
Week 18 - Simplifying and gathering a lot of data
Simplification. That is the goal of our next task, by simplyfing the follow lane, we are going to build up the complexity of the problem. But first, we need to establish a good foundation for our next problems, and this foundation consist of a car capable of doing the same follow lane that it was possible on the 0.9.2 version of the Carla Simulation. One of the main changes resided on the possibility of using an already implemented autopilot instead of using our own (for now). The problem was that this autopilot was designed to randomly run around the roads of a given map, with this we are only adding very complex situations from the beginning such as intersections or junctions (that we need to take them into account, but not now).
So, to simplify the actual task that we are going to teach our car, we need to establish a simple route planner. Luckily, this is doable on our trustworthy Carla Simulation. By adjusting some parameters on the traffic manager on Carla, we can make our car decide to go straight when it encounters this complex road situations. The other problem we have lies on the Towns from which we are taking the data, the issue here is that we need to ensure that we find a route that doesn’t end in a junction, and we can always find a map with a suitable route for our purpose with the exception of Town04, because no matter the route taken in this map, it coincidentally always ends in a junction.
To avoid this and for the sake of simplyfing our task of gathering data for our dataset, we decided to change the training data recollection from the Town04 to the Town05, and use the Town01 and Town04 for testing purposes.
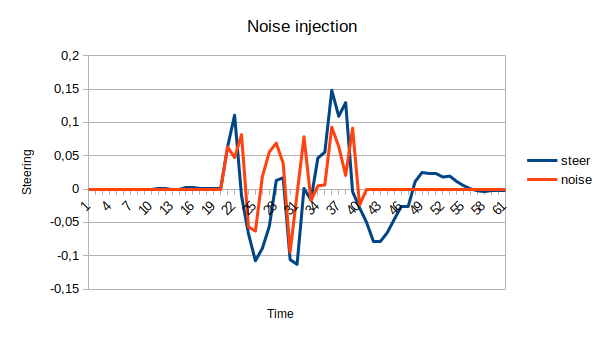
Along-side the recollection of a dataset, I stumbled myself with a pretty interesting paper that approached pretty similarly the same task that we are trying to solve right now, an end-to-end autonomous driving system using imitation learning. And the one thing that caught my eye on this work was how easily they approached the addition of weird scenarios, meaning, scenarios where the car veers from the desired behaviour. By simply doing some noise injection during the data collection. With this, we could try an easy way of adding some outliers to our dataset with the hope of a complete dataset for training.
In the next two images, we show a case of noise injection where it is possible to watch how the noise affects the car straight orientation and how it tries to go back to the expected position.
Increasing our dataset
By increasing the dataset, the aim is to improve the model we had up to now, in order to keep trying to make our car learn how to follow roads and take simple turns. By adopting the same thinking as we had before, we once again find ourselves increasing the data we already had, this time from the almost 47.000 images of turning events, we increased it to almost 80.000 images. Balancing our data and starting with the training part, we find that eventhough it is not the ideal result that we want to, we are on the right track. If we take a closer look to how the steering prediction performs when we compared them to the groundtruth, we can see a patern that correlates the two of them. This is a huge step forward knowing that before, when we increased the dataset, this graph didn’t showed us a discernible pattern that correlates the groundtruth and the prediction, only a random set of a scatter plot.
Weirdly I now find myself on the other side of the coin. Whereas in the previous weeks I was struggling to make the car turn correctly and not having any problem on the straights, this time (as it can be seen during the video) I have a car that is able to turn correctly but is not able keep itself on the road.