSMz
- Also chapter 3 of the book Fundamentos de Robotica 2ª Edición by Antonio Barrientos (among others) is very useful.
- Some slides: http://www.ccs.neu.edu/home/rplatt/cs5335_fall2017/slides/homogeneous_transforms.pdf
- How to get the displacement beetween two poses referenced to world: https://stackoverflow.com/questions/55150211/how-to-calculate-relative-pose-between-two-objects-and-put-them-in-a-transformat
- Chapter 3 may help: http://planning.cs.uiuc.edu/
Get the increment/displacement in pose from DIFODO
In this case since what we get from DIFODO is only odometry, we can directly add the increments in the position estimated by DIFODO into SD-SLAM. DIFODO provides a pose estimation after each iteration, so to get the displacement in rotation and traslation we must save the last known pose and substract the new estimation to that one, to get the displacement between the two poses.
To do this we must subtract the last estimated pose to the previous pose:
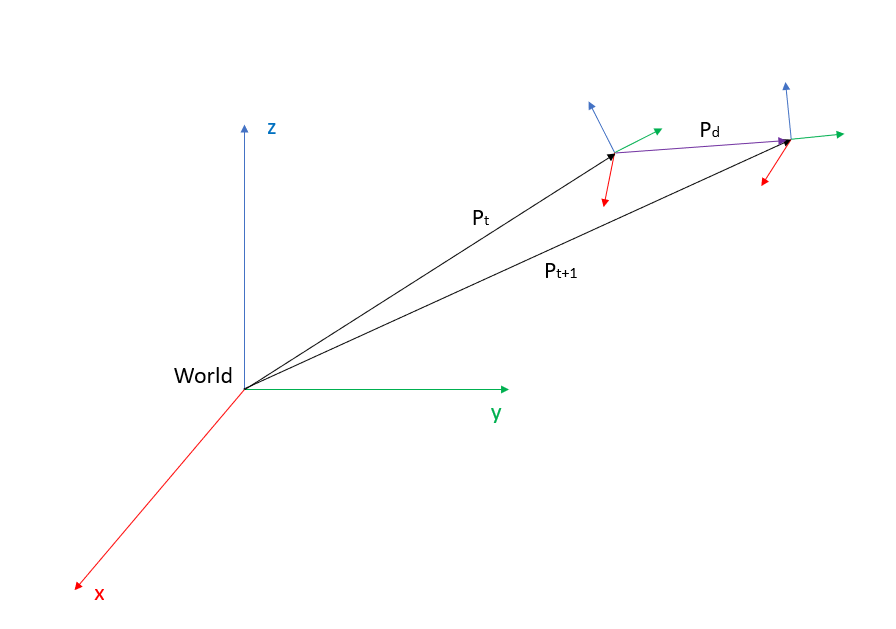
Being Pt the Pose in time “t” and Pt+1 the Pose in the next interval of time. This makes Pd the displacement or increment between the two poses. Pd is the increment that has to be added to Pt in order to get Pt+1. In this case we got Pt and Pt+1 so in order to get Pd we have to substract Pt to Pt+1. Another point of view is that we are going to get the pose of Pt+1 from the coordinate system Pt instead of the world.
These Poses should be in the homogeneous form as 4x4 matrix. The inverse of a Pose is:
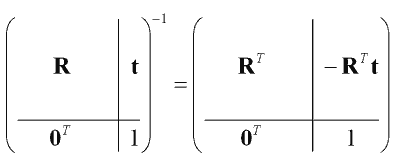
Doing this steps will give us the increment or displacement that has to be done to get Pt+1 in DIFODO. Now this increment will have to be added to the last known pose of SD-SLAM when this algorithm fails to localize.
