Week 10-11. Running different exercises from repo
These weeks have been for the study and understanding of the different methods and agents that exist in Alberto Martín’s repository. This brings us closer to the real environments where the work will be developed.
To Do
The tasks proposed for this week are
- Perform different exercises from the “puppis” section. repository.
- (OnGoing)Install environment to replicate examples of Vanessa Fernandez’s end-of-master job.
Progress
In this period different exercises of the Gym environment have been executed where the different learning methods are tested before different agents.
The tested methods have been:
cross_entropy.dqn.dynamic_programming(with policy and value iteration).monte_carlotemporal_difference(with and without policy). With QLearning and Sarsa algorithms.
For the execution of the methods in the ‘CartPole’ scenario you have to launch the instruction from the previous directory to ‘puppis’:
- For the SARSA method:
python -m agents.gym.cartpole.sarsa_agent -
For the QLearning method:
python -m agents.gym.cartpole.q_learning_agent
These commands put to execute the training of the environment ‘CartPole’ where it can be seen that when a threshold of inclination is exceeded the exercise is restarted and the learned values are updated to apply it on the next epoch (if it improves with respect to the previous one).
The solution to the cross_entropy method can be seen in the gif:
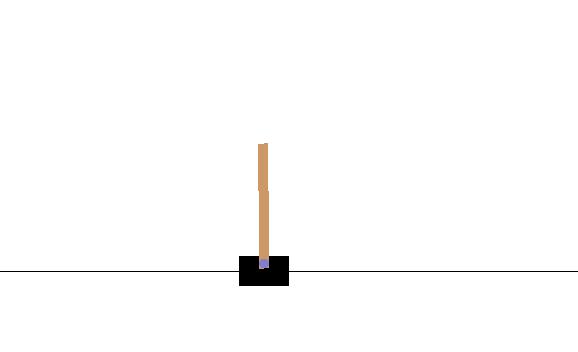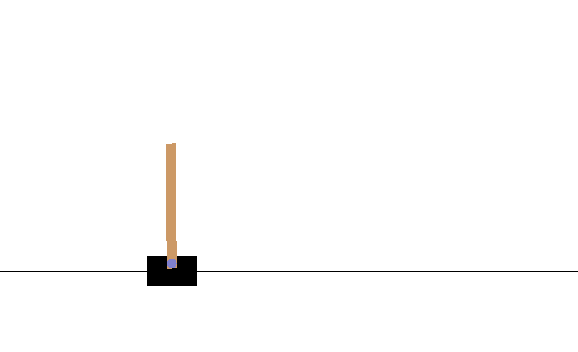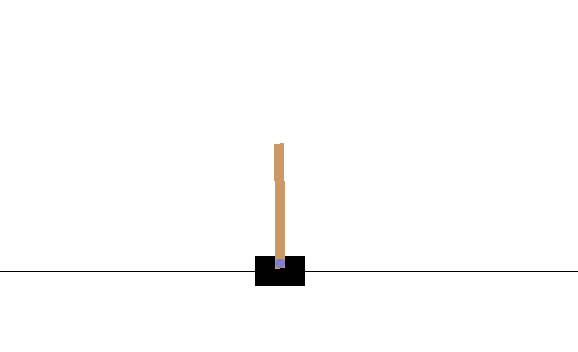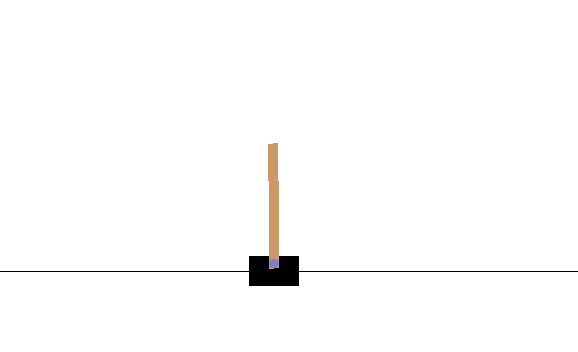
Working
I’m currently reviewing the gym ‘pong’ environment training to get a performance where the agent learns to play the video game.
In addition, I am in communication with Vanessa Fernández to replicate the environment of her end-of-master work.
Learned
At the Python programming level, I have learned to launch programs with modules in parallel using the -m argument. With this it is possible to have the infrastructure separated in a logical way to apply different agents to different methods.
As for the exercises in the repository, there is a clear difference in the times of training and final solution. The cross_entropy method has been the fastest to solve in training with very good results in execution.
Methods such as Q-Learning are less effective at a time when there is no clear separation of all environmental states.