Trainings and implementation experiments to make cartpole solution more solid
INTRODUCTION
After implementing the dqn refined solution in which we can try several complexities of cartpole problem, we will try to make the agent as stable as possible. Our starting point for the following experiments is the initial solution presented in previous post
EXPERIMENTS
RANDOM PERTURBATIONS
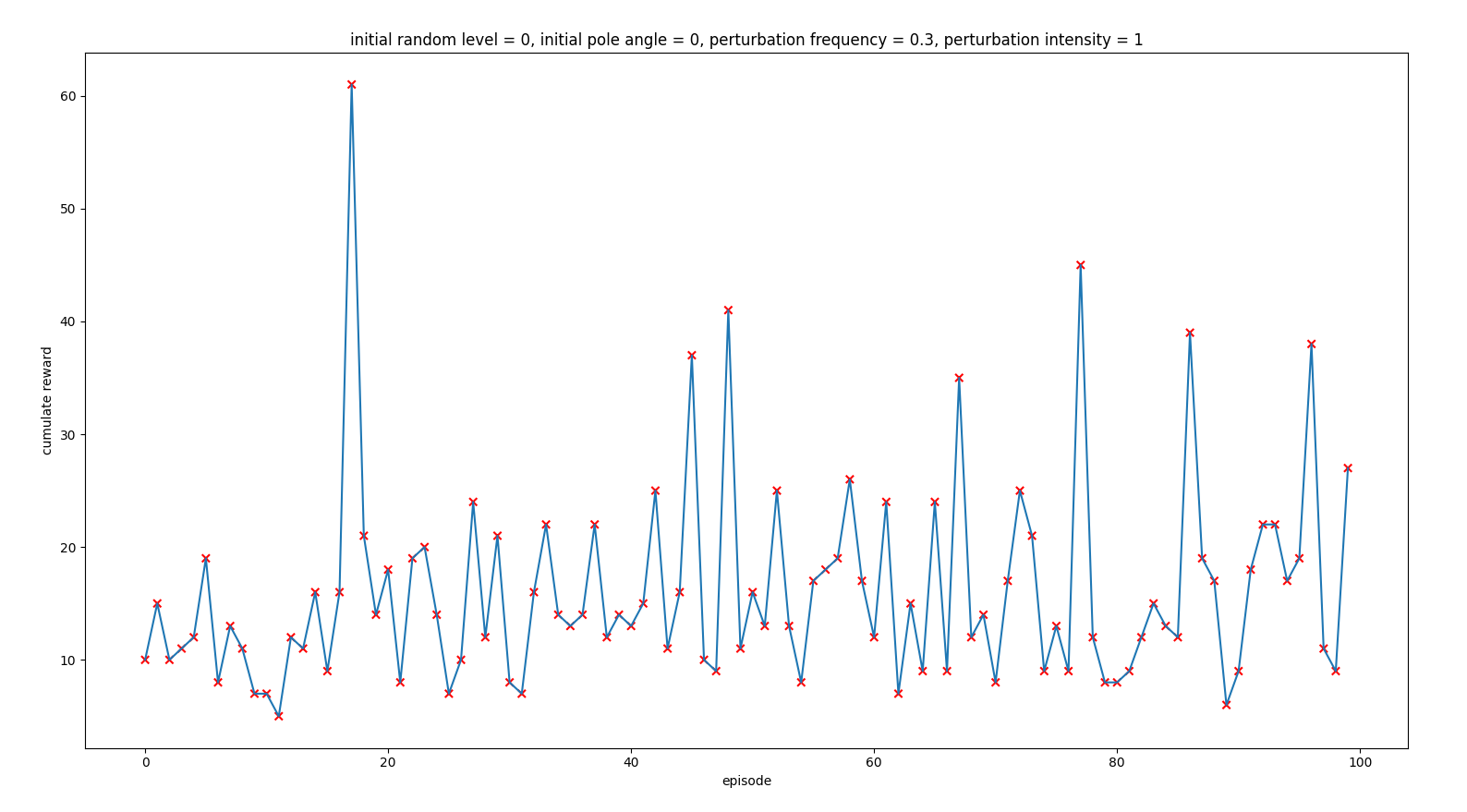
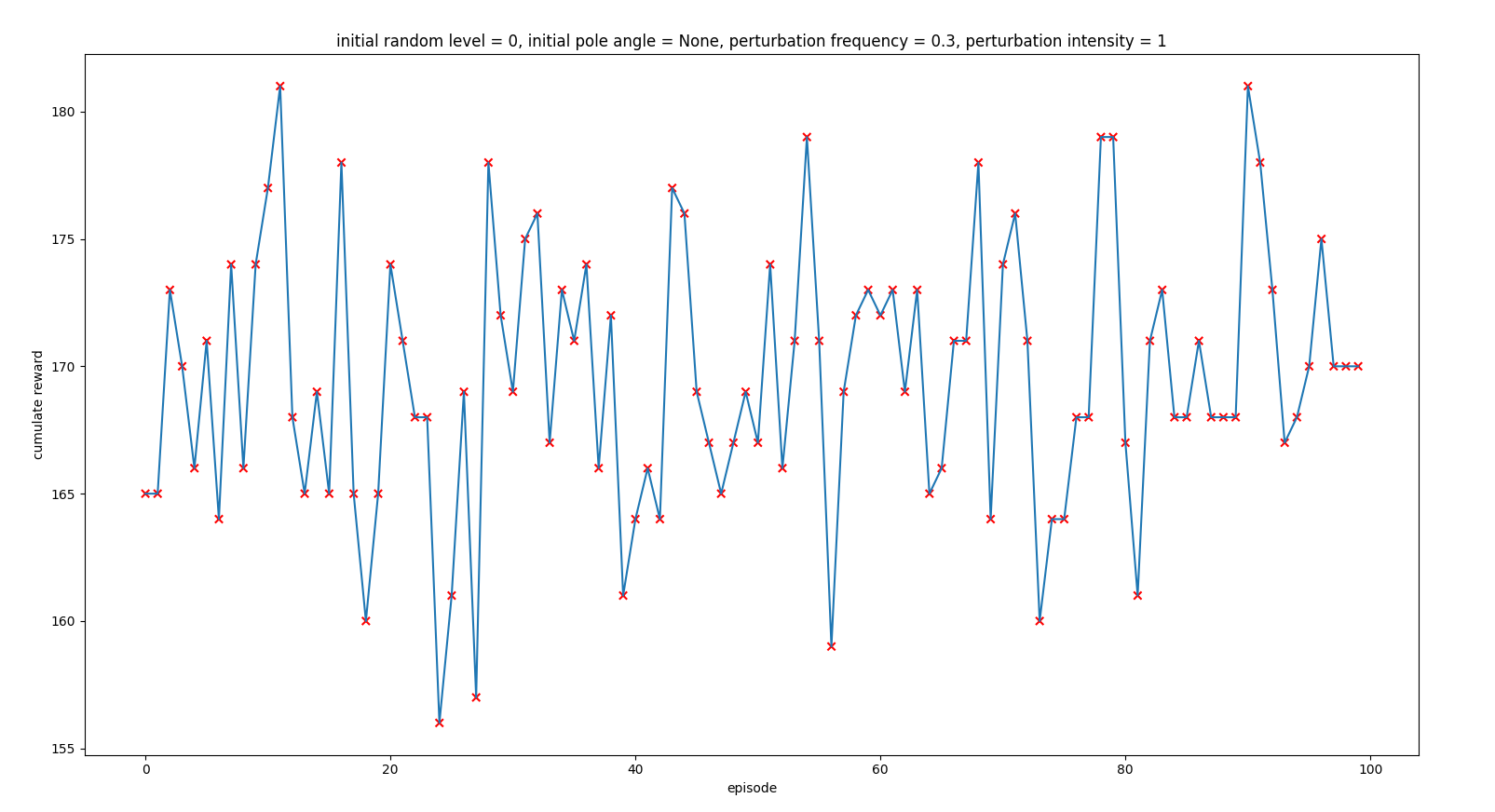