Finding the correlation between SD-SLAM and DIFODO coordinates reference systems
After we got the displacement between poses, before adding this pose to the last pose of SD-SLAM, I have to make sure that the axis for both systems are in the same position regarding the camera. This means that I have to find the transformation between both coordinates reference system related to the camera. For example, I have to be sure that an increment of X axis of +5cm in DIFODO in also an increment of the X axis of +5cm for SD-SLAM or at least find the transformation that I have between one and the other to be able to translate this increment to SD-SLAM camera coordinate system. The following images shows how are the coordinate reference system of both algorithms related to the camera:
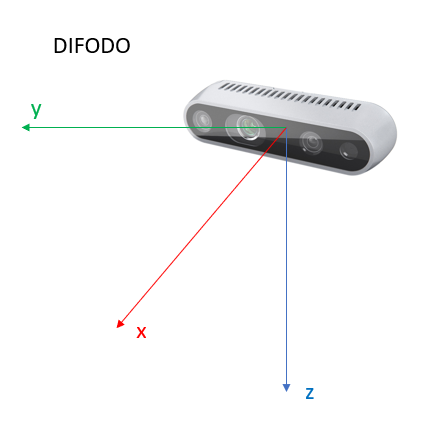
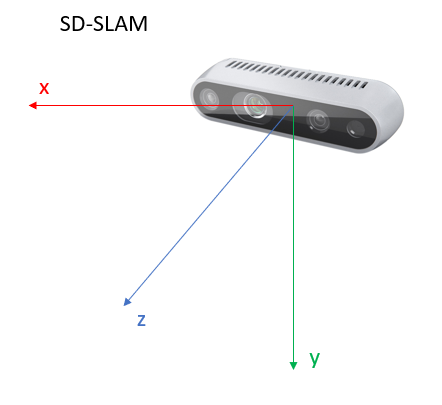
In order to see the axis of SD-SLAM I could directly see a relation between DIFODO and SD-SLAM when both uses world coordinates. This is because both algorithms declare the world coordinates when the first frame comes into scene. The axis from both systems seem to be aligned in the same directions but the axis are changed from one to the other. The relation is as follows:
- Xdif = Zsd-slam
- Ydif = Xsd-slam
- Zdif = Ysd-slam
Before adding the measured displacement from DIFODO to SD-SLAM first I have to change the displacement axis to match the convection used in SD-SLAM. This is just changing the order in the code.
Adding the displacement to SD-SLAM
The next step is to add the displacement estimated by DIFODO when SD-SLAM gets lots or cannot estimated a new pose for any reason. Adding an increment/displacement to SD-SLAM last known pose is straightforward. Since the displacement is referenced to the last known camera pose (DIFODO) and we have seen in the previous section that by changing the axis position we can have this displacement referenced to any SD-SLAM pose.
The process to add this displacement and get the new pose is as follows:
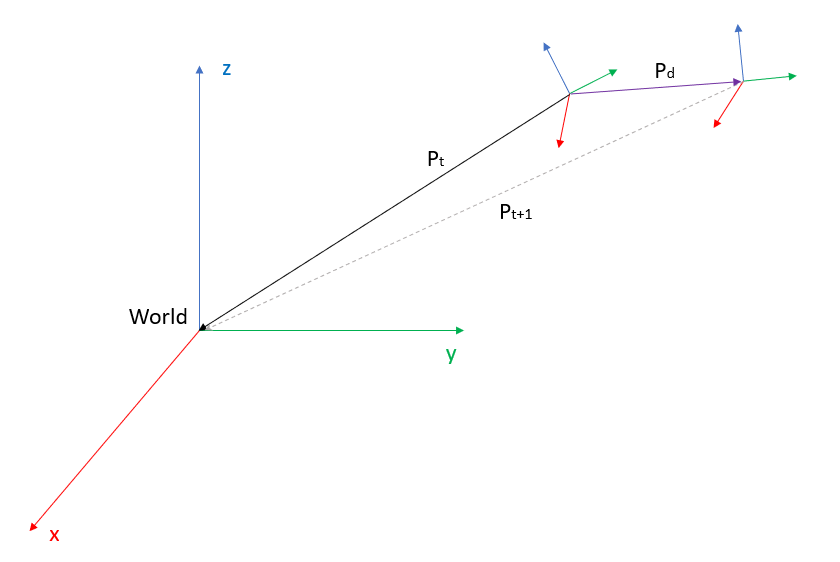
Being:
- Pt: “Last known pose”. The pose of the world seen from the last known pose
- Pt+1: The new pose that we want to get.
- Pd: Increment between two poses
Notice how Pt and Pt+1 are not in world coordinates, instead, what we have is the pose of the world seen from the two poses. This is because on SD-SLAM usually what we have are points seen by the camera and is better to have those points referenced to the camera not the world. When the points are added to the map this points can be referenced to a common reference system like the world. In any case in we wanted to have the poses Pt and Pt+1 in world coordinates all we have to do is to do the inverse of the pose, but this is not required here.
To get Pt+1 we have to do the inverse of Pd and bring the world seen from Pt to the reference system of Pt+1, this is how Pt+1 sees the world. In matricial form this can be seen as:
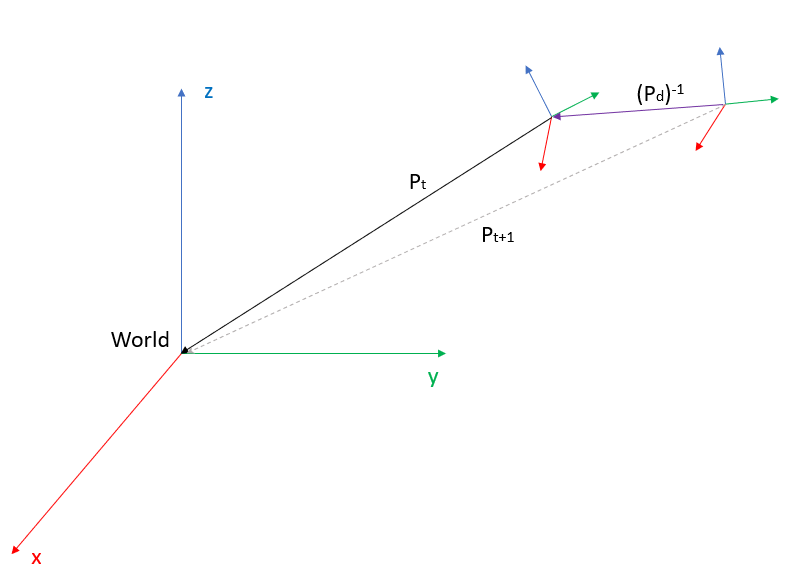
With this the new pose of SD-SLAM using the estimated displacement from DIFODO has been achieved, now SD-SLAM can see even when there is no light or texture at all!
