Week 30. First training
To Do
- Change image acquisition to use callback.
- Review the order in the algorithm. Revision of the DQN algorithm.
- Adjustment and first training.
Progress
1. Change image acquisition to use callback
Initially, the image goes through some checks that make the code unreadable. There are two ways: by using a flag to activate the output of a loop that checks if you already have the image or by using the callback.
This week the second way has been explored as an improvement. The result is that, even if it works, the image value needs to be returned. Therefore, the result is the same as without the callback. Once the idea has been explored, we return to the first option without definitively discarding the second one.
2. Review the order in the algorithm. Revision of the DQN algorithm
The revision of the order of the algorithm was because in the steps we believed that first the action was selected and then the observation. By diving further into the code we saw that, the restart of the environment, brings with it the acquisition of an image. Once we checked the development we confirmed that the DQN algorithm follows the scheme of: $observation –> Action –> Decision$ as you can see in the following image.
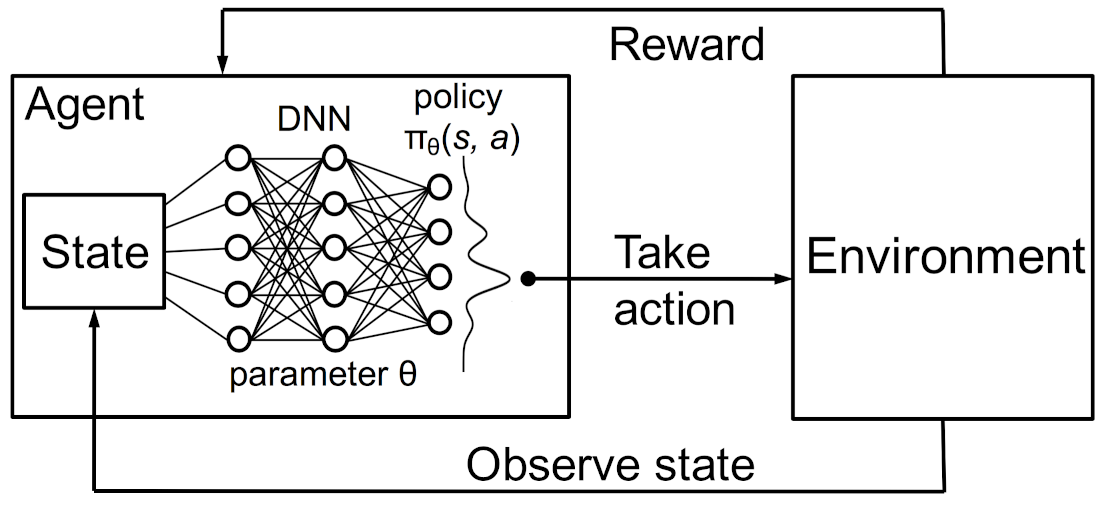
3. Adjustment and first training
The summary of the first training is that: “it went well”. The training time has been 5 hours. The first 4, the robot only walked without control to one side and the other of the line without apparent logic. Once the 10,000th time was reached, an improvement in the number of steps could be seen, increasing considerably but, just before restarting, the robot took a very pronounced direction and lost the line. It was in the time 12.000 where, with $\epsilon = 0.01$ it exploited what it learned during the first stages and followed the line perfectly until the first curve. You can see in the following animations the result :-)


Working
A review of the linear and angular speed parameters is necessary to make the curve possible. The current parameters are not set correctly to allow this to be done. A readjustment will be necessary on both outputs.
On the other hand, when $\epsilon$ is too low it is too late for Formula1 to “understand” what a curve is. At that point in the learning process it is too late to face it and it would take too long. As a test, the car will be moved closer to the corner and “understand” that state.
Learning
Now it gets interesting. Let’s see if the parameter setting improves the final state of the training. By next week I hope to have new results. Stay tuned!