
Dataset de conducción autónoma
Esta semana hemos continuado con la generación de un dataset de conducción experta en el simulador Carla, con la finalidad de entrenar un futuro modelo. Para ello hemos generado un nuevo conjunto de datos de 9615 frames, en los que se han registrado simultáneamente las imágenes RGB de la cámara frontal del vehículo y los valores de los actuadores principales del vehículo: dirección (steer), acelerador (throttle) y freno (brake). Para este dataset se ha realizado una conducción teleoperada por teclado.
Captura y análisis de datos de sensores en entorno CARLA
Los datos fueron almacenados en un conjunto estructurado formado por: una carpeta de imágenes correspondientes a cada frame de la simulación y un fichero CSV asociado que contiene, para cada frame, los valores de los actuadores.
A partir de este dataset se ha procedido a realizar una visualización exploratoria de los datos, categorizando los valores de los actuadores en distintos intervalos o subcategorías. Esto ha permitido representar gráficamente el comportamiento de conducción, diferenciando situaciones de conducción recta, curvas suaves, giros pronunciados, aceleración y frenado, mediante la creación de diagrama de dispersión tridimensional. Para ello se ha usado: Pandas, para la manipulación de los datos y Plotly, para la generación interactiva de los scatter plots:
import plotly.graph_objects as go
import pandas as pd
# Cargar etiquetas
df = pd.read_csv("dataset4/dataset/labels.csv")
# Redondear valores para agrupar
df["steer_rounded"] = df["steer"].round(2)
df["throttle_rounded"] = df["throttle"].round(2)
# Contar muestras por cada par (steer, throttle)
counts = (
df.groupby(["steer_rounded", "throttle_rounded"])
.size()
.reset_index(name="count")
)
fig = go.Figure(data=[go.Scatter3d(
x=counts["steer_rounded"],
y=counts["throttle_rounded"],
z=counts["count"],
mode='markers',
marker=dict(
size=5,
color=counts["count"],
colorscale='Viridis',
opacity=0.8
)
)])
fig.update_layout(
scene=dict(
xaxis_title="Steer (-1 a 1)",
yaxis_title="Throttle (0 a 1)",
zaxis_title="Número de muestras"
),
title="Distribución de muestras (steer vs throttle)",
width=900,
height=700
)
fig.show()
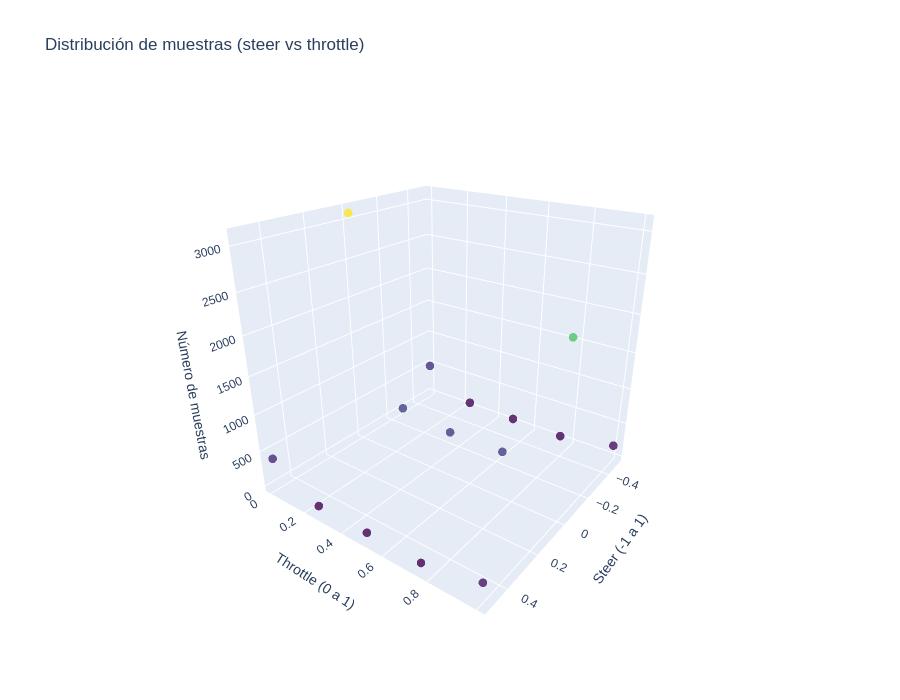
El análisis visual nos permite identificar la distribución real de las muestras, observándose una mayor concentración de datos correspondientes a tramos de conducción recta y baja variación en los actuadores, lo cual es puede ser coherente con un patrón de conducción humano natural.
Durante la preparación del dataset hemos considerado la necesidad de balancear las subcategorías de los actuadores, dado que algunas situaciones, como la conducción recta o baja aceleración, eran mucho más frecuentes que los giros pronunciados. Para ello se contempló: reducir el número de muestras de las subcategorías más representadas (undersampling), de manera que quedara un número aproximado de muestras similar para cada categoría; aumentar artificialmente las muestras de las subcategorías menos representadas (oversampling), mediante duplicación o generación de pequeñas variaciones de los datos; aplicar pesos durante el entrenamiento para que el modelo prestara más atención a las subcategorías minoritarias sin alterar el dataset original. Incialmente se optó por undersampling, aunque al reducir el número de muestras se podía estar descartar información relevante.
Implementación de piloto automático con LiDAR semántico
Se ha probado la implementación de un autopiloto basado en LiDAR semántico, creado por un compañero, donde los frames de la cámara frontal se generan en falso color a partir de la segmentación semántica del entorno, con tal de facilitar una percepción más estructurada del entorno. Se ha creado un conjunto de datos de 5953 frames.
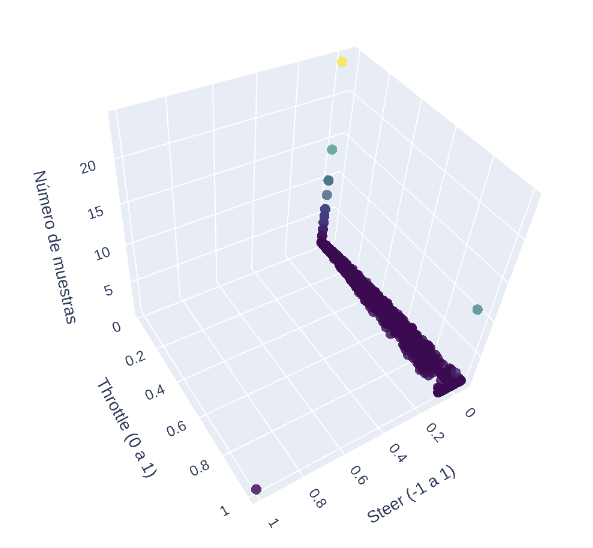
Al analizar los resultados, se ha detectado un error en la lectura de los actuadores, evidenciado por la homogeneidad excesiva de los valores de steer, que permanecen casi constantes independientemente de la situación del vehículo. Este comportamiento indica que que no se están recibiendo correctamente los datos de control correspondientes a cada frame (a solucionar).
Se puede visualizar, a continuación, un scatter plot tridimensional de los valores de steer y throttle, y el número de muestras para las distintas subcategorías:
Resumen
Se ha conseguido: generar y estructurar un dataset de conducción experta en CARLA. Además de visualizar y categorizar los datos de los actuadores, identificando las zonas más frecuentes de conducción recta y baja variación en los controles. Y finalmente, se ha probado un autopiloto con LiDAR semántico (creado por un compañero), detectando áreas de mejora en la sincronización y lectura de los actuadores.