Week 7-8. Reading more documentation and small tutorials.
In these two weeks, given the amount of information I found, I decided to put into practice some simple tutorial to help me settle all the concepts and be able to relate them.
Small tutorial
The website that helps me is the one provided by learndatasci with a guided exercise for the taxi game.
To see if all the steps were correct, I have been replicating each step with the concepts in a Jupyter booklet that I have published in this repository.
This short tutorial explains how to make your first Reinforcement Learning algorithm using Q-Learning for a taxi (represented by a yellow cursor) to pick up and deliver passengers from specific locations. The goal is for it to do so through the shortest route by correctly picking up passengers at their stop and delivering them to the stop.
This algorithm has two tables, $Q_{table}$ and within it $Q_{values}$. The latter will be updated to remember the most beneficial action in the previous stage. The better $Q_{values}$ will have better opportunities to have better rewards. The $Q_{values}$ (arbitrarily initialized) will be updated using the following equation:
\[Q^{\prime}_{(state, action)} = (1 - \alpha) Q_{(s_t,a_t)} + \alpha [r(s_t, a_t) +\gamma \max_{\alpha}Q_{(s_{t+1},a_{t+1})}]\]where:
- $r$: is the reward.
- $\alpha$: is the learning rate ($0< \alpha \leq 1$)
- $\gamma$: Discount factor ($o < \gamma \leq 1$). Determine how important we want to be in future rewards. A high value (about 1) considers long term rewards and about 0 makes the agent consider the immediate recommendation, i.e. greedy.
The learned value is a combination of the rewards for taking the current value in the current state and the discounted maximum rewards of the next state we will be in once we take the current action.
To prevent the algorithm from learning a “fixed path” (overfitting) an Epsilon parameter ($\epsilon$) is introduced. It combines two states: the exploration and exploitation dilemma.
A low epsilon will occur in episodes with more penalties. This will be the case when the algorithm is exploring, since the parameter $\epsilon$ does not influence the agent. The result is as follows:

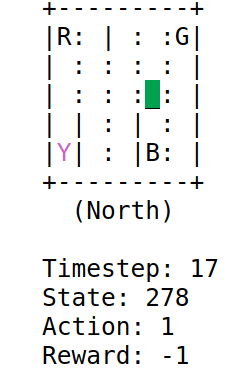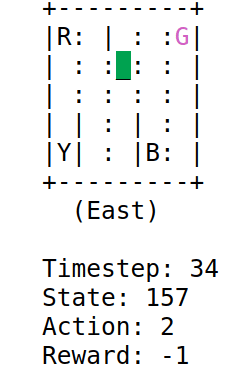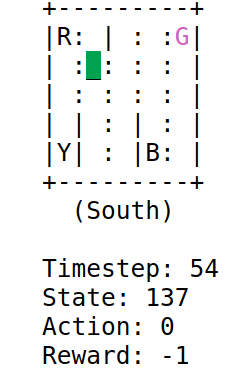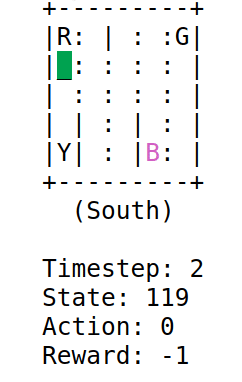
With this tutorial I understood how the $\epsilon$ parameter works in this field. The algorithm would act in certain cases just like humans. If something has gone well for me, why try different combinations? With this parameter the algorithm is being forced to explore other paths or to exploit the best path.
For more information visit the original article or the Jupyter notebook mentioned above.
Items read.
After this, I try to read other papers related to other types of Reinforcement Learning. These papers are as follows:
- Pong from pixels. The tutorial has been followed and analyzed in this Jupyter notebook.
- Playing CartPole through Asynchronous Advantage Actor Critic (A3C).
-
Google X’s Deep Reinforcement Learning in Robotics using Vision. Presents the Qt-Opt algorithm is designed by combining two methods:
-
Large-scale Distributed Optimization. Using multiple robots to train model faster, making it a large-scale distributed system.
-
Deep Q-learning algorithm. RL technique used to learn a policy, which tells an agent which action to take under which circumstances.
-