Week 36-43. F1 complete a lap
To Do
- Step back but sure. Enter an algorithm using Qlearn with the laser.
- Test the training on other circuits like the Nürburgring.
- Refactoring of the code.
- Correction of errors.
Step back but sure. Enter an algorithm using Qlearn with the laser.
Since the advances in training level have not gone as well as we would like to try with a simpler algorithm and with less infrastructure as Qlearn is.
The example provided by the library of gym-gazebo leaves an environment where, making small corrections you can have the example working.
After several hours of training, the car managed to advance a lot on the circuit, sometimes even completing the lap (in the error correction section I detail why this didn’t always happen). The “model” generated from Qlearn doesn’t have the aspect to which we would be accustomed in Deeplearning (immense set of parameters whose file occupies a few MB) but it is a simple dictionary (of Python) where the key is the tuple $(state, action)$ and the value the reward generated by that set.
I could conclude that one of the problems why the training using the camera with DQN did not advance was because we were not “teaching” well the following state $(t+1)$ in which it is once it takes the action on the current state $(t)$. This was one of the reasons why we moved to a simpler algorithm, to understand this logic.
With the example of the formula 1 using the laser as a sensor in the simple solved circuit, we have moved to the same scenario but using the camera as a sensor with the aim of obtaining the same result. I am currently developing this logic.
Another important element in which I could see that the algorithm trains much faster are the “random starts”. Creating a logic in the code that allows to place the formula 1 in certain positions makes that each “restart” enriches the set of state in a faster way because if, for example, a very closed curve would only see it at the end of the circuit… it would only bump into it when it manages to solve all the previous thing. With these “jumps” around the circuit, we accelerate the exploration process and in less time, the set of (state, action) grows faster.
In the following figures you can see some graphics of the training of the car. The pronounced peaks with high reward values correspond to the areas where the car managed to make a complete lap of the circuit. For this solution a slightly more limited set of actions was used as it was not necessary to have such a high angular speed. Extreme turning values were eliminated from the set. The left figure represents 800 times and the right figure 1000 times.
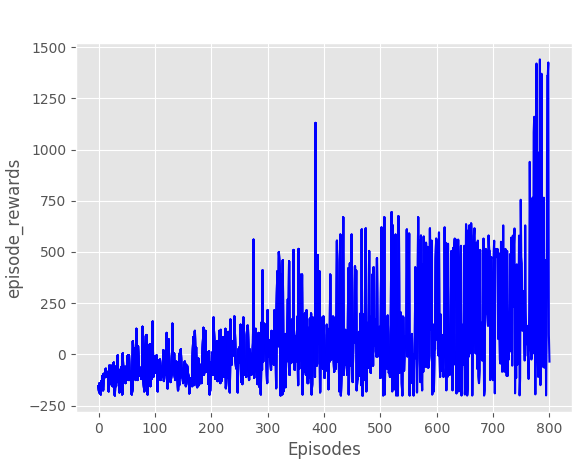
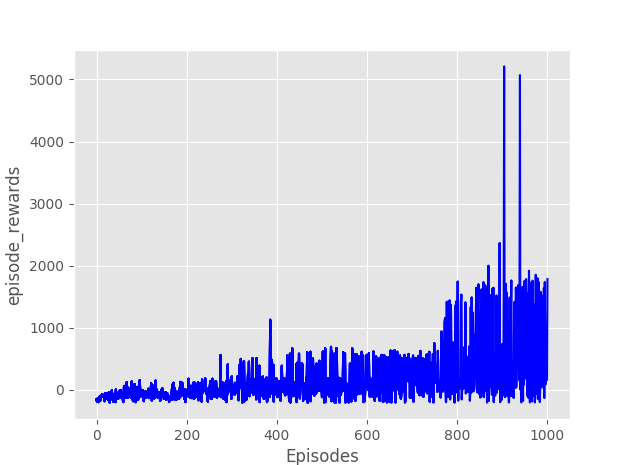
A video summary (accelerated) of the result can be seen below.
Test the training on other circuits like the Nürburgring
With these advances in the Qlearn algorithm it is proposed to carry out a more complex set of actions (go from 3 to 7) in a circuit with different types of curves (some very closed). This circuit is a replica of the Nürburgring. Below you can see a table with the selected set of actions.
| Action | lineal vel | angular vel |
|---|---|---|
| 0 | 3 | 0 |
| 1 | 6 | 0 |
| 2 | 3 | 1 |
| 3 | 3 | -1 |
| 4 | 4 | 4 |
| 5 | 4 | -4 |
| 6 | 2 | 5 |
| 7 | 2 | -5 |
Refactoring of the code
In this adaptation to a simpler algorithm I have recognized patterns that have served me to structure and simplify the code. There is still work to be done in this grouping but a lot of progress has been made leaving, for example, the logics of the step and reset methods very simplified.
Correction of errors.
In this refactoring process, errors have also been corrected such as, for example, that after a few formula 1 steps on the circuit, the laser was sinking, causing the stage to restart and start again, even when the result was good. This was due to a failure in the sensor, which was not “well attached” to the car and caused that, by the physics of the simulator, it moved a little until the restart of the environment.
This has now been fixed and the laser beam is uniform throughout the stage. You can see an example of the before and after in the next image.
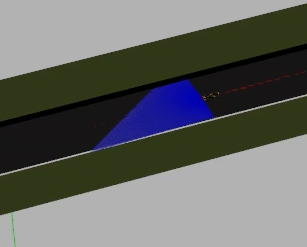
Working
I’m working on getting the same results with the camera as with the laser and solving bugs on restarts so that the car is placed in a different position.
Learning
We have needed to simplify the problem a lot to understand the knowledge behind how it learns.