Comparing PPO, DQN and QLearn algorithms in cartpole problem resolution
INTRODUCTION
Now that we have solved cartpole with more than one algorithm, lets compare their performance
As a keynote. We did not add any perturbation for any of them when training. The only “kind of noise” that helped them to get a better learning was set a random initial state (including all the possible variables of the state)
Additionally, in all the agents we used the same reward function as it is implemented in the provided cartpole_v1 by openAiGym
The algorithms used are the following:
QLEARNING
Q-learning is a reinforcement learning technique used in machine learning. The goal of Q-learning is to learn a set of rules that tells an agent what action to take under what circumstances. It does not require a model of the environment and can handle problems with stochastic transitions and rewards without requiring adaptations.
For any finite Markov decision process (FMDP), Q-learning finds an optimal policy in the sense that it maximizes the expected value of the total reward over all successive steps, starting from the current state.1 Q-learning can identify an optimal action-selection rule for any FMDP, given an infinite exploration time and a partially random rule1 “Q” names the function that returns the reward that provides reinforcement and represents the “quality” of an action taken in a given state.
The training in this case took 2 hours and 30 minutes
The training in this case took around 12 hours and it was trained in two rounds:
- round 1 (8 hours):
- initial epsilon = 0.99
- initial pole angle = 0
- initial pole position = 0
- round 2 (4 hours)
- initial epsilon = 0.99
