
Week 16 - The solution of every problem is another problem
And just as the problem of turning was fixed, I stumble my self into another problem, but nothing to be afraid of (yet). The simple task of moving from the 0.9.2 version of Carla to the 0.9.13, has proven to be quite a handful of problems given the fact that I am still not able to emulate the same behaviour as the old Carla version and its impressive ability to turn left and right, but to understand and keep trying to find a solution, let us first start from the beginning.
For this week we had to focus on a variety of tasks:
- Setting everything up for the new version of the Carla Simulator, such us, packages compatibility for us to keep using the same code used for the 0.9.2 version.
- To enrich our neural network adding the velocity on the training and prediction. Right now we are only using the steering values to learn the behaviour of the car.
- Learn and if possible, implement the Learning by Cheating paper onto our arquitecture. This should gives us a more robust training method but it requires a slightly different approach as the one taken up to now.
To deal with the first two tasks, we needed to collect a bunch of data from the new Carla version. This has to be done because one of the main differences with the new version and the old, as we mentioned on a previous post, resides on the refinement of the car physics. This alone is a feature that aimed to bring closer the simulation to the real world, so it basically changes completely how the car behaves on the simulator and therefore what it learns from it. So we needed to start the process of teaching a neural network from the beginning.
In order to gather our thoughts better, first we need to talk a little about the dataset and the different towns available to us from the 0.9.13 version of the Carla Simulator. The idea we came up with was to collect 30 minutes of autopilot data from the 2, 3 and 4 Town, leaving the Towns 1 and 5 for testing purposes.


The recollection gave us a total of 93.655 images for training and validation. The problem with using so much data, compared to the 32.674 on the previous version, is that the data balancing process as well as the training steps consume much more resources from our machine to the poin that it automatically kills the process for the lack of computation capability. But for the sake of coming with a solution, we go ahead and balance our data as shown in the next figure.
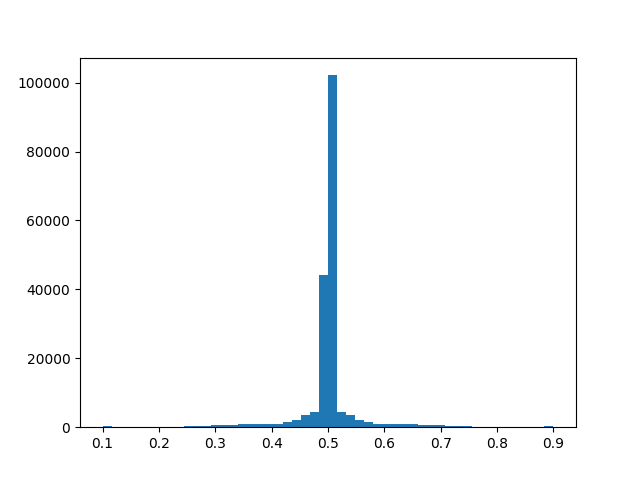
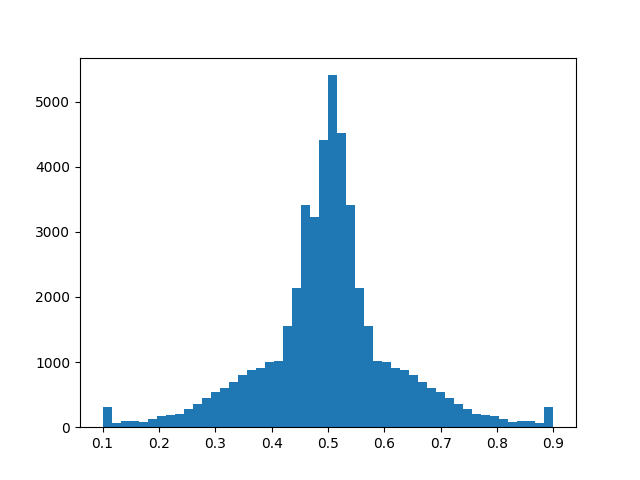
Once we have our data balanced we proceed like we did on previous cases, with training the model for the purpose of making the car follow the lane. To train the model, we go ahead and make it learn throught as many epochs as possible, so that we might be able to analyze if it is training correctly or not. One of the main changes done to the parameters, is the learning rate of the training process. We wanted to see how the model adjust its weights along this two different values.
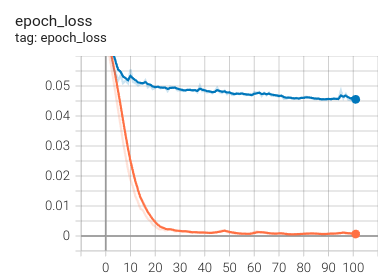
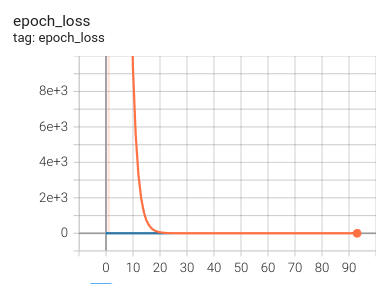
As we can see from the previous graph, the model is barely learning anything, while the training error (orange) is getting lower, the validation error (blue) is much higher. We might be overfitting our data, maybe because of the possibly wrongly balanced data. On the other hand, by increasing the learning rate, we observe a stabilized but similar error on the train and validation data. We could thing good of this training but then again, if we check the scatter plot of the predicted steering values compared to the groundtruth we found the next thing.
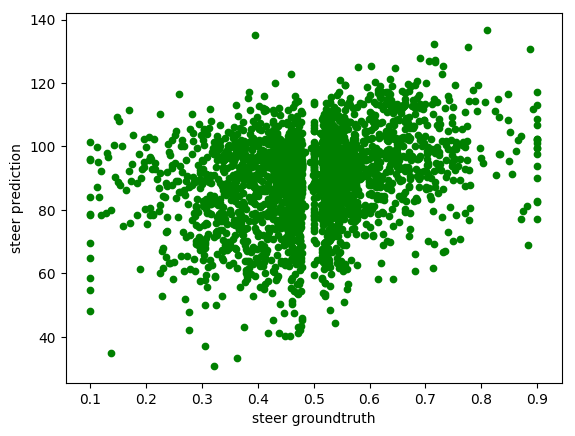
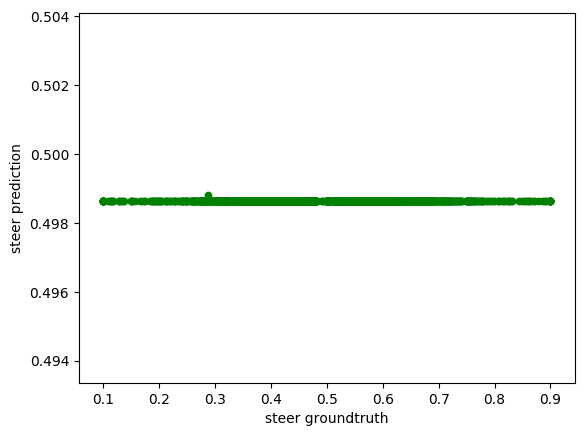
While the 0.0001 learning rate gives random prediction as we can see from its distribution (we cannot distinguish any pattern), the 0.01 shows us barely no correlation between the groundtruth and the prediction, proving that it didn’t learn the proper behaviour for steering values.
The fundamental problem with the actual setup of my machine, is that as we talked before, it kills the process before we can see if it is possible for the error to get any lower of it is going to stay the same forever. To try to fix this problem we may have been dragged a few steps back but we will always try to understand and make sense of the issues, finding a suitable solution. For example, one possible way around this, could be to lower the batch size for it to be more computationally friendly, or reduce even more the quantity of data used for training.
Bird-eye view training
As the third task, one of my master thesis advisor Sergio, showed me a pretty interesting and renowned paper called Learning by Cheating. And the premise of this was to make a much easier learning process by using a simple world representation such us the bird-eye view like the one we see in the next video.
It is also demostrated by the authors of the paper that this method makes a robust vision-based autonomous driving system, which we thought was worth a try, at least as a “second” priority task for the week. And as such, all the progress I made around this matter consists on reading and understanding the paper, and installing a pretty neat package called carla_birdeye_view made to take a 2D world representation (bird-eye view) from the Carla Simulator. With this package, I was able to easily collect a bird-eye data with the autopilot from Carla.