As we could see in previous post, when we configured:
- random_perturbations_level = 0.3 (perturbation in 30% of control iterations)
- perturbation_intensity = 1
the agent was not able to reach the end of the episode, being the result the following one:
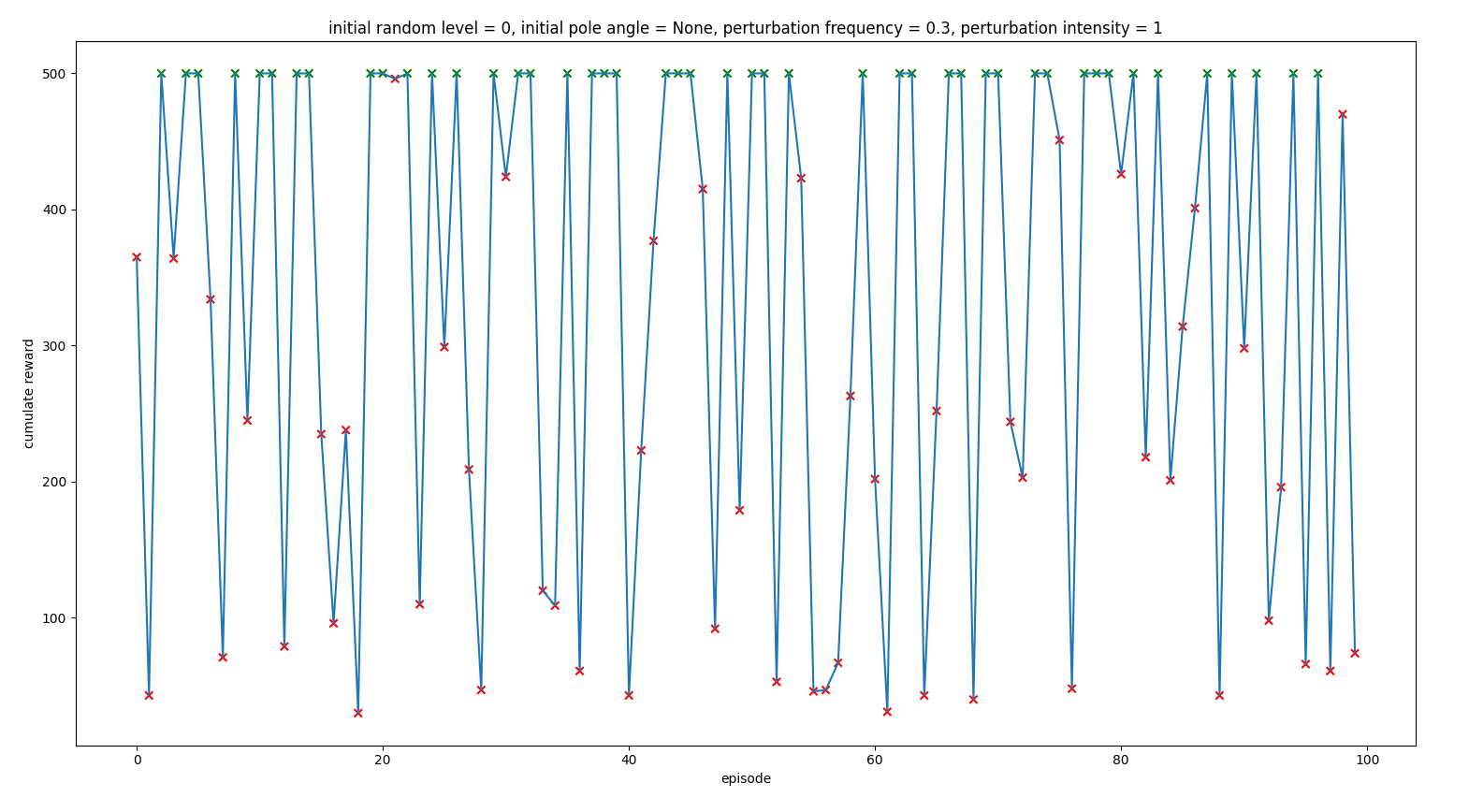
Increasing the frequency in which the agent sensor the current state
Increasing the frequency in which the agent received the inputs it was much more precise in which action to take.