- random initial state with mean = (MaxPossibleState - MinPossibleState / 2) and standard deviation = 0.3
In both rounds, we used:
- alpha: 0.9
- gamma: 0.9
- number of bins for the angle-related state components: 300
- number of bins for the position-related state components: 50
DQN
The DQN (Deep Q-Network) algorithm was developed by DeepMind in 2015. It was able to solve a wide range of Atari games (some to superhuman level) by combining reinforcement learning and deep neural networks at scale. The algorithm was developed by enhancing a classic RL algorithm called Q-Learning with deep neural networks and a technique called experience replay.
The training in this case took around 1 hour
The parametrization was the following:
- A double network to stabilise the agent performance as explained in the following blog
- A experience replay buffer of 256 state-actions-rewards
- An intermediate neural network layer of 64 neurons
- The following gamma value: 0.95
- random initial state with mean = (MaxPossibleState - MinPossibleState / 2) and standard deviation = 0.1
PPO
The idea with Proximal Policy Optimization (PPO) is that we want to improve the training stability of the policy by limiting the change you make to the policy at each training epoch: we want to avoid having too large policy updates.
For two reasons:
- We know empirically that smaller policy updates during training are more likely to converge to an optimal solution.
- A too big step in a policy update can result in falling “off the cliff” (getting a bad policy) and having a long time or even no possibility to recover.
for more details regarding PPO, it is explained in the following post And even more in detail here
