MountainCar openAI Gym exercise solved using q learning
Reqs
To execute this program you just need to install the following libraries:
- Python3
- PyQt5
- numpy
- Pandas
- matplotlib
Manual
The main goal of this exercise is similar to the last proposed. To dig into the reinforcement learning basics. In this case, the exercise is not that simple, since some times you will need to get farther from your goal to be able to reach it. It makes thigs harder in terms of defining a reward function and the hyperparameters configuration to enable the agent to learn the either the optimal or a feasible sequence of steps to accomplish the objective.
In this case we are trying to solve the “mountainCar” problem proposed by openAIGym in which the objective is to teach a car how to reach the peak of a mountain just applying one of the following three actions:
- apply a little force to right
- apply a little force to left
- do nothing
For more details regarding this exercise, refer to the openAIGym mountainCar website
Since it is still not possible to implement a deep reinforcement learning algorithm due to hardware constraints, the problem has been solved using a q learning algorithm.
GRAPHS:
To learn the behaviour of our agent based on what we are implementing it is important to have any kind of metric to measure the performance of each test. To accomplish that we have three graphs in the upper part of a window that will be prompted each time the agent complete a configured number of maximum attempts to reach the goal.
-
The first graph indicates how good the agent is learning a path so the total reward is for each run increases. This graph shows the total reward per run.
-
The second graph indicates how many steps were needed in each run to either reach the goal or to fail. In our case, since we configured the environment to be reset when a total of 500 steps were executed, we wiil have an indication of failure when the run displayed reach a number of 500 steps. Otherwise it will indicate that the goal was reached before completing the 500 steps and that means a successfull simulation.
-
The third graph indicates how close to the goal was the car in each run/simulation. It gives us an indication of how correlated is the reward and the performance of the simulations.
Additionally, ten matrices will be provided to indicate the qtables evolution, which will give us an idea of the learning evolution of our agent. Note that the matrix represents the following:
-
In the horizontal axis, the car position is represented.
-
In the vertical axis, the car speed is represented
-
blue color means that the optimal action learned by the moment for that position-speed is “do nothing”
-
green color means that the optimal action learned by the moment for that position-speed is “step left”
-
yellow color means that the optimal action learned by the moment for that position-speed is “step right”
CONFIGURATION
Insted of not being really configurable, the code is easily modifiable to try different configurations. In order to do so, comments and constants with descriptive name are added at the beginning of the program.
However, to perform a try the suggestions are to modify the following:
-
Hyperparameters
-
Maximum number of steps per run
-
Maximum number of runs before showing the results
-
Reward function
In case of doubt and for seeking inspiration, you can check the “results document” uploaded in the github repository
Video
Code
mountainCar openAIGym exercise solved using qlearning
Results
As referenced in CONFIGURATION section, you can check the results of each qlearning configuration implemented here
As you will see, plenty of different hyperparameters configurations and reward functions were tried based on the interpretation of the ongoing results. Finally, the best approximation was surprisingly found based on an error designing the reward function which consist of a gap between two levels of the reward function which make the agent learn faster that the optimal reward will be at the top of the mountain.
Additionally, we discover that the agent needs time and exploration to find a sequence of steps since the possibilities are really high and most of them drive to a failure simulation.
To sum up, after trying practically everything, the following configuration has achieved the best results:
MAX_RUNS=3000
MAXIMUM_STEPS=500
GAMMA = 0.95
LEARNING_RATE = 0.2
EXPLORATION_MAX = 1.0
EXPLORATION_MIN = 0.05
EXPLORATION_DECAY = 0.9995
def get_reward(state, step):
if state[0] >= 0.5:
print("Car has reached the goal")
return 500
elif state[0]<-0.7:
return ((state[0]+0.7))
elif state[0]>-0.7 and state[0]<-0.2:
return 9*(state[0]+0.3)
elif state[0]>=-0.2:
return (9*(state[0]+0.3))**2
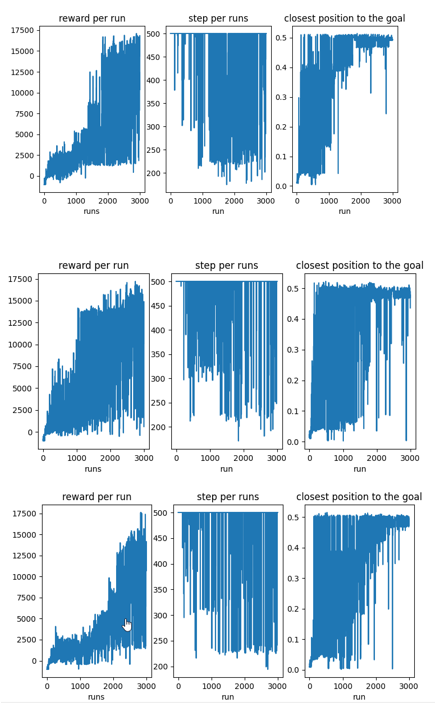
And so, our conclussions are the following:
- It is important to propperly learn the actions that are going to be executed more often, so you should control your exploration simulations to make sure it is happening
- In this case it is important to give high importance to the future rewards so it is propagated to previous less rewarded states importants also to reach the goal
- It is important to give time to the agent to learn the optimal path (in this case) increasing the maximum number of steps per simulation
- In cases where the randomly selection of actions is unlikely to guide your agent to the goal, it is important to give it clues so it approach more and more the goal. In this case we just got reasonably good results building a reward functions with several levels so the agent learn that:
- Valley positions is something to avoid (no reward)
- Climbing to the left is not bad but it is not that good as climbing to the right (closer to the goal)
- Goal is the best state possible
- And last (and probably least important) it is a good idea to keep a minimum exploration rate so you encourage your agent to not to give things as given even when it is in a later stage. In this way, in spite of doing it at a much lower speed, the agent will always keep learning.
Feel free to share a better implementation or discrepancies with our conclussions!! We are humbly open to learn more from more experts!!