
Semana 32: Percepción neuronal con segmentación semántica en CARLA
Prueba con los scripts
Durante esta semana se ha trabajado en la integración de la parte de percepción neuronal con segmentación semántica dentro del entorno de simulación de CARLA.
El objetivo principal era sustituir la cámara de segmentación semántica del simulador por una red neuronal entrenada capaz de realizar la inferencia directamente sobre las imágenes RGB generadas en tiempo real.
Para ello, se realizó una llamada con David Pascual, en la que explicó el funcionamiento de los scripts relacionados con el entrenamiento y la inferencia de la segmentación visual del proyecto GAIA, principalmente sobre el inference.py, responsable de ejecutar la segmentación semántica de una imagen mediante un modelo entrenado.
Posteriormente, proporcionó un modelo ya entrenado para realizar pruebas:
segformer_mit-b2_8xb1-160k_cityscapes-1024x1024-epoch=epoch=13-step=step=23898-val_miou=val_miou=0.78.pt.
Inicialmente se probó el script con una imagen de 1920×1200 píxeles, pero se produjo un error en la salida, indicando que la GPU con una memoria de 12 GiB era insuficiente para realizar la segmentación.
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 382.00 MiB. GPU 0 has a total capacty of 11.63 GiB of which 319.50 MiB is free. Including non-PyTorch memory, this process has 10.77 GiB memory in use. Of the allocated memory 10.38 GiB is allocated by PyTorch, and 253.37 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Para solventarlo, se redujo la resolución de entrada a 960×600, lo que permitió ejecutar la segmentación correctamente:
Imagen Original

Imagen Segmentada
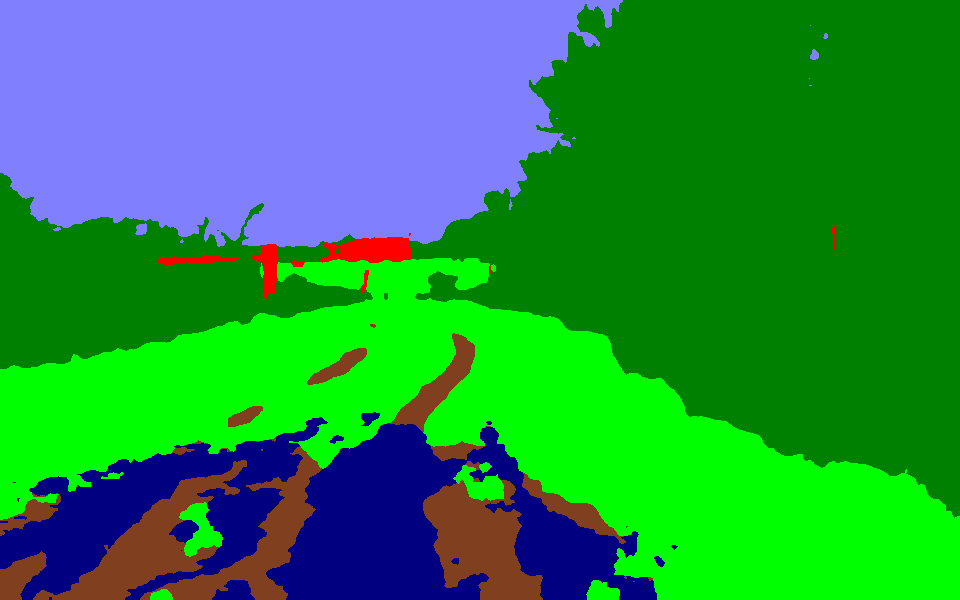
Integración en CARLA
Finalmente, se modificó el script usado en CARLA simulator con el control PID hecho anteriormente, pero sustituyendo la cámara de segmentación verdadera por las imágenes resultantes de usar el modelo neuronal en las imágenes obtenidas por la cámara RGB. Para ello, fue necesario realizar algunos ajustes al script inference.py.
load_segmentation_model()
Primero se creo una función encargada de cargar el modelo una única vez anl inicio, evitando recargar el modelo en cada frame, lo cual generaría un gran consumo de recursos y ralentizaría la simulación.
def load_segmentation_model(model_path= , device="cuda"):
print(f"Cargando modelo de segmentación desde {model_path}...")
model = torch.load(model_path, map_location=device)
model = model.to(device).eval()
print("Modelo cargado correctamente.")
return model
run_segmentation_model()
Esta función se encarga de realizar la segmentación semántica sobre la imagen RGB actual utilizando el modelo previamente cargado. Su estructura se basa en el script original de inference.py.
def run_segmentation_model(model, device="cuda", inference_mode= "torch"):
global rgb_image
image = rgb_image
lut = ontology_to_lut(COMMON_ONTOLOGY)
image = Image.fromarray(image)
tensor = transforms.ToTensor()(image).unsqueeze(0)
tensor = transforms.Normalize(mean=IMAGENET_MEAN, std=IMAGENET_STD)(tensor)
#model = model.to("cuda").eval()
tensor = tensor.cuda()
if inference_mode == "torch":
pred = model(tensor).cpu()
elif inference_mode == "mmsegmentation":
pred = model.inference(
tensor,
[
dict(
ori_shape=tensor.shape[2:],
img_shape=tensor.shape[2:],
pad_shape=tensor.shape[2:],
padding_size=[0, 0, 0, 0],
)
],
).cpu()
else:
raise ValueError("Invalid inference mode provided.")
if inference_mode != "mmsegmentation":
pred = F.interpolate(pred, tensor.shape[2:], mode="bilinear")
pred = torch.argmax(pred, dim=1).squeeze().numpy()
pred_rgb = lut[pred]
pred_rgb = Image.fromarray(pred_rgb)
return pred_rgb
segmentation_callback()
Finalmente, el callback de segmentación se modificó para utilizar la salida de la red neuronal en lugar de la cámara de segmentación de CARLA. La imagen resultante es la que se usa ahora como base para el control PID.
def segmentation_callback(image, display_surface, frame):
global visual_error, segmentation_model
# Ejecutar el modelo de segmentación neuronal
pred_rgb = run_segmentation_model(segmentation_model,inference_mode="torch")
# Convertir el resultado a numpy
seg_array = np.array(pred_rgb)
seg_array = np.ascontiguousarray(seg_array)
####### Control PID ########