In this case the training took around 5 minutes to converge
We used the “Clipped Surrogate Objective” approach and the parametrization was he following:
- gamma: 1
- epsilon: 0.15
- random initial state with mean = (MaxPossibleState - MinPossibleState / 2) and standard deviation = 0.2
Programmatic
Knowing the physics of the pole and the actions intensities we can think about a procedure to correct the pole angle in a deterministic way (i.e without needing a simulation, exploration, training, etc.) The reasoning behind this algorithm is explained in the following post
TRAINING
All of them got to resolve the problem reaching the 500 steps but not all of them learnt the optimal policy (and we even cheated a litle with qlearning, since it is not randomly initialized, so it actually learnt to resolve the most basic version of the problem)
As we can see in the following figure, qlearning needs much more exploration to solve the problem than the deep reinforcement learning algorithms because it has to fill the q values table for such a variable problem (it takes much less time if we discretize with one order of magnitude less, but the results are even much worse). We can say then that ppo is more sample efficient than dqn and both of them much more than qlearning
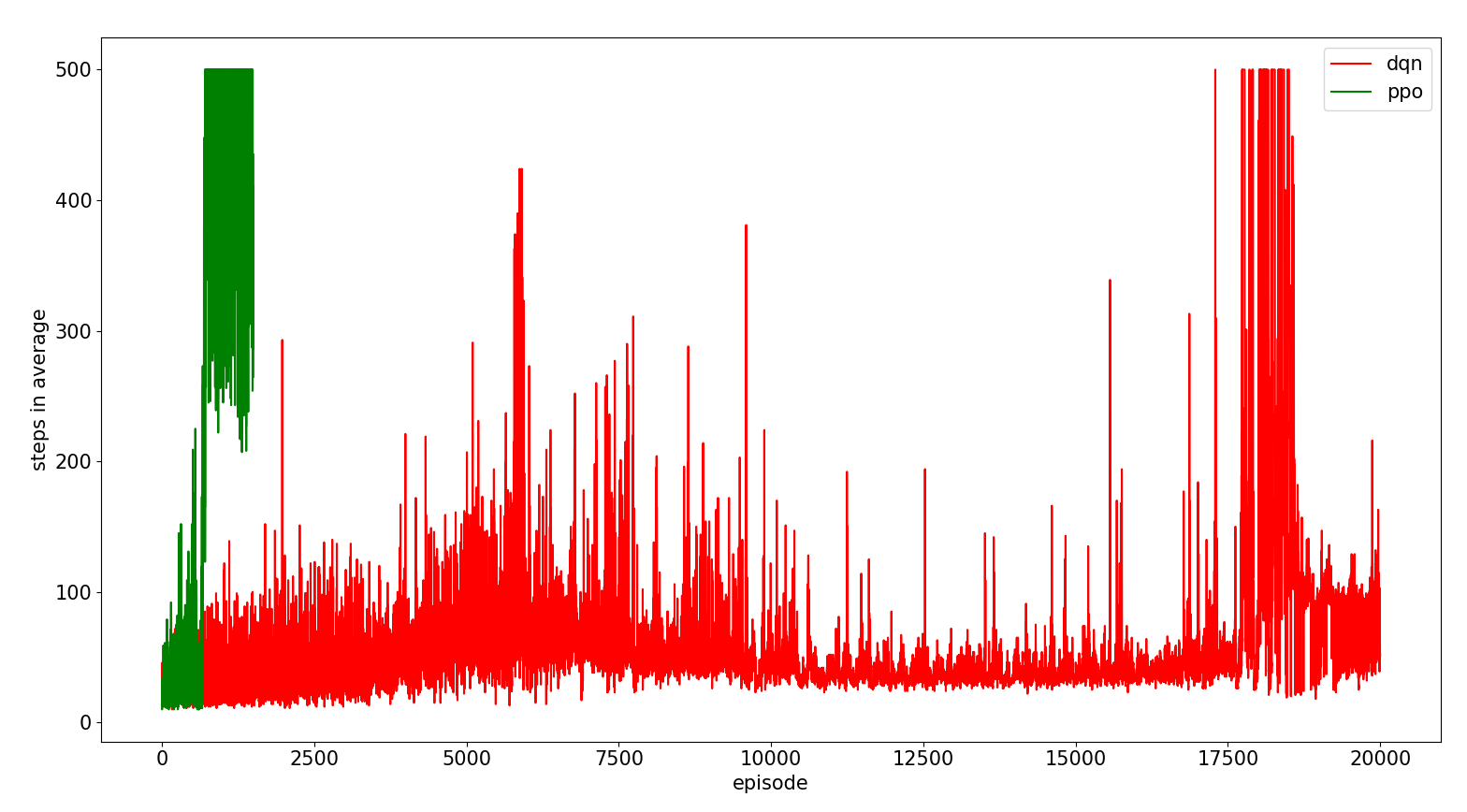
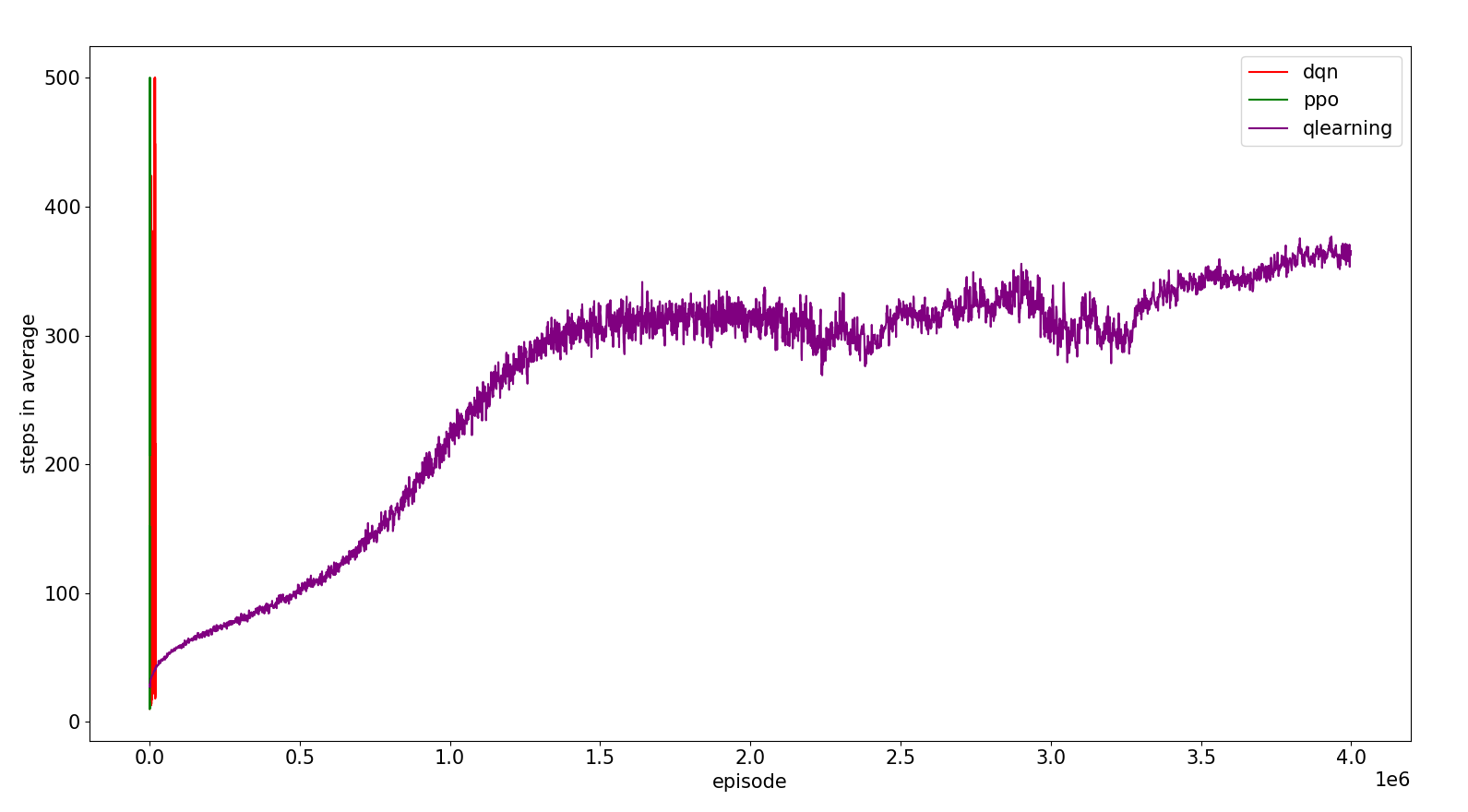
INFERENCE
Additionally, if we add perturbations to the problem, DQN and PPO are able to recover from quite high level of perturbations. For more details about what it is able to achieve, see the following post
On the other hand, QLearning and programmatic performances considerably decrease when adding a minimum difficulty to the basic scenario.
