
Semana 24: Comparación códigos deeplearning, modelos fiales de taxi y f1 (grande)
He comparado los códigos del ejercicio de “human detection” y de “digit classifier” para encontrar las líneas que causan que algunas veces el primero cierrre la conexión con el mánager. Las únicas diferencias que he visto, son debidas a que el ejercicio de human detection también tiene la funcionalidad de hacer un benchmarking del modelo subido con vídeos e imágenes, y poder visualizar la estructura d la red. Pero en principio al no hacer uso de ello no deberían dar error.
Por otra parte he estado cambiando el modelo del coche de la anterior semana, para tener tanto el coche f1 como el taxi con geometría de Ackermann.
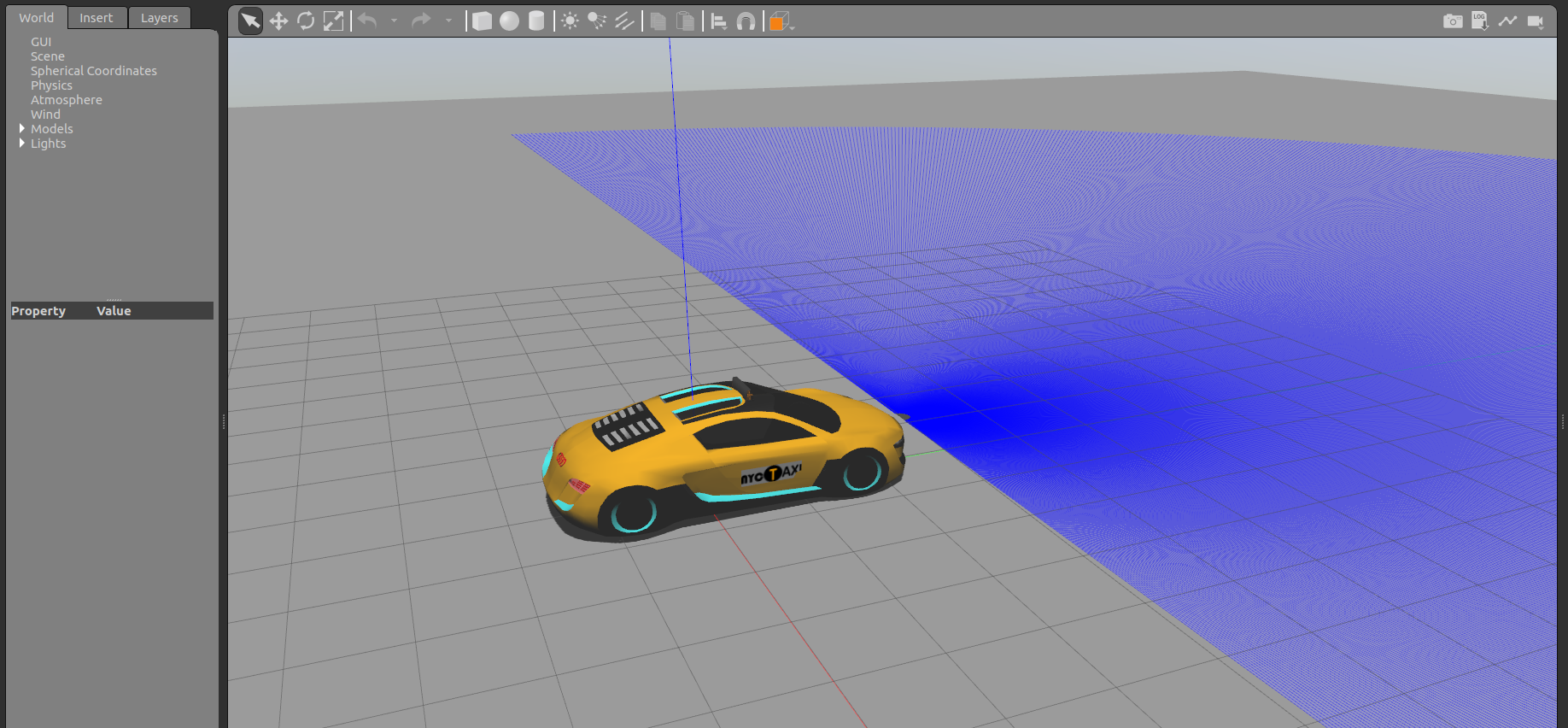
Por desgracia no me percaté de que los circuitos del “follow line” no se encuentran a tamaño real y al escalar de manera directa el coche las ruedas dejan de funcionar correctamente.
