Week 35. New trainings with jumps
To Do
- Change pose every epoch.
- New action set.
- New training with the new configuration.
Progress
Change pose every epoch
It has been achieved that every time the environment is restarted the Formula 1 appears in a different place of the circuit. The aim is to avoid taking tendencies to one side or the other of the curves and to be able to generalize well.
The result of this jump between positions can be seen in the following animated image.
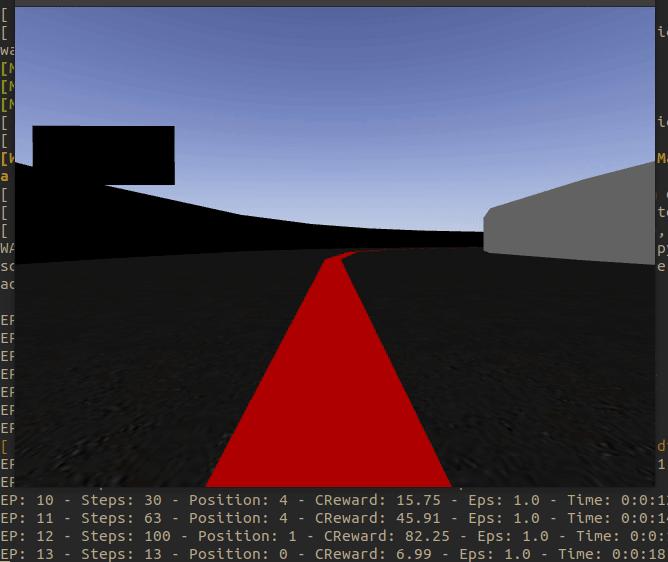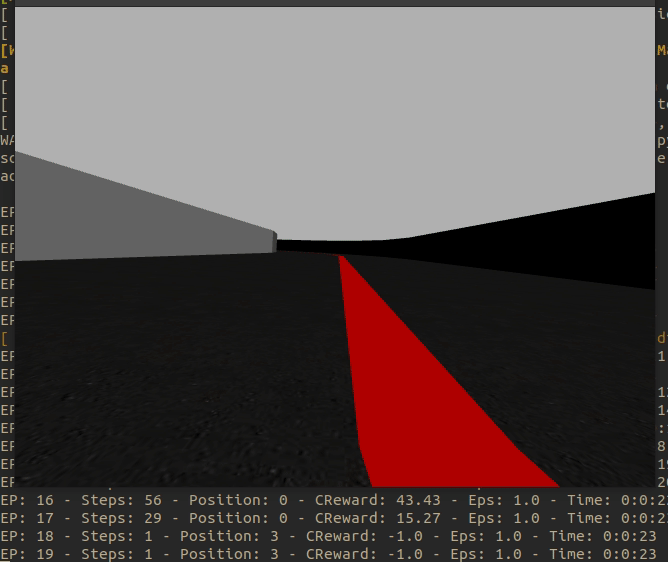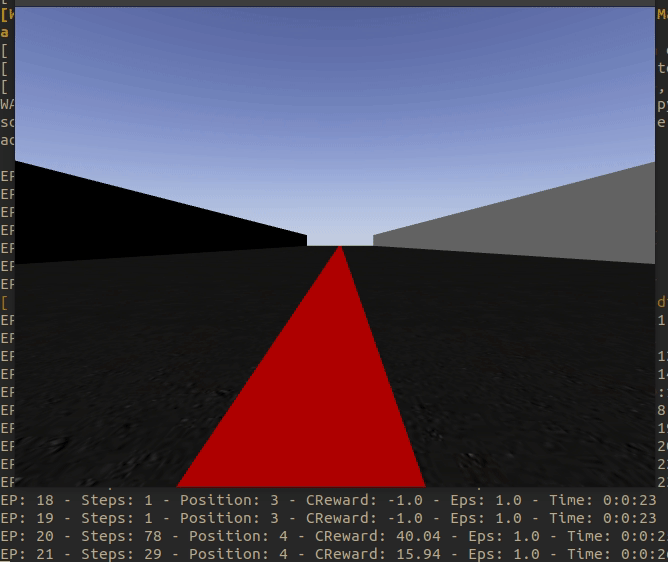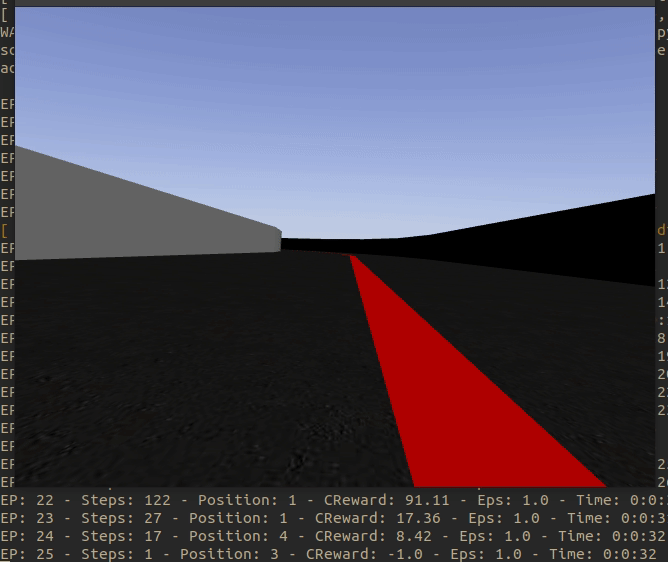
The collection of positions, for the moment, is as follows:
positions = [(0, 53.462, -41.988, 0.004, 0, 0, 1.57, -1.57),
(1, 53.462, -8.734, 0.004, 0, 0, 1.57, -1.57),
(2, 39.712, -30.741, 0.004, 0, 0, 1.56, 1.56),
(3, -7.894, -39.051, 0.004, 0, 0.01, -2.021, 2.021),
(4, 20.043, 37.130, 0.003, 0, 0.103, -1.4383, -1.4383)]
The code that jumps from one to another uses an ROS component called: ModelState. In the entry you have the value selected randomly from the list of positions and you fill in the position as you can see in the following fragment:
"""
(pos_number, pose_x, pose_y, pose_z, or_x, or_y, or_z, or_z)
"""
pos_number = positions[0]
state = ModelState()
state.model_name = "f1_renault"
state.pose.position.x = positions[new_pos][1]
state.pose.position.y = positions[new_pos][2]
state.pose.position.z = positions[new_pos][3]
state.pose.orientation.x = positions[new_pos][4]
state.pose.orientation.y = positions[new_pos][5]
state.pose.orientation.z = positions[new_pos][6]
state.pose.orientation.w = positions[new_pos][7]
rospy.wait_for_service('/gazebo/set_model_state')
try:
set_state = rospy.ServiceProxy('/gazebo/set_model_state', SetModelState)
resp = set_state(state)
except rospy.ServiceException, e:
print("Service call failed: %s") % e
New action set
Again, the set of actions has been simplified to obtain training that is valid enough to try a broader set of actions.
We have moved to a set of only 5 actions in angular speed and only one in linear speed.
New training with the new configuration
The result of the training with the limited set of actions and with the jumps on the circuit has not gone well at all. You can see the result in the next gif.

Working
Review the set of actions and the evaluation of the reward to see if there are any mistakes that make the training go wrong to correct it.
Learning
As on other occasions, before moving on to the end point, it is necessary to simplify the cases and until these do not work well, do not move forward.