To illustrate that, we will show the solidity tests results in the following sections
PERTURBATIONS INTENSITY TOLERANCE
The first conducted experiment was to vary the perturbation intensity with a fixed frequency.
knowing that the frequency is 10% of the control iterations and that cartpole actions intensities has a value of 10, the following figure illustrates how robust the agents are to this situation:
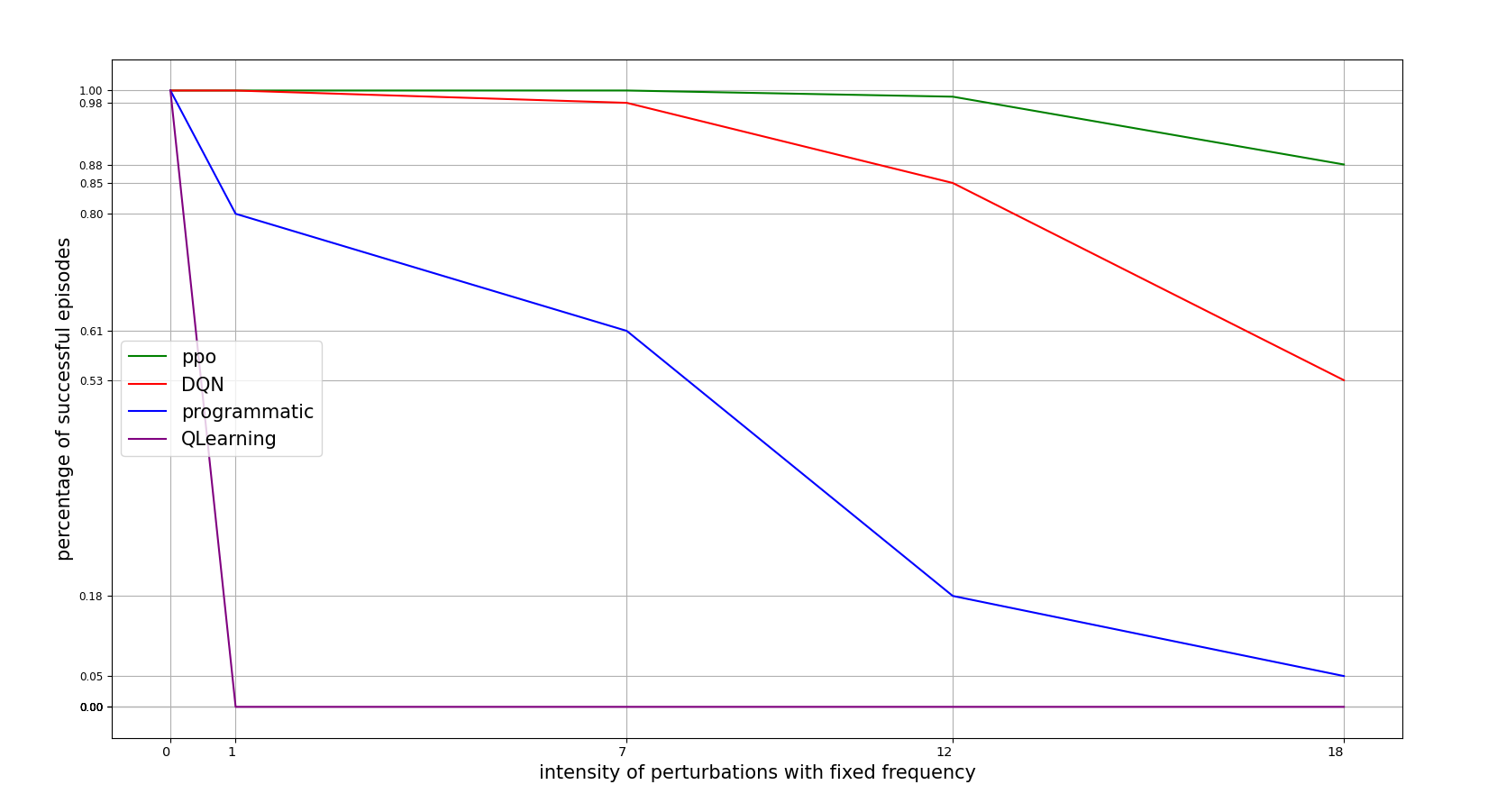
PERTURBATIONS FREQUENCY TOLERANCE
The second conducted experiment was to vary the perturbation frequency with a fixed intensity.