Creating a new test dataset
Since the datasets that we have previously work doesnt have the necessary conditions I have to create my own dataset to test the new algorithm when is finish and also while developing it.
In order to create a rosbag from the realsense camera we have two options:
- Use realsense-viewer app with a GUI and record.
- Use the realsense2_camera package to publish as topics the realsense camera information and then use rosbag record to record this topics as rosbag files.
The first option is easier but it has some downsides. The recorder topics have different names compare to the ones published when using the realsense ros wrapper. Also when directly recording using realsense-viewer the encoding from the camera seems to be “mono16”. Rosify difodo was created in order to work with the following encodings “16UC1” and “32FC1” because that are the ones that are used when using the realsense wrapper. In order to avoid any other problems that may differ between the realsense-viewer app and the realsense2_camera ros package Ill record the rosbag files using the realsense ros wrapper, since this is the one Ive been using to work with the realsense camera during the entire project.
To record the following sequences this was the procedure:
# First start publishing the camera with the realsense ros wrapper
roslaunch realsense2_camera rs_camera.launch aligned_depth:=true
# or
roslaunch realsense2_camera rs_rgbd.launch
# (In my case I used the first command since the rs_rgbd seems to perform worst and the aligned depth frames were not consistent at 30 FPS while using the other method I could achieve steady 30 FPS)
With this command the camera color and depth image along other different parameters and information will be publish in several topics. The topics we are interested in are:
- RGB topic:
- camera/color/image_raw
- camera/color/image_rect_color
- DEPTH topic:
- camera/aligned_depth_to_color/image_raw
Since the registration or alignment is based on the color image, the color image remains the same (thats the reason that all topics form the color image are the same) but the depth image has one topic for the original depth image and another one for the aligned depth image, where the FOV of the depth image is the same as the color image.
We want to use only the registered channels for SD-SLAM because it uses both (rbd and depth) on its original form when using it as rgbd. The depth is used to retrieve the depth or the pixels to create the map and avoid having to triangulate these points to get the depth.
So once the camera is running and the topics are being publish to record them as a rosbag:
rosbag record -a
This will record all topics. Is true that not all topics are needed but in case is needed in the future I prefer to record all the topics so in can be used on different ways in the future.
Since I got some problems to record all and the rosbag can be huge in size in so many time, finally I recorder only the two topics required, the depth topic (aligned to the rgb) and the rgb topic. To record only those two:
rosbag record -O myfileOutputName /camera/aligned_depth_to_color/image_raw /camera/color/image_raw
The dateset sequences
The dataset has been created with the realsense2_camera Ive created all the sequences required to test the new algorithm, the caracteristics of each one are described now:
- light_no_light_ends.bag: The sequence starts with light, enters in a room with no light and the sequence ends there.
- light_no_light_ends_with_light.bag: The sequence starts with light, enters in a room with no light, exits the room and goes back to the initial corridor with light.
- light_no_texture_end.bag: The sequence starts with light, enters in a room pointing at a white wall without texture and the sequence ends there.
- light_no_texture_ends_with_texture.bag: The sequence starts with light, enters in a room pointing at a white wall without texture then regain texture in the room.
- light_shutdown.bag: The sequence starts with light in a room, the light is switch off and the camera gets closer to the bed.
- light_shutdown_ends_with_light_relocalization.bag The sequence starts with light in a room, the light is switch off , then is switch on again loooking at the same scene (relocalization)
- light_shutdown_ends_with_light_new_place.bag The sequence starts with light in a room, the light is switch off , then is switch on again loooking at a different scene (no relocalization).
- no_light_begin_ends_with_light.bag: Starts on a room without light and then goes over a corridor with light.
Next Steps
Test the algorithm in the newly created datasets. The use of DIFODO inside SD-SLAM has to be tested since until now it has been changed manually on a certain chosen frame. Now instead it should be done only when SD-SLAM tracking gets lots. With the new dataset all the test can be done and the integration can advanced.