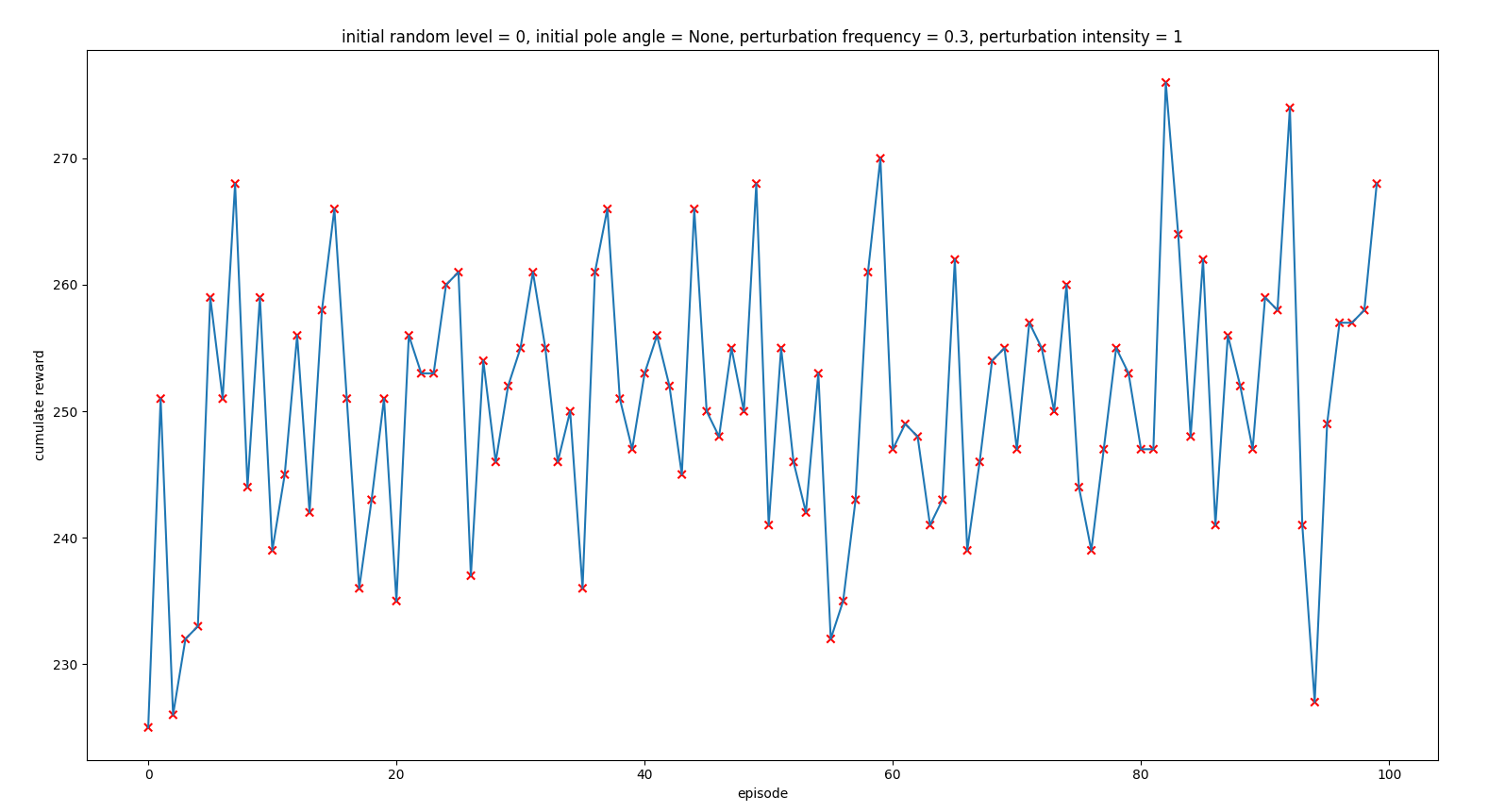
That demonstrated that the problem was that the agent was taking an action for an state that was not reflecting the real current situation because a perturbation happened between the last state measure and the agent new decision.
Training with random perturbations
Now we will check if training with random perturbations help the agent to solve this kind of perturbations.
trained with no perturbations
Starting from the reached performance shown in previous section (Increasing the frequency in which the agent sensor the current state):
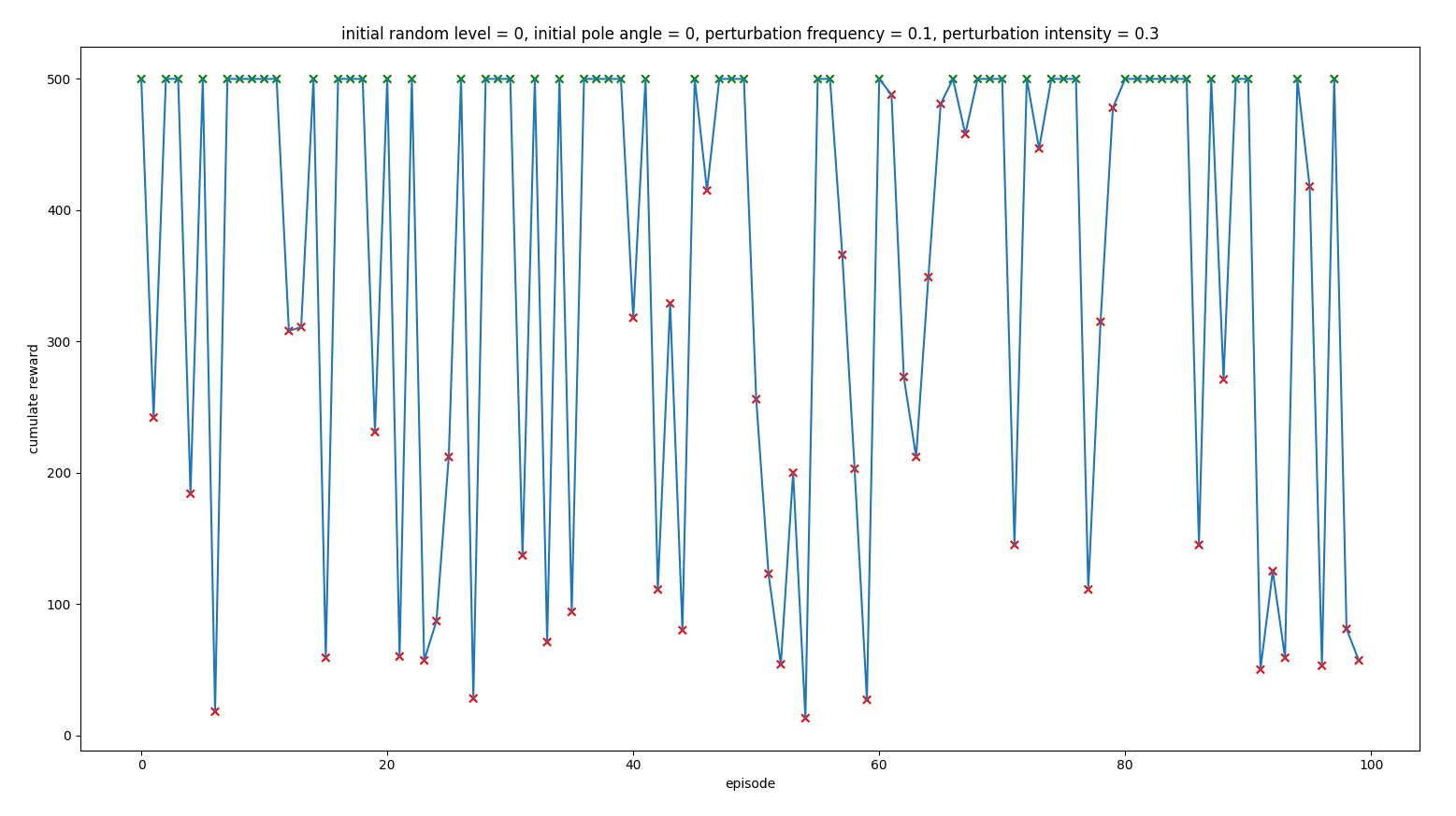
Now, instead of training the agent with ideal conditions, we will set the perturbation frequency to 0.1 and we will play with the intensity of those perturbations.