knowing that the intensity is 1 and that a frequency of 0.1 means a perturbation in a 10% of the control iterations, the following figure illustrates how robust the agents are to this situation:
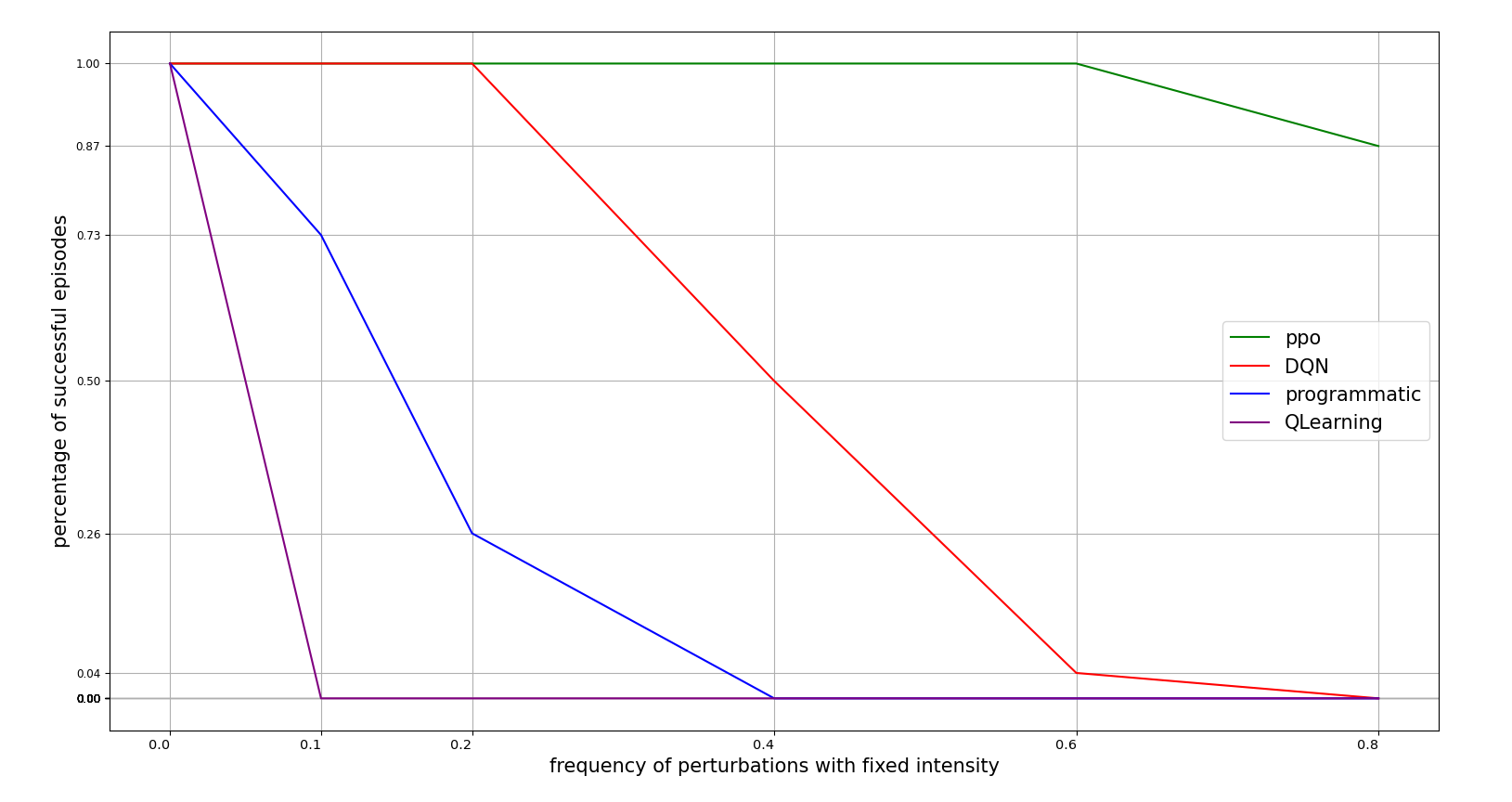
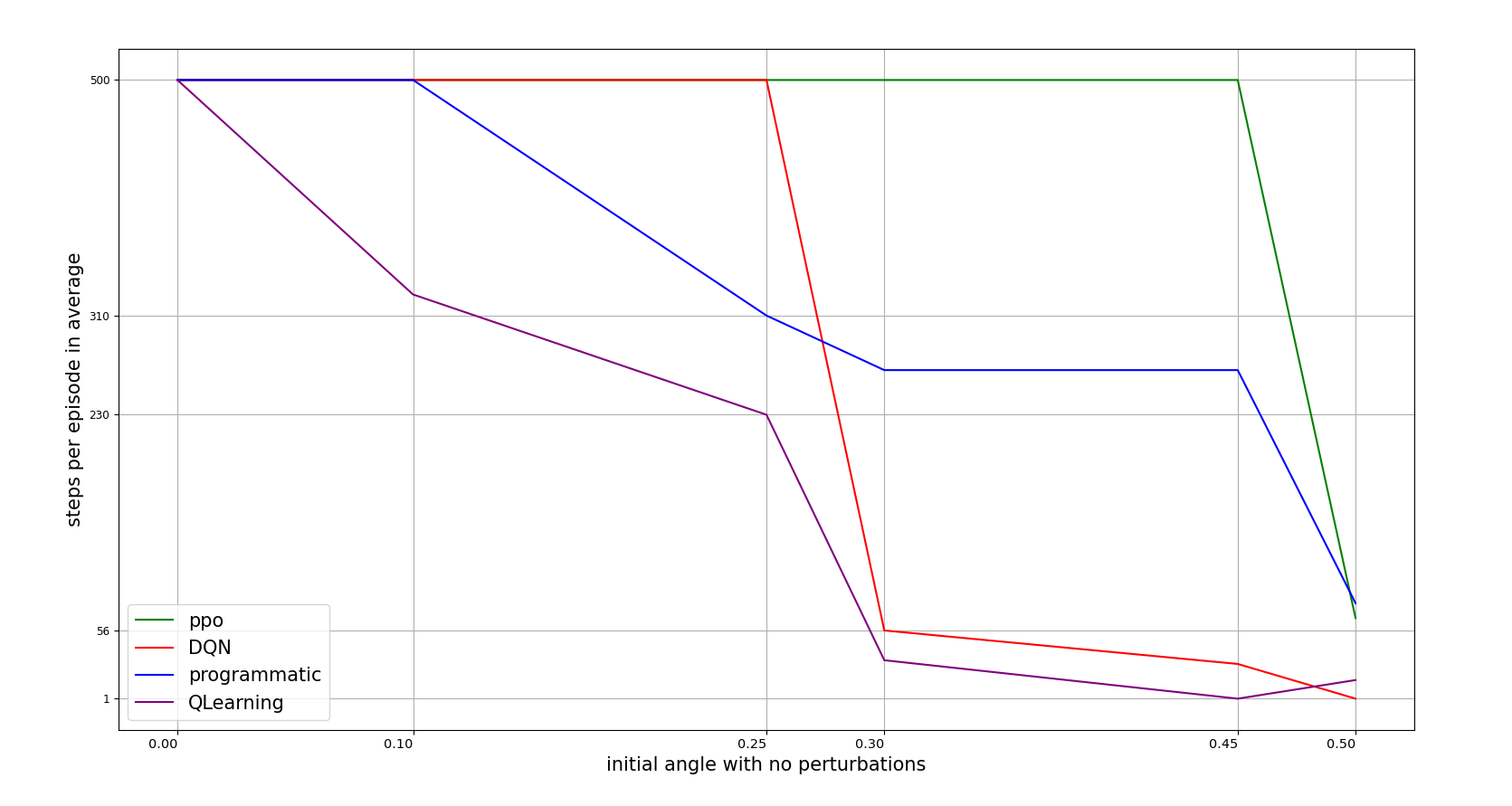
INITIAL POLE ANGLE TOLERANCE
The third conducted experiment was to vary the initial pole angle with no perturbations in the whole episode. In this way we can measure how adverse pole angle the agents are able to recover.
the following figure illustrates how robust the agents are to this situation:
PPO trained agent demo
CONCLUSIONS
We showed that when a wide possible actions and states are encountered, a DRL algorithm is more adequate.
Additionally, ppo showed to be the most sample efficient and best performance agent of these 4.
For more info of the whole way to this post and the different lessons learned, check the following previous cartpole-related posts: