
Week 17 - Combating imbalanced data
As a continuation of our current task, we are going to keep trying to make our car follow straight roads and turn on the curves correctly. As a reminder, we already had this feature on the 0.9.2 version of the Carla Simulation, but by upgrading to the 0.9.13 (in order to be able to use more of the latest features and realistic driving physics) the whole model had a little stepback that needed to be revisited. The problem mainly resides on the fundamental changes made to the car physics of the new Carla simulator, with this changes, we needed to create a new model that could learn this behaviour in order to drive correctly on the simulation. So, to resume, we needed to recollect data from the new version for us to train a new model for the follow-lane task, once we had this data we process it so that the model could learn meaningful information, and finally test it to see the results.
First of all, we need a dataset. The dataset we are going to use, is the same as the one we used on the previous post. The only difference is that we increased the “weird” cases such us the turns or strange start positions (such as having the car slightly turned around the yaw) for it to know how to behave on this cases. This was done by doubling the quantity of this “weird” data, where once we had 22.135 images, we increase them to almost 47.000. Another main change we did to the dataset approach, was to not flip the images. This last idea was proposed to me from one of my advisors, and the idea behind it that by flipping the images, we could make the car be able to confront much more cases whether it is left or right turns. But because we are trying to imitate a realistic driving situation, the car would have no problem in changing lanes, whereas if we don’t flip the images, by sacrificing better capabilities to generalize, we are making the car stay on its lane.
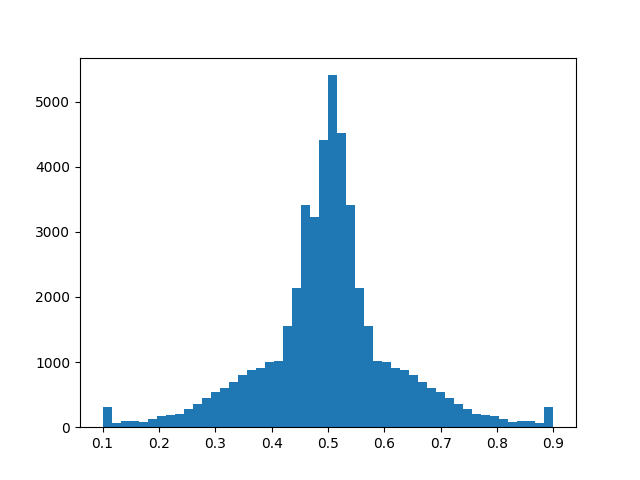
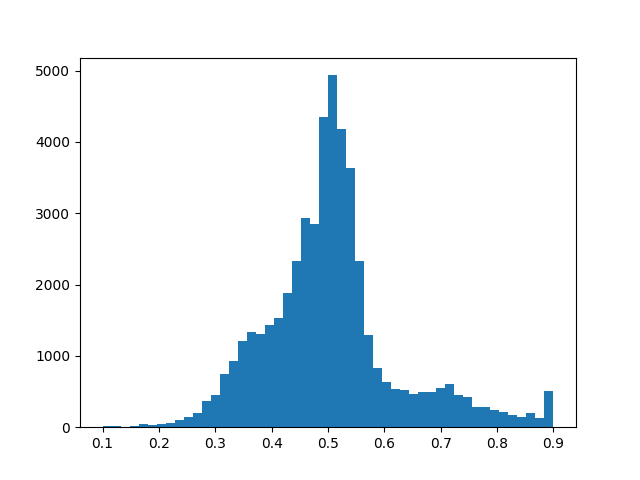
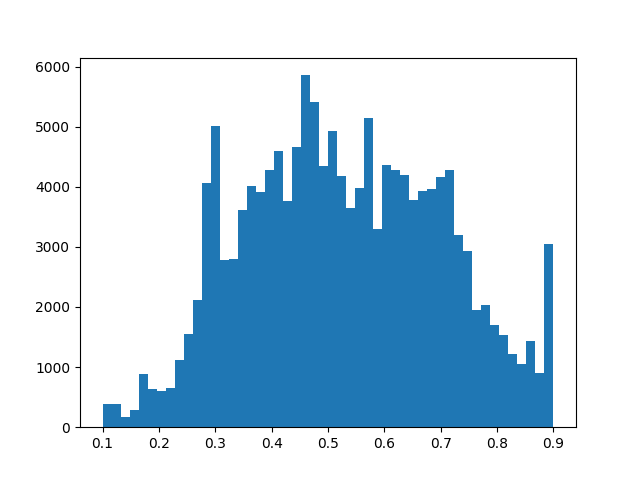
Then we put the model to train for 100 epochs, just to see the progress of the training and to try to analyze possible problems with it. One of the things we noticed was how well a good balanced dataset serves our purpose of decreasing the gap between the training set error and the validation set error.
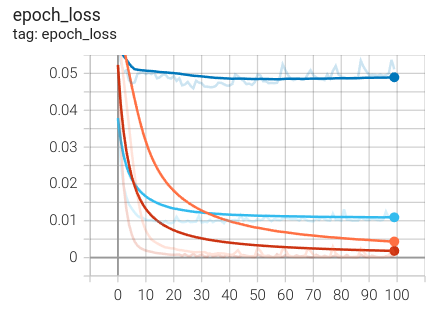
Other thing we noticed, is that by simply increasing the “weird” cases on our dataset wasn’t enough. The loss on our un-balanced validation set, follows almost the same pattern as the one we had on the previous week. Like we said, the main difference training-wise, was seen on the way we balance our data.
As we can see from the video, the car is able to follow a straight road but it cannot stay in one lane, given that it was a desirable quality for the car we need to further improve the way we train with this new dataset. Also, we seem to be stuck once again on the curve problem, it is not able to turn correctly, but as we saw from previous experiences, this problem is mainly resolved by increasing (even more) the quantity of turning events in our dataset, as well as the correct balancing of its values.