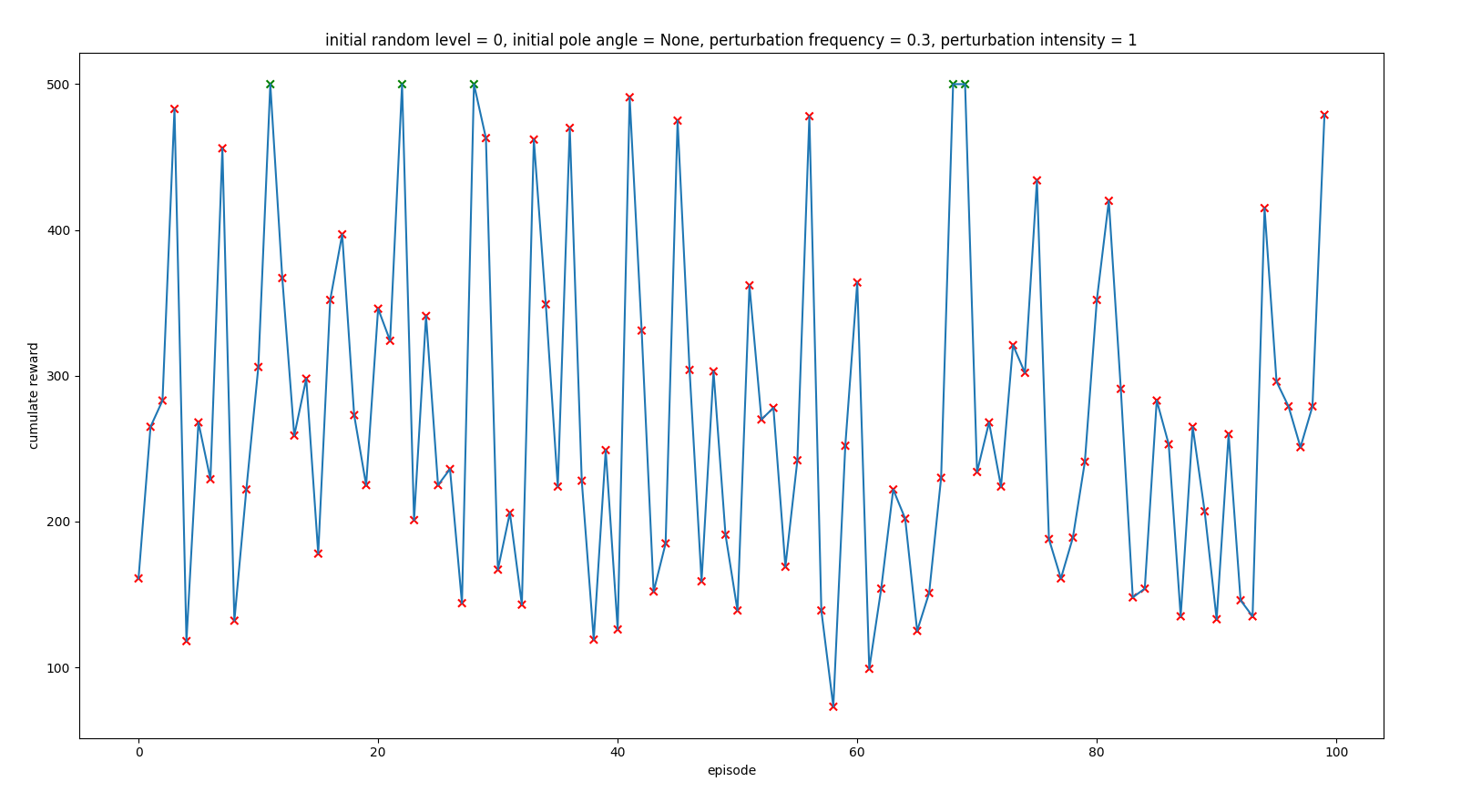
Trained with intensity 0.1 times the action taken by the agent
Trained with intensity 0.3 times the action taken by the agent
Trained with intensity 0.5 times the action taken by the agent
Trained with intensity 0.7 times the action taken by the agent
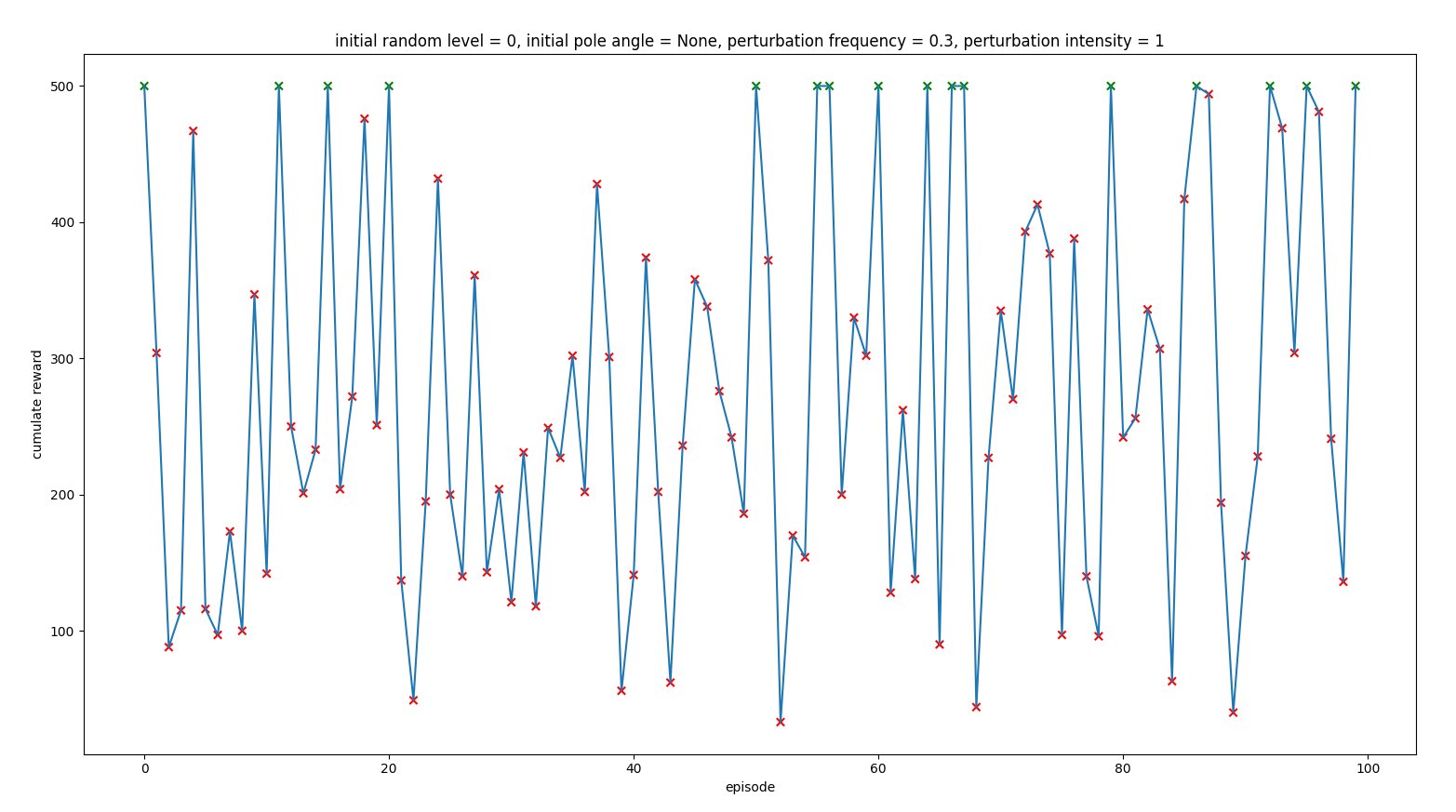
As we could see, none of them worked better than the agent trained with 0 perturbations noise. Our conclusion is that it didn’t help because the agent did not know if a perturbation was the problem or its action was not the right one so it made the situation worse.
Giving extra information to the agent when perturbations happen
That said, we tried to include this previous perturbation to the state that the agent is using to learn. It may be able to sensor this perturbation in any way in the real world and it may help the agent to know how to behave when the perturbation occurs.
Adding this we got the agent to stop learning. Even when no perturbations were configured for the training. It was confused about that non crucial extra information. However, after performing the following code modifications, it started learning from that input:
- Scale this input to be the same magnitude as the others (0 means perturbation to left, 0.1 perturbation to right and 0 no perturbation)
- Increase the number of neurons in the intermediate layer from 64 to 248
Doing that, as it can be seen in the following graph, it trained worse than the agent trained without perturbations, but better than the previous experiments in which it was trained with small perturbation but no hints about them.
Trained with intensity 0.5 times the action taken by the agent
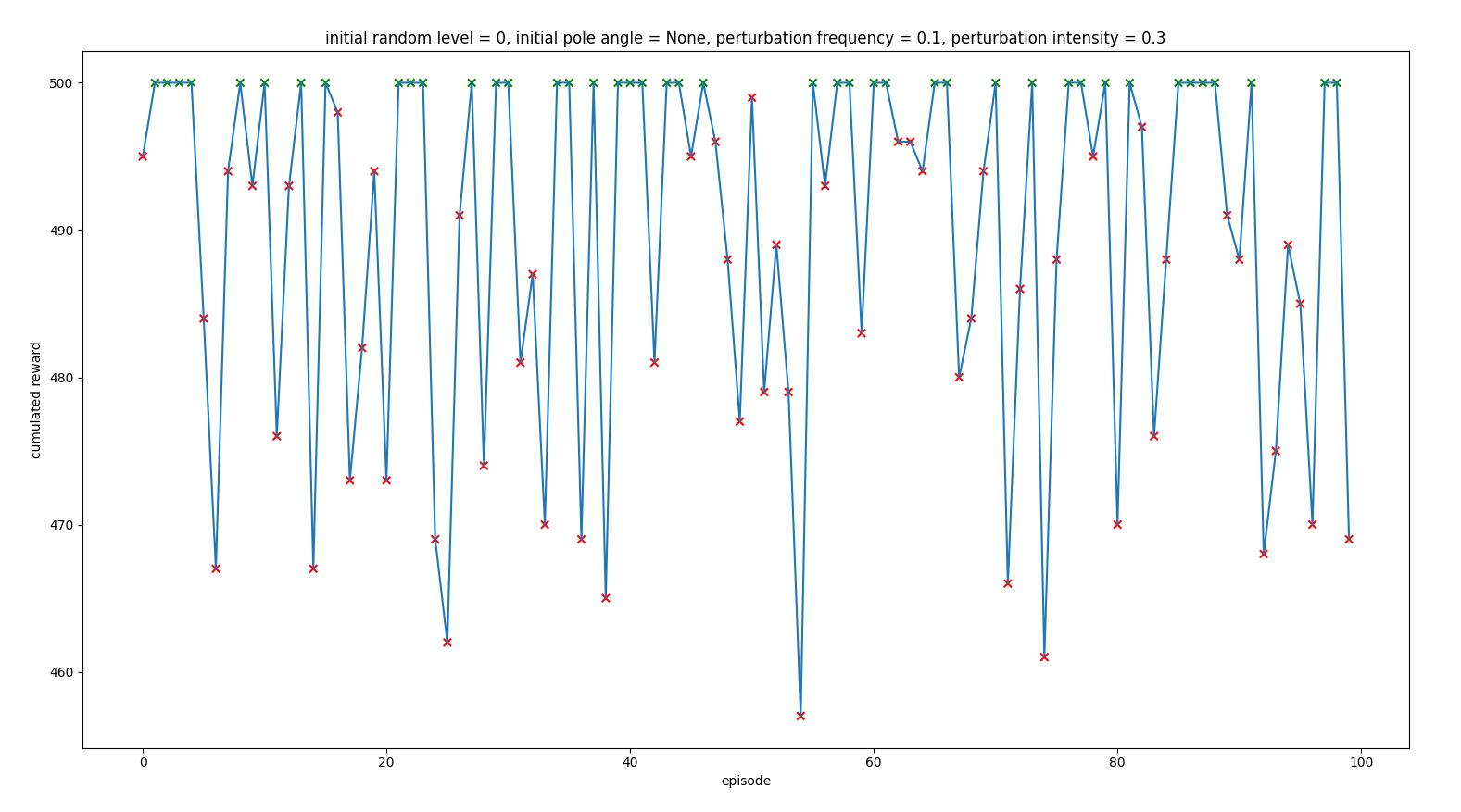
INITIAL STATE
From our previous experiments we conclude that the thresholds from which the agent is able to recover in terms of initial position is:
- Initial state attributes (cart position, pole angle, cart velocity and pole velocity) set between -0.2 and 0.2 except when:
- The pole angular velocity and the cart velocity are set close to the opposite boundary (e.g cart velocity=-0.18 and pole angular velocity=0.19)
- The pole angular velocity and pole position are set close to the same boundary (e.g pole position = 0.19 and pole angular velocity=0.17))
But we didn’t get a conclusion of what happens if the pole starts at rest and what is the pole angle that the agent is able to recover from.