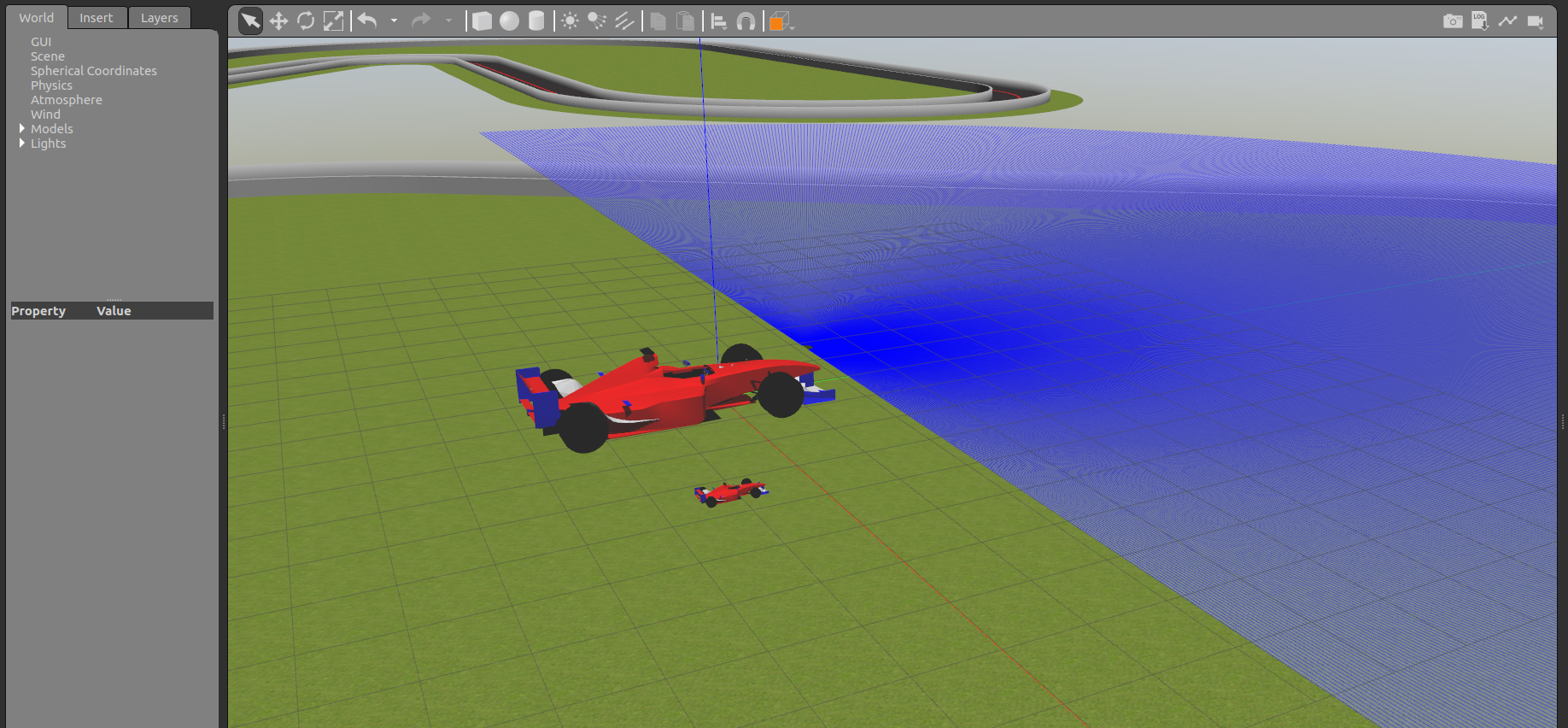
Para el coche de f1 pequeño tendré que definir las ruedas una a una para que funcione.