Trained with an initial state of zero pole angle
Using our previously trained agent in ideal conditions, the results are the following:
Inferring with initial state of 0.2 pole angle
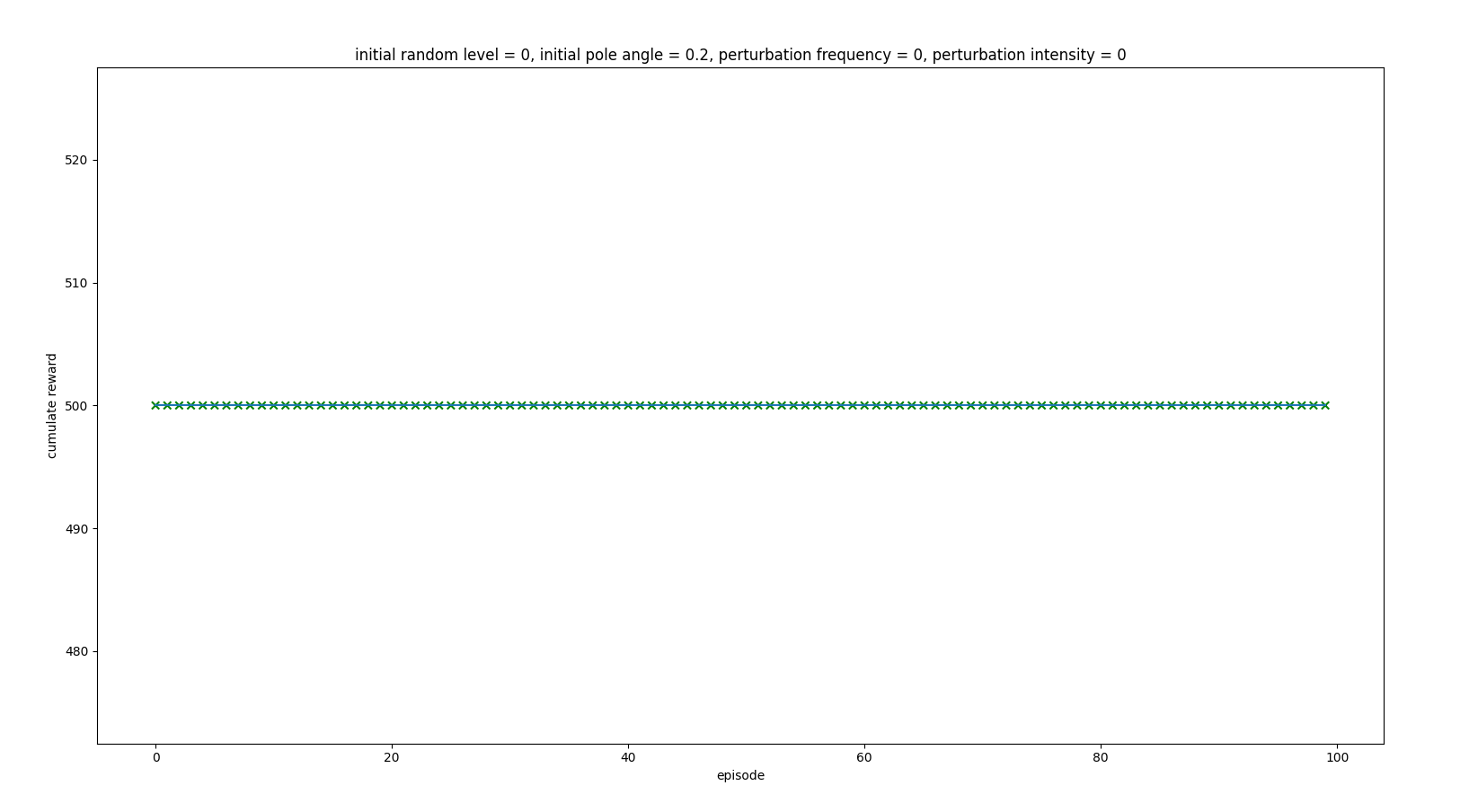
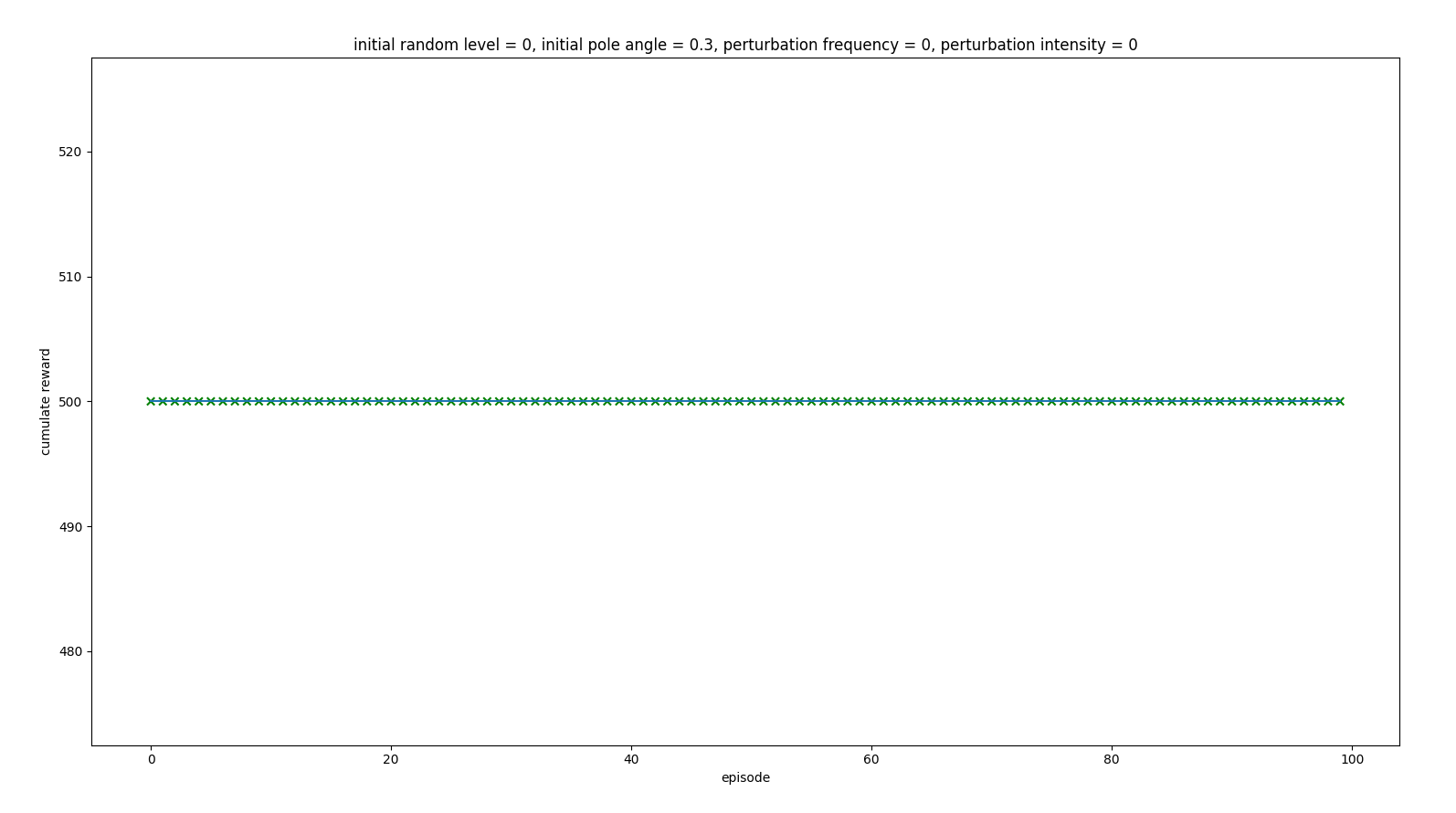
Inferring with initial state of 0.3 pole angle
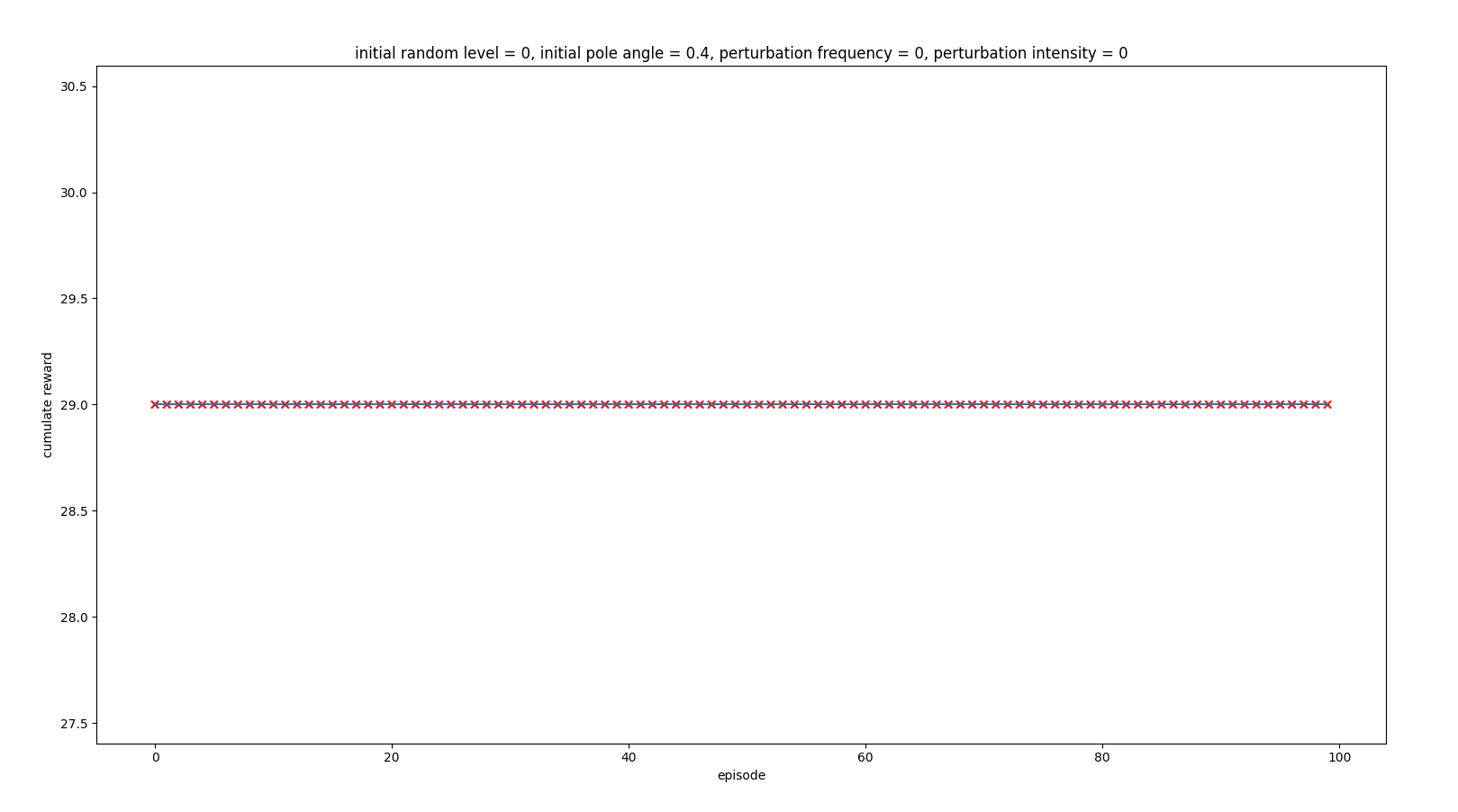
Inferring with initial state of 0.4 pole angle
Trained with an initial state of 0.4 pole angle
We tried the same as with perturbations. Train our agent in the same complex scenario we are trying to solve
Inferring with initial state of 0.4 pole angle
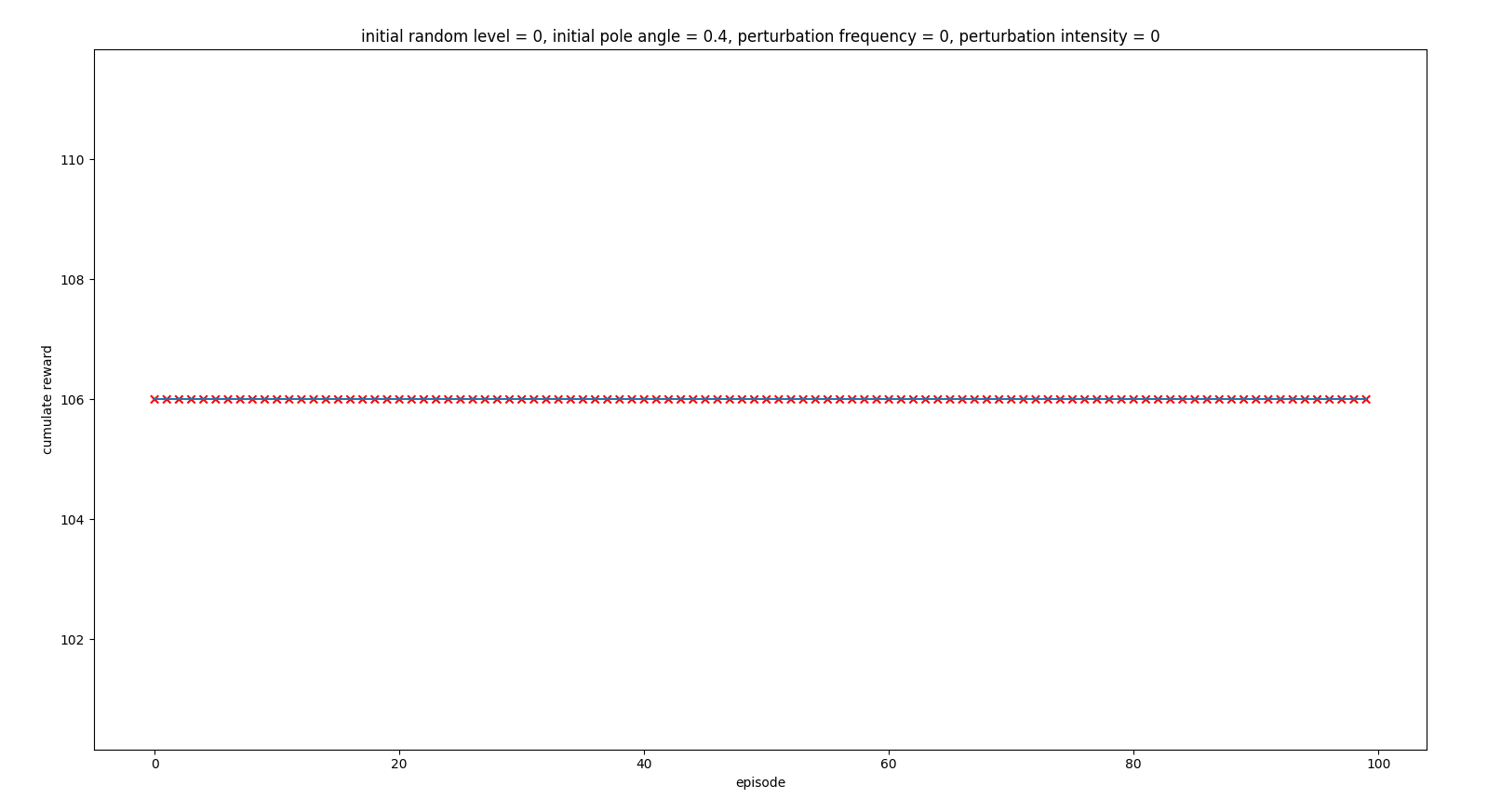
After the visualizations, we observed that the actions the agent was taken were correct (all the time right to correct the pole), but it was not possible to recover the position within the constraints of the problem (iteration controls frequency and actions force) So it is not a problem of the agent not being able to recover, it is problem of the problem imposed, which given the environment conditions and the problem design, makes the solution impossible.
CONCLUSIONS
- logging is important to discover bugs where you assumed a correct behavior
- Training conditions needs to be feasible enough so the agent randomly learns the optimal actions to reach the objective
- Sometimes the agent abruptly learns how to behave. The learning is not linear
- reward function tuning is key
- Sometimes the agent learned to reach the 500 episodes moving little by little to the right and in episode 500 is almost jumping out of the environment bounds (but reach the 500 steps goal). Not always reaching the goal means that your agent learned the optimal behavior. I may have learned the minimum possible to reach the goal, so define good the goal is important.
- neural network size and number of layers are capricious. Nor too much nor too little. Additionally, more inputs should mean that more neurons in intermediate layers are needed, but it does not means that the increase must be linear. In our case, when adding one more action (5 instead of 4), we needed to quatriplicate the number of neurons in the intermediate layer.
- It is important to sensorize as frequent as possible (and it is critical o sensorize just before taking the action). Otherwise you may miss some important information or even you will decide with delayed state, what means the agent will surely fail.
- Training with perturbations letting the agent now that it was perturbed helped a little. If you have a problem or an external agent that make your scenario more complex. try to add this agent actions as an input or your model will suffer to figure it out what it is fighting against. BUT make sure you are adding this information because it is crucial to know that information to reach the goal and tune this input to scale it according to its importance (all the inputs should be normalized to indicate the agent their importance)
TO EXPLORE
- If the problem actions are too wide and the optimal actions impossible to learn in a randomly way, we can use iterative learning to make our agent learn how it has to behave (going gradually from the most basic scenario to the complex one)
- Adaptative learning rate could help. (e.g torch implementation)